CS231n Lecture 2 -2 발표 정리
아이펠 풀잎스쿨 - 발표 정리
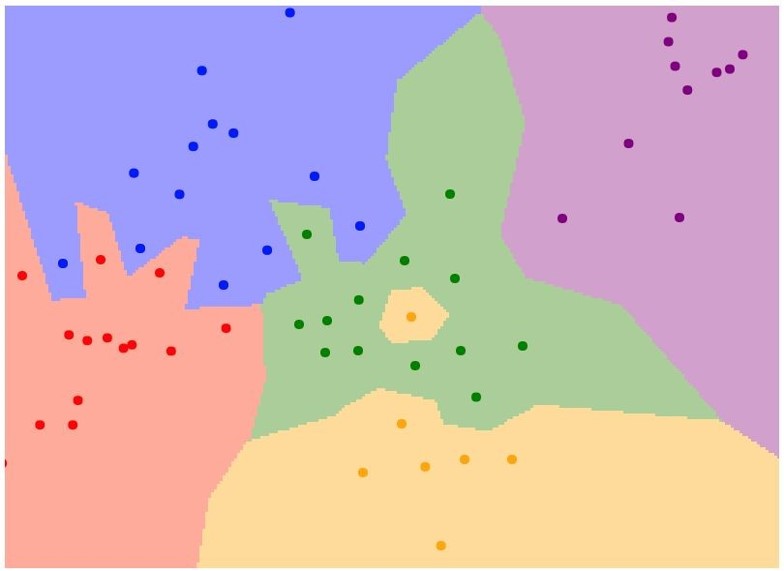
아래의 그림은 NN 알고리즘을 실제로 적용하여 NN의 decision regions를 그린 것이다.
-
점: 학습데이터
-
색: 각 타겟
-
이 2차원 평면이 나타나게 된 간략한 원리
: 2차원 평면 내의 모든 좌표에서 각 좌표가 어떤 학습 데이터와 가장 가까운지 계산하여 각 좌표를 해당 타겟으로 칠한 결과를 나타낸 것임 -
여기서 알 수 있는 NN분류기가 좋지 않은 이유?
-
초록색 영역에 노란색이 끼어있다.
-
파란색의 영역을 교묘하게 빨간색과 초록색이 침범하고 끼어들어 있다.
→노란색은 초록색이어야 했고, 파란색을 침범한 것들은 가짜이거나 noise일 것이다.
*노이즈란?
: 데이터로서 얻게 되는 Signal(신호) 내에서 배경에 존재하는 말그대로 잡음과 같은 불필요하고 지저분한 형체를 뜻함
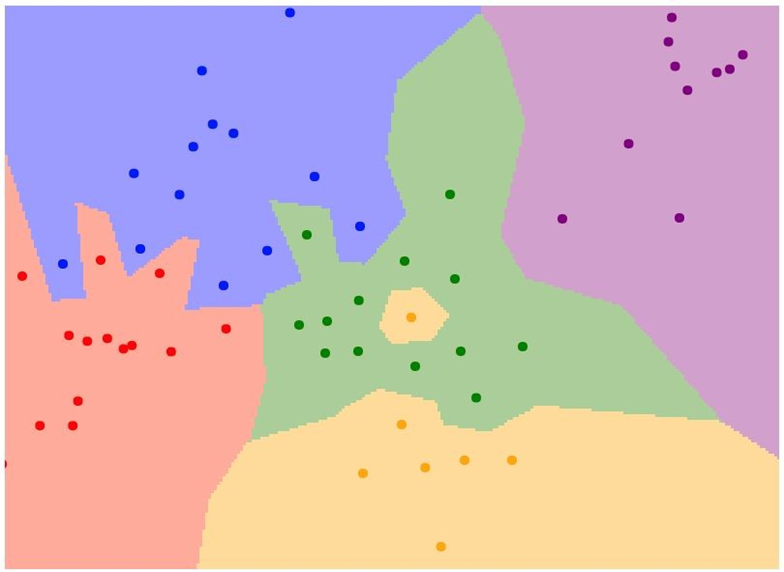
-
K-Nearest Neighbors
: NN보다 좀더 일반화된 버전
-
KNN의 원리
- distance metric 이용
- 가까운 이웃을 K개 찾음
- 이웃끼리 투표
