2. Application Layer
Layered Internet protocol stack (프로토콜 스택)
- application: 네트워크 어플리케이션을 지원함 → HTTP, IMAP, SMTP, DNS
- transport: 프로세스 간 데이터 전송 → TCP, UDP
- network: routing of datagrams from source to destination → IP, routing protocols
- link: 주변 네트워크 요소들 사이 데이터 전송 → Ethernet, 802.11(WiFi)
- physical: bits “ont the wire”
Encapsulation: an end-end view
Network application architecture
: 개발자가 설계하는 애플맄케이션이 다양한 종단 시스템에서 어떻게 조직되어야 하는지를 지시
-
클라이언트/서버 구조 (client-server architecture)
- server: 항상 켜져 있는 호스트, 고정 IP주소, 데이터 센터로 확장
- client: 서버와 통신, 클라이언트간 직접 통신하지 않음, 유동 IP가질 수 있음, 항상 연결되어 있지 않고 간헐적으로 통신할 수 있음.
-
P2P 구조 (peer to peer)
- 항상 켜져있는 서버가 없음
- 임의의 종단 시스템과 직접 통신
- 각 피어들이 각각 서비스를 요청하고 제공함. 높은 자기확장성(self-scalability), 새 피어가 새로운 서비스를 제공하고, 새 서비스를 요청
- 피어는 간헐적으로 연결되고 IP주소를 변경/관리가 어려움
→ 자기 확장성이란?
새로운 피어가 새로운 서비스 수용력을 제공함. 마치 새로운 서비스 수요처럼
-
프로세스 간 통신
- 호스트 내에서 두 프로세스는 OS에서 정의한 IPC(Inter-process communicaation)로 통신
- 다른 호스트 간의 프로세스들은 메시지를 교환해 통신
- 클라이언트는 두 프로세스 간의 통신 세션을 초기화(접속을 초기화)하는 프로세스
- 서버는 세션을 시작하기 위해 접속을 기다리는 프로세스
- P2P구조의 애플리케이션들은 클라이언트 프로세스와 서버 프로세스를 가짐
-
소켓 (Socket)
- 프로세스는 소켓을 통해 네트워크로 메시지 송수신
- 호스트의 애플리케이션 계층과 트랜스포트 계층 간의 인터페이스
- 프로세스는 집(house), 소켓은 출입구(door)
- 애플리케이션과 네트워크 사이의 API (Application Programming Interface)
- what transport service does an app need?
- Reliable data transfer (신뢰적 데이터 전송)
- Timing guarantee (시간 보장)
- throughput → bandwidth-senstive apps
- security → 데이터 무결성 등
- Securing TCP
- Vanilla TCP & UDP sockets: 보안 기능x
- Transport Layer SEcurity (TLS) → protocol
- TLS는 application 계층에서 구현됨
HTTP connections
- 비지속 연결 HTTP 1.0
- 요구/응답 쌍이 분리된 TCP연결을 통해 송수신
- 하나의 TCP 연결로 하나의 객체만 전송
- RTT (Round-Trip Time): 클라이언트에서 송신된 작은 패킷이 서버까지 간 후 다시 클라이언트로 되돌아오는데 걸리는 시간
- HTML파일 요청 응답 시간: TCP연결을 초기화하는 1RTT, HTTP 요청을 하고 HTT응답으로 처음 몇 바이트를 받는데 필요한 1RTT, 파일 전송 시간
- 각 객체 당 2RTT만 필요
- 각 TCP연결에 대한 os 오버헤드
- 브라우저는 참조 객체들을 가져오기 위해 종종 병렬 TCP연결을 시도
- 지속 연결 HTTP 1.1
- 모든 요구/응답 쌍이 같은 TCP 연결 상에서 송신함
- 다수의 객체들이 하나의 TCP 연결로 전송
- 서버는 응답을 보낸 후에 TCP 연결을 그대로 유지
- 클라이언트/서버 간의 이후 HTTP 메시지들은 같은 연결을 통해 송수신
