1. 데이터 웨어하우스(Data Warehouse)란?
-
회사에 필요한 모든 데이터를 모아 둔 중앙 데이터베이스
-
회사의 크기가 작고 저장할 데이터의 양이 많지 않다면 프로덕션 데이터베이스를 사용해도 되지만 회사의 규모가 커짐에 따라 데이터의 양이 방대해질수록
OLTP로 데이터 웨어하우스를 사용할 수 없어진다. -
크기가 커진다면 다음과 같은
데이터베이스중 하나를 선택하게 된다.- AWS Redshift
- 구글 BigQuery
- 스노우플레이크 Snowflake
- 오픈 소스 기반의 하둡 (Hive/Presto) / 스팍
- 모두
SQL을 지원
-
중요한 포인트는 프로덕션용 데이터베이스와 별개의 데이터베이스여야 한다.
-
또한 데이터 웨어하우스 구축이 진정한 데이터 조직이 되는 첫 번째 단계이다.
2. 프로덕션 데이터베이스 vs 데이터 웨어하우스
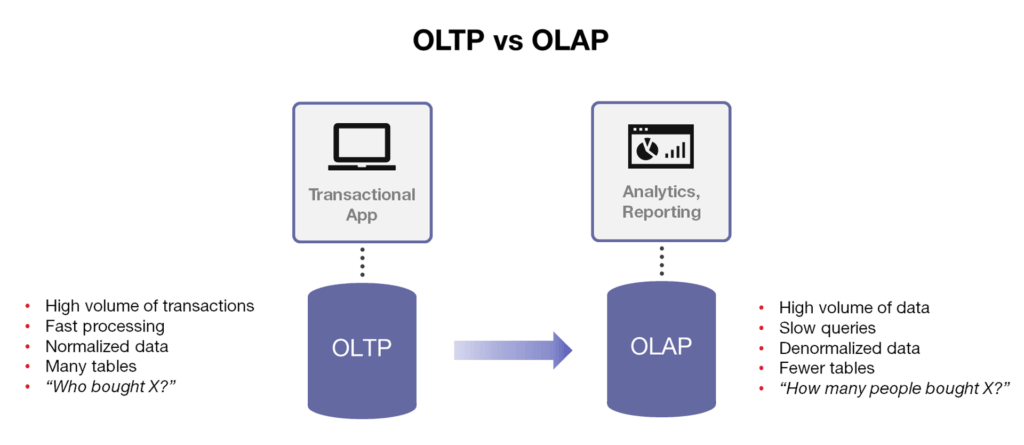
-
프로덕션 데이터베이스는
OLTP(Online Transaction Processing)을 사용한다. -
서버 한 대에 저장할 수 있는 데이터의 양 제한이 있다. 대신 속도가 가장 중요하다.
-
데이터 웨어하우스는
OLAP (Online Analytical Processing)을 사용한다. -
처리할 수 있는 데이터의 크기가 중요하다. 속도는 빠를 수록 좋지만 속도가 큰 영향을 주지 않는다.
3. 데이터 웨어하우스 옵션별 장단점
- 데이터 웨어하우스는 기본적으로 클라우드가 대세이다.
- 데이터가 작다면 굳이 빅데이터 기반 데이터베이스를 사용할 필요는 없다. (비용적인 측면 고려)
- 데이터가 커져도 문제가 없는 확장 가능성(Scalable)과 적정한 비용이 중요한 포인트가 된다.
1) 고정 비용 옵션: AWS RedShift
- 장점: 비용 관리가 가능하다.
- 단점: 내가 처리해야 하는 데이터가 내가 구입한 데이터보다 클 경우 확장할 수 없다.
오픈 소스 기반(Presto, Hive)을 사용하는 경우 클라우드 버전이 존재하고, 고정 비용 옵션에 가깝다.
2) 가변 비용 옵션: BigQuery, Snowflake
- 장점: 확장 가능하다. 그렇기 때문에 빅데이터를 다룰 때 더 효율적이다.
- 단점: 사용한 만큼 비용이 청구되기 때문에 비용의 관리가 어렵다.
4. 데이터 웨어하우스 옵션
- 해당 옵션의 공통점은
SQL기반의 빅데이터 데이터베이스 혹은 데이터 처리 엔진. 즉SQL을 쓰는 것이 일반적이다.
1) AWS Redshift

-
2012 년에 시작된
AWS기반의 데이터 웨어하우스로 PB 스케일 데이터 분산 처리 가능한 분산 데이터 처리 엔진이다. -
Postgresql와 호환된다. (모든 기능을 호환하지는 않지만 대부분의 기능 사용 가능) -
Python UDF(User Defined Function)작성을 통해 기능 확장이 가능하다. -
처음에는 고정 비용 모델로만 사용되었으나 이제
Redshift Serverless를 통해 가변 비용 모델도 지원한다. -
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원하고, bulk insert를 지원한다. (Avro, Parquet이 CSV, JSON보다 효율적)
-
AWS내의 서비스와 연동이 쉽다.S3,DynamoDB, ML 모델을 지원하기 위해 사용하는SageMaker, 또한 기능 확장을 위해Redshift Spectrum,AWS Athena등을 같이 사용한다. -
배치 데이터 중심이지만 실시간 데이터 처리도 지원한다.
-
웹 콘솔 이외에 API를 통한 관리와 제어도 가능하다.
2) Snowflake