- 가장 많은 득표를 얻은 타겟으로 예측
-
투표하는 방법

: 가장 잘 동작하면서도 가장 쉬운 방법은 득표수만 고려하는 방법이다.(분류)
: 이웃한 값들의 평균을 구해 타겟값으로 출력하는 것(회귀)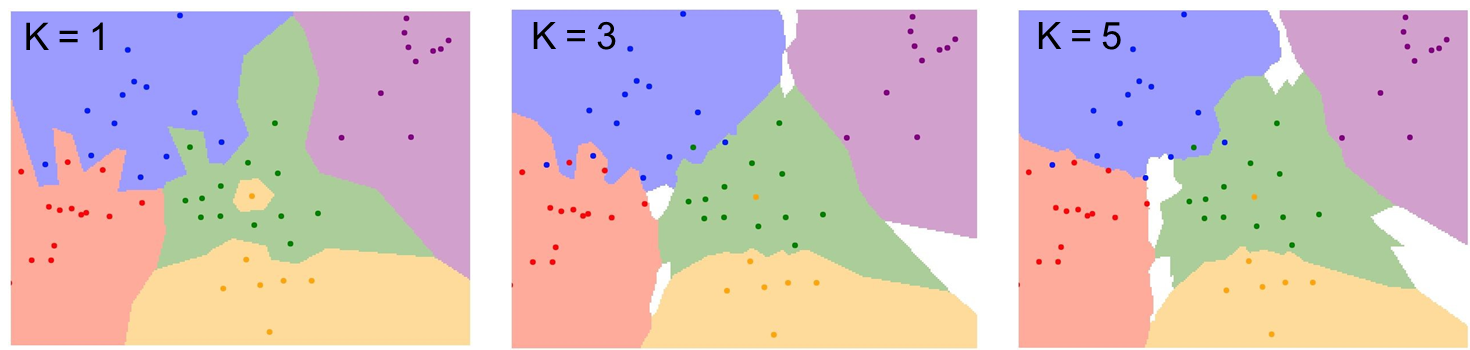 : 각 k값이 다르고 같은 데이터를 사용한 결과이다.
: 각 k값이 다르고 같은 데이터를 사용한 결과이다.
-
최근접 이웃을 몇 개를 뽑아내느냐에 따라 결과가 다르다.
-
1과 비교했을 때의 3의 경우
: 중앙의 노란 점이 사라졌다
: 빨강과 파랑의 경계 부분의 뾰족한 부분들이 점점 부드러워졌다. -
1보다 큰 수의 K를 사용하는 이유?
: k가 1보다 커야 여러 표본을 통해 투표의 경우의 수가 많아지고 그로인해 좀 더 신뢰성 있는 결과가 나와 결정 경계가 더 부드러워지고 우수한 결과를 보이기 때문이다. -
흰색으로 라벨링이 안 된 부분은 무엇인가?
: knn모델이 대다수를 결정할 수 없는 부분들이다.
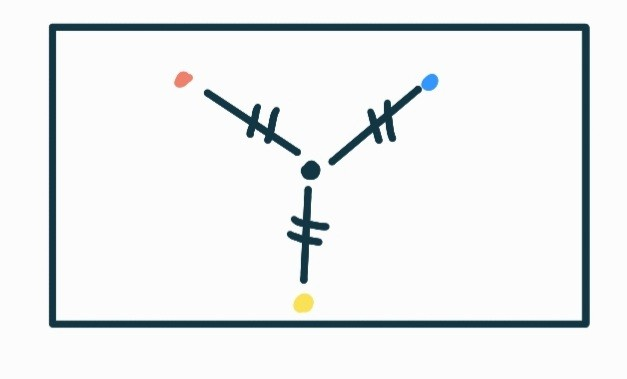
: 가까운 이웃이 존재하지 않거나, 존재하더라도 딱 하나를 짚어 어떤 타겟에 해당한다고 정하지 못하기 때문에 흰색으로 남는 것이다.