- 클라이언트는 객체를 잠조하자마자 요청을 송신
- 모든 참조 객체들에 대한 1RTT만 필요
HTTP request message
→ request(human-readable format - ASCII), response
- request line: GET POST, HEAD commands
- header lines: host의 정보 및 연결 방식,
- data
→ header lines와 data 구분: “\r\n”56
HTTP
- status line (protocol status code status phrase)
- heder lines: 서버 정보, 마지막 수정 날짜, 현재 날짜 등
- data (requested HTML file)
Web cashes
→ 원래 웹 서버를 대신해 HTTP 요구를 충족 시켜주는 네트워크 개체
- 브라우저는 웹 캐시와 연결을 설정하고 웹 캐시에 HTTP 요청 전송, 없으면 웹캐시가 기점 서버에서 객체를 요청해 가져와서 클라이언트에 전송
- 클라이언트의 요청에 대한 응답 시간을 줄일 수 있음
- 인터넷으로의 기관 접속 회선 상의 웹 트래픽을 줄일 수 있음
- 콘텐츠 제공자가 저속도의 접속 회선을 가진 느린 서버에서 사이트를 운영하더라도 빠른 콘텐츠 분배를 위한 기반 구조 제공
→ user agents/mail servers/simple mail transfer protocol(SMTP)
- user agent: mail reader, 메시지를 읽고, 자성하고 보내고 전달, 송수신 메시지는 서버에 저장
- mail servers: mailbox(받은 메시지를 유지하고 관리), message queue of outgoing mail messages
- SMTP protocol between mail servers (메일 서버들 간의 통신 프로토콜)
- ex) → 지속연결, 클라이언트의 메일 메시지를 25번 포트의 TCP연결
- 이메일로 msg를 보냄
- SMTP를 통해 송신자 메일 서버에게 msg를 보냄; msg는 큐에 들어감
- SMTP의 client 측면에서 destination의 메일 서버에 TCP연결을 열어둠
- SMTP 클라이언트는 msg를 TCP 연결을 통해 전달
- 수신자의 메일 서버는 msg를 메일 서버의 mailbox에 둔다
- 수신자는 msg를 읽기 위해 그의 user agent를 부른다.
SMTP
→ HTTP와 비슷한 기능
- HTTP: client pull/ SMTP: client push
- 공통점: ASKII command, response interaction, status codes
- 차이점
-
HTTP: 각 object response 메시지 안에서 스스로 캡슐화
-
SMTP: 다중 객체는 multipart 메시지를 보냈다.
multipart: 웹 클라이언트가 요청을 보낼 때, http 프로토콜의 바디 부분에 데이터를 여러 부분으로 나눠서 보내는 것
-
- 지속적, 영구적 연결
- msg(header & body) 안에 7비트씩 msg 요구함
- SMTP서버는 CRLF 사용 (end of msg 결정)
POP3 (Post Office Protocol)
- 인증 (agent ↔ server)과 다운로드
- 다운로드 및 유지 모드를 사용해 여러 클라리언트에 메시직를 복사해야함
- POP3는 세션 간 상태를 유지하지 않은 (stateless)
IMAP (Internet Mail Access Protocol)
- 모든 메시지를 서버 한 장소에 보관
- 사용자가 메시지를 (원격) 폴더로 저장하고 구성 가능
- 세션 간에 사용자 상태 정보를 유지 (폴더의 이름과 어떤 메시지가 어떤 폴더와 연결되어 있는가를 유지)
DNS (Domain Name System)
-
DNS
- 호스트 네임을 IP 주소로 변환하는 디렉터리 서비스
- DNS 서버들이 계층구조로 구현된 분산 데이터 베이스 (distributed database)
- 호스트가 분산 데이터베이스로 질의하여 호스트 네임에서 IP 주소를 획득하는 애플리케이션 계층 프로토콜
-
DNS 서비스
- 호스트 에일리어싱 (ailasing)
