
📚 오늘 공부한 내용
1. Operators - PythonOperator
- 먼저
PythonOperator를 import 해 주어 사용할 수 있는 환경을 만들어 준다. - 태스크가 실행될 때
python_callable로 지정된 함수가 실행되게 되고 해당 함수에 파라미터를 넘겨 주고 싶다면params를 통해 전달하면 된다.
from airflow.operators.python import PythonOperator
load_nps = PythonOperator(
dag=dag,
task_id='task_id',
python_callable=python_func, #python_callable을 통해 python_func 호출
params={
'table': 'delighted_nps',
'schema': 'raw_data'
},
)
def python_func(**cxt):
table = cxt["params"]["table"]
schema = cxt["params"]["schema"] #넘겨 준 파라미터는 이렇게 받을 수 있음
ex_date = cxt["execution_date"] Test Decorator를 사용하게 되면 Python 함수를 바로 태스크나 Operator로 편하게 정의할 수 있다.
2. Airflow Decorators
- 프로그램이 단순해짐
- 각각 함수에
@task을 붙여 준다.
from airflow.decorators import task
@task
def print_hello():
print("hello!")
return "hello!"
@task
def print_goodbye():
print("goodbye!")
return "goodbye!"- 이렇게 붙여 주게 되면 저 함수들이 각각 태스크가 되게 된다. 그래서 대그를 다음과 같이 작성해 주면 된다.
print_hello() >> print_goodbye()- 또한 저 함수명이 태스크의 ID가 된다.
3. DAG에 지정할 수 있는 중요한 파라미터
- max_active_runs: 동시에 실행되는 DAG의 최대 수를 설정해 준다. (backfill에 효율적)
- max_active_tasks: 동시에 몇 개의 태스크가 실행 가능한지 설정한다. (병렬 구조에 의미가 생김)
->max_active_runs와max_active_tasks둘 다 아무리 큰 값을 지정해도 Airflow 워커에 있는 CPU의 총합이 max가 된다. DAG parameter와Task parameter의 차이점이 중요하다.
4. Connections, Variables
- Connections
- 함수에 중요한 정보들이 노출된 경우 사용할 수 있다.
- 이런 중요한 정보를 환경 설정 형태로 코드 밖으로 빼낼 수 있게 해 준다.
- Variables
- csv 링크를 PythonOperator 인자로 넘겨 줄 수 있긴 하지만 csv 파일의 위치가 바뀌면 코드가 바뀌어야 한다.
- 이를 airflow 환경 설정으로 가능하다.
- airflow 내에 어떤 key의 어떤 value를 세팅해 줄 수 있다.
- 또한 value를 암호화 상태로 보이도록 설정 가능하다.
-variables는 터미널에서도airflow variables list를 통해서 조회 가능하다.
- 또한 내용을 읽어오기 위해서airflow variables get variables명을 입력할 수 있고, 그 값을 설정해 줄 수도 있다.
Airflow Web UI로 확인 가능하다.
5. Xcom이란?
- 태스크(Operator) 간에 데이터를 주고받기 위한 방식이다.
- 예를 들어 태스크가 하나로 구성이 된 경우는 각 넘겨 줘야 하는 파라미터가 명확하다.
data = extract(link)
lines = transform(data)
load(lines)- 만약 태스크가 세 개로 나누어진다면 데이터를 넘기는 방식이 명확하지 않다. 그때
Xcom8이 사용된다.

- 보통 한 Operator의 리턴 값을 다른 Operator에서 읽어가는 형태가 된다.
- 내 앞에 실행된 Task의 ID를 주고 그Task의 Return 값을 다음 Task가 받게 된다.
- 이 값들이 Airflow 메타 데이터 DB에 저장되기 때문에. 하지만 그런 이유로 큰 데이터를 주고받을 때는 사용 불가하다. 보통 큰 데이터는 S3 등 값이 저렴한 스토리지에 로드하고 그 위치를 넘기는 게 일반적이다.
6. Redshift Connection 설정 (Data Warehouse)
- 만약
Connection변수를 만들어 주기 위해서는 설정을 해 주어야 한다. Admin->Connection을 선택해 주면 다음과 같은 창이 뜨게 된다.