이미지를 다루는 것에서 k-nn을 사용하는 전략은 그닥 좋은 방법이 아니다.

빨강: 잘 분류되지 않은 것
초록: 잘 분류된 것
-
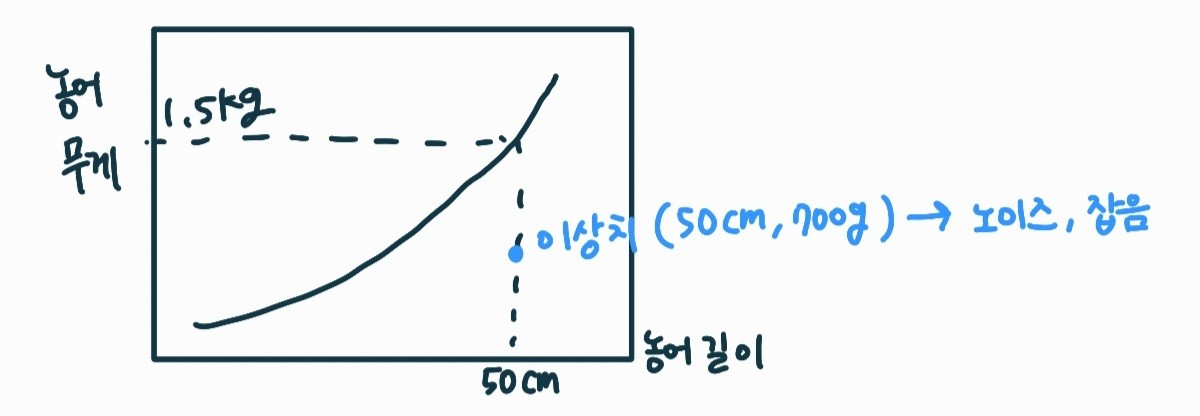
더 많은 이웃을 뽑아내어 투표해서 가장 근접한 것을 출력한다고 하면 어떨까?
: K 값을 보다 많은 값을 가지게 하면, 이상치에 대한 영향을 작게 하여 더 괜찮은 분류 결과를 도출해 낼 것이다.
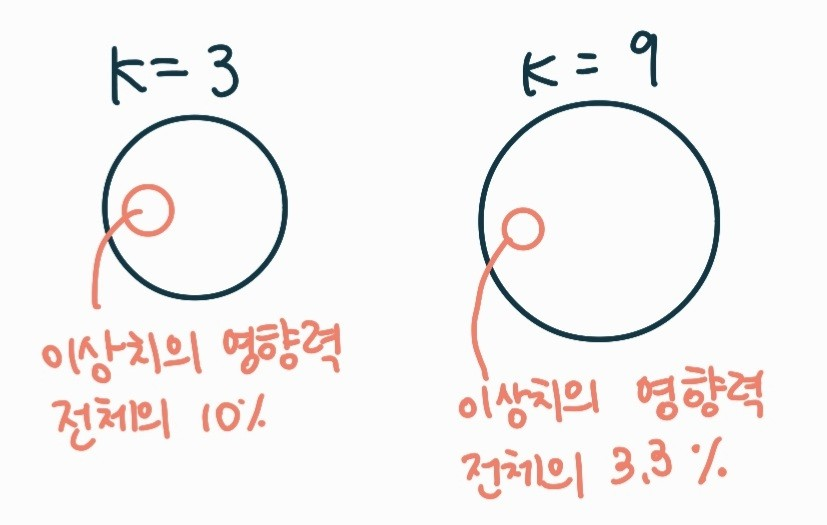
- 영어 자막 중, robust의 의미
: 이 로버스트라는 말을 회귀 분석에서 쓸 때는, 로버스트 회귀분석을 사용하여 이상값에 대한 영향을 최대한 덜 받게 했다. 라는 뜻이다.