- 간단한 별칭 호스트 네임을 복잡한 정식 호스트 네임으로 변환
- 메일 서버 에일리어싱
- 부하 분산: 여러 IP주소들이 하나의 정식 호스트 네임과 연관되는 중복 웹서버
- 중복 웹서버에서는 서버들이 부하 분산
- 단일 중앙 집중 방식 DNS를 사용하지 않는 이유
- 서버 고장 시 전체가 작동 하지 않음
- 트래픽의 양
- 먼 거리의 중앙 집중 데이터 베이스
- 유지 및 관리 어려움
- 호스트 에일리어싱 (ailasing)
-
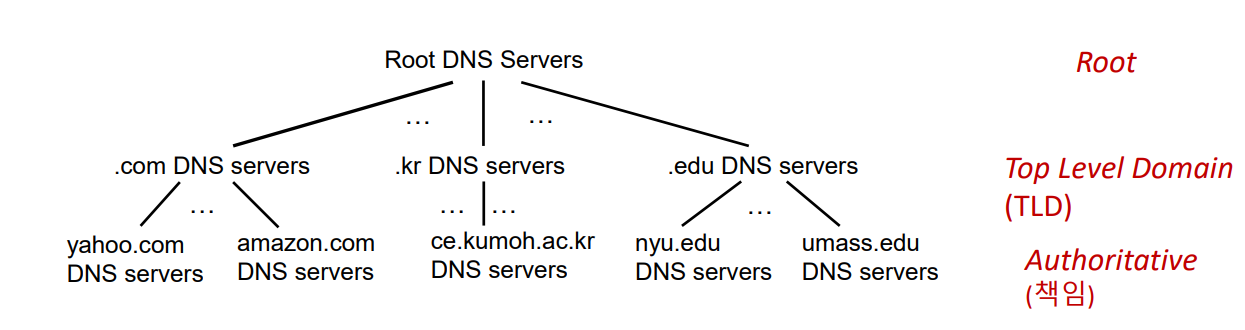
DNS 분산 계층 데이터베이스
- com의 DNS 서버를 찾기 위해 루트 서버에 질의
- 루트 DNS 서버: 질의된 호스트
- amazon.com의 DNS서버를 찾기 위해 com의 DNS서버 (TLD서버 - Top Level Domain: 상위 레벨 도메인과 국가 상위 레벨 도메인에 대한 책임, 기관 등의 서버의 호스트 네임의 IP 주소 매핑)
- www.amazon.com의 IP 주소를 얻기 위해 amazon.com의 DNS서버 (책임 서버, Authoritative server)에 질의
- com의 DNS 서버를 찾기 위해 루트 서버에 질의
- 로컬 DNS 서버
- 로컬 네임 서버는 DNS 계층에 속하지 않음
- 각 ISP (가정, 회사, 대학)는 로컬 DNS 서버를 가짐
- 디폴트 네임 서버 (Default Name Server)라고도 함
- host가 DNS 질의를 하면 로컬 DNS 서버로 질의가 전송
- 프록시와 같은 역할을 하며 질의를 계층으로 전달
- DNS 동작 → 차이점?
- 반복적 질의 (iterative query): 접촉된 서버가 연결할 서버의 주소로 응답
- 재귀적 질의 (recursive query): 이름에 대한 해결이 서버에 대한 부담, 상위 계층 서버에 많은 부담
- DNS 캐싱: DNS 서버가 어떤 이름에 대한 받은 응답 정보를 저장
- 캐싱된 정보는 일정 시간이 지나면 소멸
- 일반적으로 로컬 DNS 서버에 TLD 서버들이 캐싱, 따라서 루트 DNS 서버는 자주 방문 안 함
P2P 구조 (P2P Architecture)
-
순수한 P2P 구조(Pure P2P Architecture)
- 항상 켜져 있는 서버 없음
- 임의의 종단 시스템들이 직접 통신
- 피어들은 간헐적으로 연결되며 IP주소를 변경
-
파일 분배 시간
-
클라이언트-서버
- 서버 전송: 파일 복사본 N개를 피어들에게 순차적으로 전송
- 클라이언트: 각 클라이언트가 파일을 다운로드
→ 클라이언트-서버 방식으로 파일 F를 N 클라이언트에 분배하는 시간
Dcs ≥ max {NF/Us, F/dmin} → 피어수 N에 따라 선형적으로 증가
-
P2P
- 서버: 하나의 복사본만 전송
- 클라이언트: 각 클라이언트가 파일을 다운로드
- 클라이언트들: 시스템 전체 업로드 용량은 서버 업로드 속도와 각 피어 업로드 속도를 더한 것
Dcs ≥ max {F/Us, F/dmin,. NF/(Us + Σu)}
-
-
비트토렌트(BitTorrent)
- 토렌트에 가입(joining)하는 피어: 처음에는 청크(chunk)가 없지만 시간이 지남에 따라 청크들이 누적됨. 트래커로부터 피어들의 리스트를 얻어서, 이들 중 일부와 연결
- 청크를 다운로드하는 동안에 다른 피어들에게 업로드
- 전체 파일을 얻은 후 토렌트를 (이기적으로) 떠나거나 또는 (이타적으로) 남을 수 있음
- 청크 가져오기: 임의의 주어진 시간에 서로 다른 피어들이 파일의 서로 다른 청크들을 가지고 있음
- 주기적으로 한 피어는 이웃 피어들에게 각자 가지고 있는 청크의 리스트를 요청
- 이웃들이 가지고 있는 복사본 중 가장 드문 것은 먼저(rarest first) 요청
- 청크 보내기: 되갚음 (tit-for-tat)
- 현재 가장 속도가 빠른 4개의 이웃들에게 청크들을 보냄 (매 10초마다 가장 빠른 4개의 피어 다시 선택)
- 매 30초마다 임의로 하나의 피어를 추가 선택하여 청크를 보냄 (새롭게 선택된 피어가 가장 빠른 4개의 피어일 수 있음. 모든 이웃이 소외되지 않고 낙관적으로 중단 없는 전송(optimistically unchoke)