-
2014 년에 클라우드 기반의 데이터 웨어하우스로 시작되었으며 데이터 판매를 통해 매출을 가능하게 해 주는 Data Sharing/Marketplace 기능을 처음부터 제공했다.
-
ETL과 다양한 데이터 통합 기능을 제공한다. -
SQL 기반으로 빅데이터 저장, 처리, 분석을 가능하게 해 준다. 하지만 UDF(User Defined Function)를 통해 비구조화된 데이터 처리와 머신 러닝 기능을 제공한다.
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원한다. (Avro, Parquet이 CSV, JSON보다 효율적)
-
S3, GC 클라우드 스토리지, Azure Blog Storage를 지원한다.
-
배치 데이터 중심이지만 실시간 데이터 처리도 지원한다.
-
웹 콘솔 이외에 API를 통한 관리와 제어도 가능하다.
3) Google Cloud Bigquery

-
2010 년에 시작된
구글 클라우드의 데이터 웨어하우스 서비스로 scalable한 데이터 웨어하우스 서비스이다. -
BigQuery SQL 기반으로 SQL 데이터 처리가 가능하며
Nested fields(field 안에 서브 field가 있고 또 서브 field 안에 서브 field가 있는 구조)와Repeated fields(list나 array 같은 구조)를 지원한다. 이를 통해 굉장히 복잡한 스키마도 처리할 수 있다. -
가변 비용과 고정 비용 옵션 지원한다.
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원한다. (Avro, Parquet이 CSV, JSON보다 효율적)
-
구글 클라우드내의 다른 서비스와 연동이 쉽다.클라우드 스토리지,데이터 플로우,AutoML등이 있다. -
배치 데이터 중심이지만 실시간 데이터 처리도 지원한다.
-
웹 콘솔 이외에 API를 통한 관리와 제어도 가능하다.
4) Apache Hive

-
Facebook이 2008 년에 시작한 Apache 오픈 소스 프로젝트이다. -
하둡 기반으로 동작하는 SQL 기반 데이터 웨어하우스 서비스이다.
-
HiveQL이라고 부르는 SQL을 지원하며MapReduce위에서 동작하는 버전과Apache Tez를 실행 엔진으로 동작하는 두 가지 버전이 존재한다. -
자바나 파이썬으로
UDF작성이 가능하다. -
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원한다.
-
배치 빅데이터 프로세싱 시스템이다.
-
빠른 처리 속도보다는 처리할 수 있는 데이터 양의 크기에 최적화되어 있다.
-
웹 UI와 CLI 두 가지를 지원한다.
-
최근에는
Spark가 대두되고 있어 다들Spark를 주로 사용한다.
5) Apache Presto

-
Facebook이 2013 년에 시작한 Apache 오픈 소스 프로젝트이다. -
다양한 데이터 소스에 존재하는 데이터를 대상으로
SQL실행 가능하다.- HDFS, S3, Cassandra, MySQL 등
- PrestoSQL이라고 부르는 SQL 지원
-
Hive와 문법이나 대부분 비슷하지만 처리 속도에 중점을 두어 메모리 중심으로 돌아가는 메모리 기반 배치 빅데이터 프로세싱 시스템이다. -
웹 UI와 CLI 두 가지를 지원한다.
-
AWS Athena가Presto를 기반으로 만들어졌다.
6) Apache Iceberg

-
Netflix가 시작한 2018 년에 시작한 Apache 오픈 소스 프로젝트로 데이터 웨어하우스 기술이 아니다. -
대용량 SCD (Slowly-Chjanging Datasets) 데이터를 다룰 수 있는 테이블 포맷
HDFS,S3,Azure Blob Storage등 클라우드 스토리지 지원- ACID 트랜잭션과 과거 버전으로 롤백과 변경 기록 유지가 가능
- 스키마 진화 지원을 통해 컬럼 제거와 추가 가능
-
자바와 파이썬 API 지원한다.
-
Spark, Flink, Hive, Hudi 등 다른 Apache 시스템과 연동 가능하다. (실제로 Iceberg와 Spark를 연동해 데이터 웨어하우스로 사용하기도 함)
7) Apache Spark

-
UC 버클리 AMPLab이 2013 년 시작한 Apache 오픈 소스 프로젝트로 Python의 Pandas처럼 빅데이터를 처리할 수 있도록 하자라는 목적을 가지고 시작되었다. -
그래서 데이터 처리를 Pandas와 흡사하게 DataFrame API를 써서 한다.
-
SQL로 빅데이터 처리를 가능하도록 해 주고, 실시간 처리, 그래프 처리, 머신 러닝 처리까지 가능해 빅데이터 처리 관련으로 많은 기능을 제공한다.
-
별도의 분산 처리 시스템을 가지고 있지 않고 다양한 분산 처리 시스템을 지원한다.
- 하둡 (YARN)
- AWS EMR
- Google Cloud Dataproc
- Mesos
- K8s
-
다양한 파일 시스템과 연동이 가능하다.
- HDFS
- S3
- Cassandra
- HBase
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원한다.
-
자바, 파이썬, 스칼라, R 다양한 언어를 지원한다.