- 영어 자막 중, robust의 의미
K-Nearest Neighbors: Distance Metric
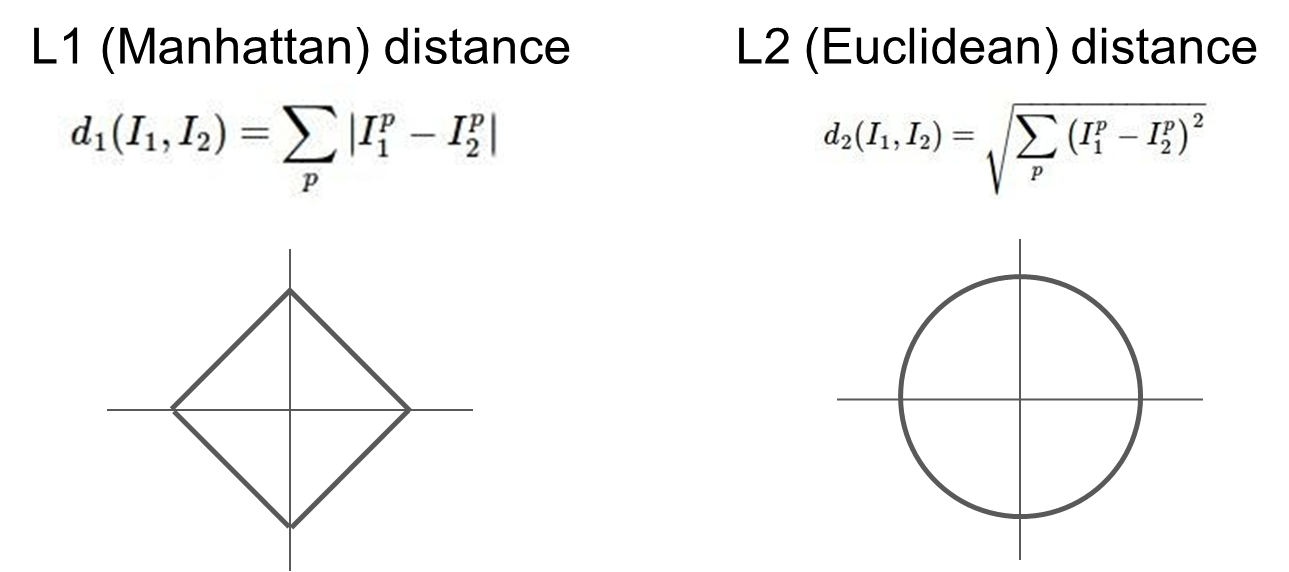
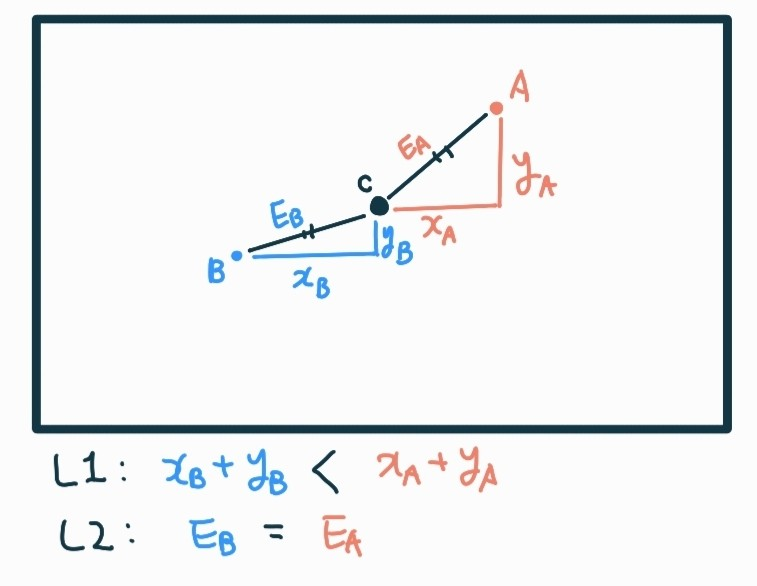
- L1 distance(=Mahattan distance)
: I1, I2 각각의 픽셀들을 뺀다음 절대값을 취하고 더한 구조이다.
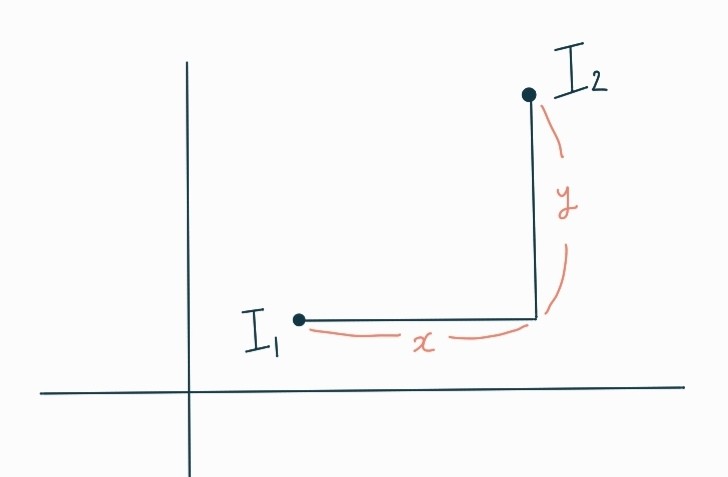
: 점과 점 사이의 거리를 x축에서의 거리와 y축에서의 거리를 더한 것이다.
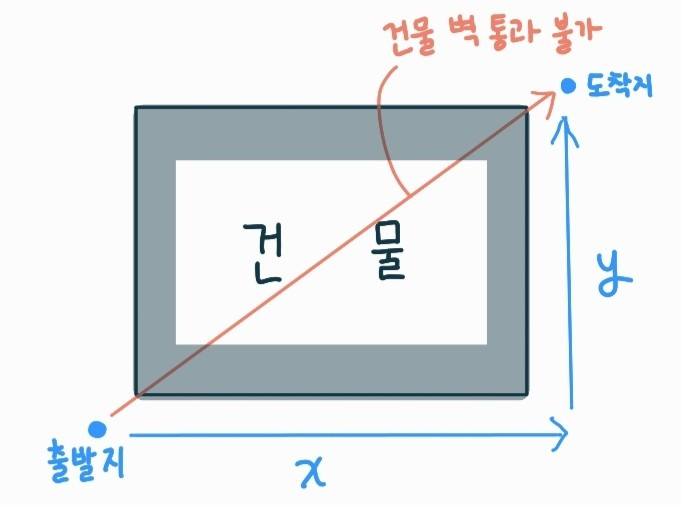
길을 갈때, 건물이나 호수를 가로질러서 못 가고, 건물 옆의 길이나 호수옆의 길을 따라 가면서 목적지에 도달할 수 있는 것처럼 I1과 I2 사이의 x축과 y축의 거리를 다 더한 총 이동길이를 말하는 것과 같은 원리이다.
- L2 distance(=Euclidean distance)
: 픽셀의 차이의 제곱을 다 더한 다음 루트를 취한 것.
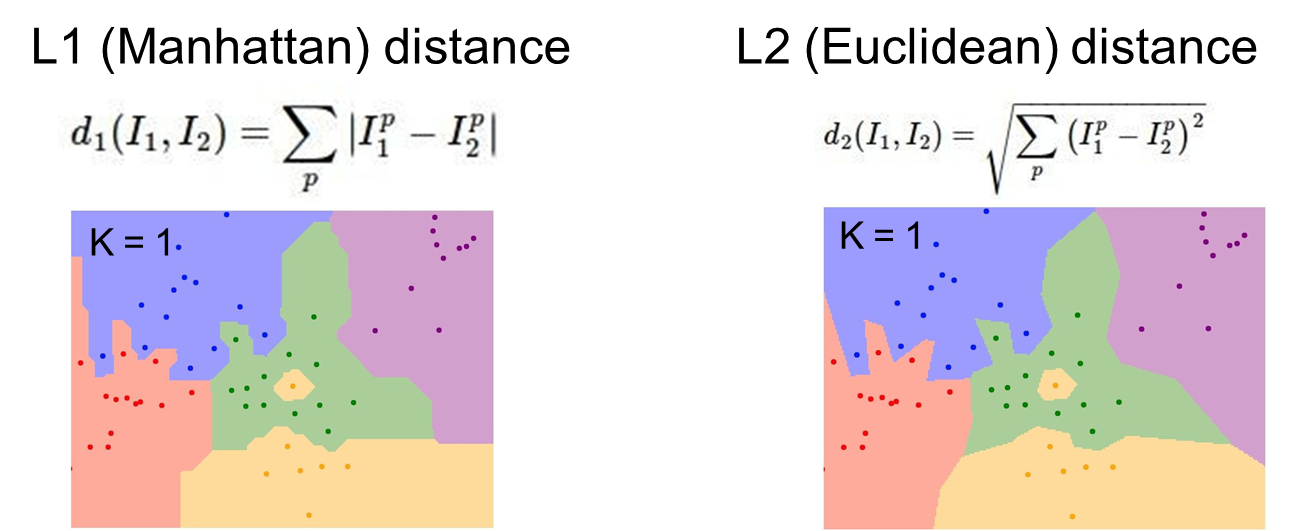
: 같은 데이터이지만 Distance Metric(거리 척도)을 어떤 것을 사용하느냐에 따라서 결과가 조금 다르다.
-
L1의 경우
: 좌표축과 평행한 직선들이 보인다.
→ x 좌표의 거리와 y 좌표의 거리를 더하는 것과 같이 좌표 축 자체에 영향을 많이 받기 때문이다. -
L2의 경우
: 결정 경계가 L1 보다 자연스럽다.
→좌표 축의 영향을 받지 않고 결정 경계를 만들기 때문이다.
L1, L2에 따른 차이 직접 알아보기
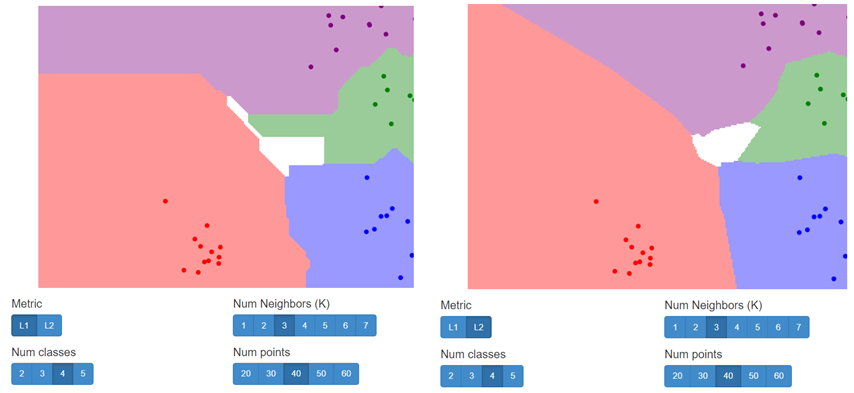
http://vision.stanford.edu/teaching/cs231n-demos/knn/
에서 Distance Metric를 선택할 수 있고, K값은 몇 개로 할 것인지, target 값은 몇 개로 할 것인지, 입력할 데이터 수는 몇 개인지 정하여 경우에 따른 결과를 확인해볼 수 있다.
- 다른 값들은 동일하게 설정하고, Distance Metric만 다르게 하여 결과를 살펴봤는데, 역시나 L1을 사용한 결과 보다 L2를 사용한 결과의 경계들이 부드러운 것을 알 수 있었다.
Hyperparameters
- 모델링할 때 사용자가 직접 세팅해주는 값
ex) k, distance metric, learning rate 등 - 하이퍼 파라미터는 해당하는 상황에 의존적이라 항상 최적의 값이 다르다.
Setting Hyperparameters
: 설계한 모델이 잘 작동 되는 지 어떻게 평가할까?
→ 모델을 돌려보고 나오는 정확도를 바탕으로 하이퍼 파라미터를 조정한다.
1. train data로 훈련/ 예측 하기

- 자기 자신에 대해서 훈련하고 예측하는 것이기 때문에 정확도가 100프로이다.
2. train/test set 나누고 훈련 뒤 예측하고 하이퍼 파라미터 찾기

-
훈련데이터로 훈련한 뒤에, 테스트 데이터를 사용해 예측해보고, 그 결과값을 테스트 데이터에 담긴 타겟값과 비교하여 정확도를 판단할 수 있다.
-
하지만, 테스트 데이터 셋을 가지고 가장 최상의 결과를 내는 하이퍼 파라미터를 찾아 입력한 것이기 때문에 테스트 데이터에 대해서만 잘 동작하게 될 것이고, 실전에서 모델을 사용하게 되면 성능이 상당히 낮아지게 될 것이다.
-
모델 학습의 목적은 한번도 보지 못한 데이터에서 잘 동작하는 것이기 때문에 테스트 데이터는 학습할 때 건들면 안 된다.
3. train/validation/test set 나누고 훈련 뒤 예측하기

-
하이퍼 파라미터를 구할 때는 validation데이터에 대한 결과를 보면서 조정한다.
-
validation 데이터로 모델의 하이퍼 파라미터가 알맞는지 확인한 뒤 알고리즘을 픽스시키고 테스트 데이터를 활용하여 외부 데이터에 대한 정확도를 알아본다.
-
검증 데이터까지 준비해서 학습 시켰지만 test 결과는 아마 좋지는 못 할 것이다.
→ validation 데이터를 한 구간으로 정한 뒤에 그 validation 데이터에 가장 알맞은 하이퍼파라미터를 찾아 알고리즘을 픽스 시킨 것이기 때문에, 당연히 테스트 결과가 어떤 경향을 띌지 모른다.
4. Cross validation
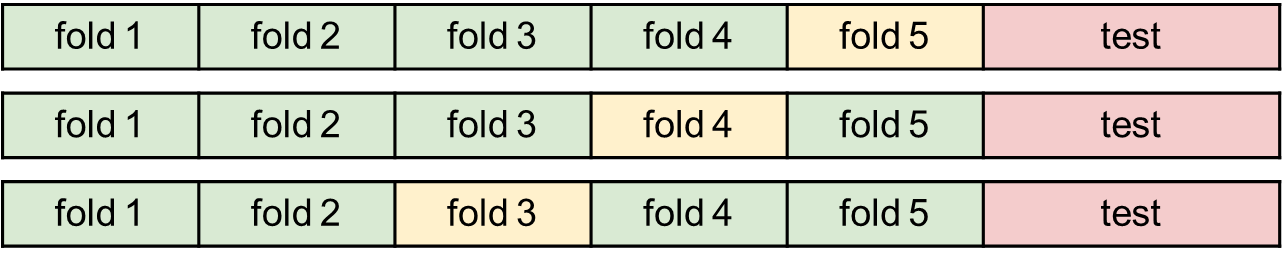
- cross validation의 원리
- train 데이터를 여러 구간으로 나누고, 그 구간 중 하나를 validation 데이터로 정해서 예측하고 하이퍼 파라미터를 찾는다.
- 또 다른 구간을 validation 데이터로 정해 예측하고 하이퍼 파라미터를 찾는다.
- 나눈 구간을 다 validation 데이터로 사용한다.
- 여러 validation 데이터들을 기반으로 최종 하이퍼 파라미터를 정해서 테스트 데이터를 돌려 결과를 얻는다.
- 단점
: 데이터 규모가 크면 한 번 돌리는데도 시간이 많이 걸리기 때문에 잘 사용할 수 없다.