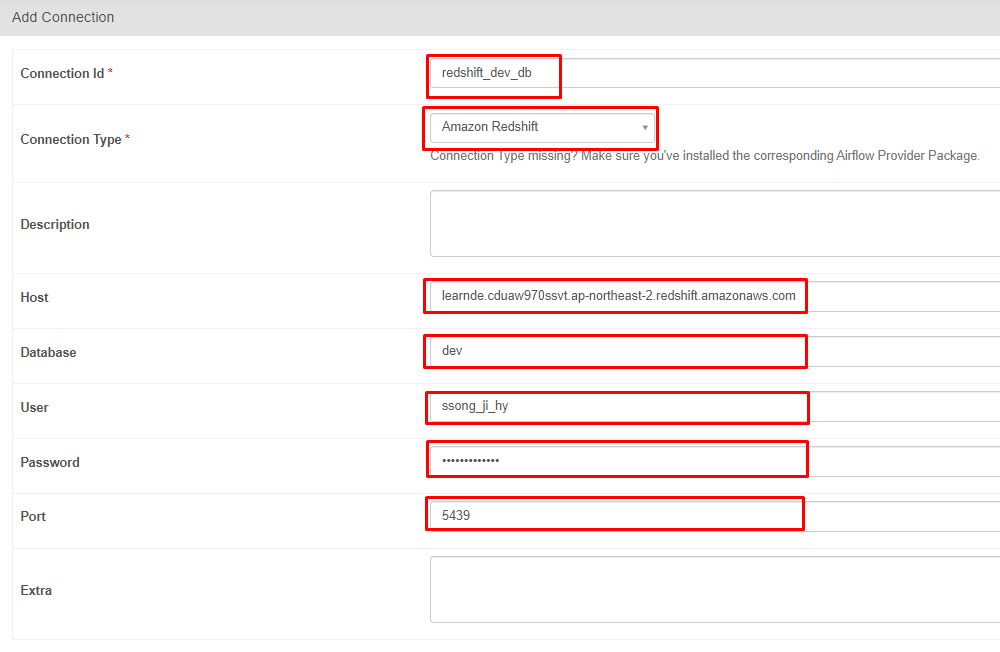
- 이렇게 각 항목을 추가해 주면 더 이상 Redshift 호출하는 부분을 코드에 추가할 필요 없이 이렇게 코드를 구현해 주면 된다.
from airflow.providers.postgres.hooks.postgres import PostgresHook
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()- 이때
autocommit은 default는 False이다. - False인 경우
BEGIN은 아무런 영향을 끼치지 않는다. True인 경우 자동으로commit을 적용한다.
7. 터미널에서 DAG 실행
docker ps: Container의 ID를 확인할 수 있다.Docker로그인 시 scheduler의 Container ID를 사용해 준다.docker exec -it scheduler_container_id sh:-it만 하면airflow의 기본 계정인airflow로 로그인 된다.docker exec --user root -it scheduler_container_id sh: 만약 root 계정으로 로그인 원할 시 다음과 같은 명령어를 입력해 준다.pip3 install module_name: 필요한 모듈이 있다면pip을 통해 설치해 준다.ls -tl: 폴더에 있는 목록을 확인할 수 있으며ls -tl Python_file_name을 통해 해당 DAG의 이름을 확인할 수 있다.airflow tasks list DAG_name: DAG에 존재하는 태스크를 확인할 수 있다.airflow dags test DAG_name 2023-05-30: DAG명과 날짜를 넘겨 주면 DAG를 실행해 볼 수 있다.
🔎 어려웠던 내용 & 새로 알게 된 내용
1. DAG parameter vs Task parameter
2. DAG에서 Task를 어느 정도 분리하는 것이 좋을까?
- Task를 많이 만들면 전체 DAG가 실행되는 데 너무 오래 걸리고 스케줄러에 부하가 간다.
- Task를 너무 적게 만들면 모듈화가 되지 않고 재실행의 시간이 오래 걸린다.
- Task의 수를 너무 늘리지는 않되 재실행의 이슈가 발생했을 때 어떻게 하면 재실행 시간을 줄일 수 있을지의 관점에서 고려해 보아야 한다.

3. Airflow Variable vs 코드 관리
- 장점: 코드 푸시의 필요성이 없다.
- 단점: 관리나 테스트가 안 되어서 사고로 이어질 가능성이 있다.
- 조금 번거로워도 코드 형태로 관리하게 되면 github에 코드가 기록이 될 것이고, 문제가 생기면 github History를 통해 방지할 수 있다.
- 만약 매우 중요한 코드라면 SQL이라면 Airflow Variable에 넣지는 않을 것이다.
4. TEMP TABLE
CREATE TEMP TABLE ... AS SELECT ...
CREATE TEMP TABLE을 설정해 주면 임시 테이블을 생성해 준다.- 임시 테이블이 꽤 유용하다고 생각했다. 임시 테이블로 먼저 데이터를 옮겨 준 후 문제가 없다면 테이블을 생성해 주어 그 테이블에 임시 테이블의 값을
INSERT해 주는 방식으로 실습에서는 사용되었는데 유용해 보였다.
📌 과제 - airflow.cfg
1. DAGs 폴더는 어디에 지정되는가?
- 지정해 주는 key가 존재. 그 key가 어디에 있는지를 찾을 것.
2. DAGs 폴더에 새로운 Dag를 만들면 언제 실제로 Airflow 시스템에서 이를 알게 되나? 이 스캔 주기를 결정해주는 키의 이름이 무엇인가?- Airflow가 바로 알지는 못하고 주기적으로 5 분마다 한 번씩 스캔을 한다. 그런데 그 5 분이 어디에 기록되어 있는지. 그 key가 무엇인지 알아볼 것.
3. 이 파일에서 Airflow를 API 형태로 외부에서 조작하고 싶다면 어느 섹션을 변경해야 하는가?
4. Variable에서 변수의 값이 encrypted가 되려면 변수의 이름에 어떤 단어들이 들어가야 하는데 이 단어들은 무엇일까?
5. 이 환경 설정 파일이 수정되었다면 이를 실제로 반영하기 위해서 해야 하는 일은?- 바로 바뀐 내용이 Airflow에 반영이 되는 것이 아니다. 어떤 명령을 해 주어야 그게 반영이 되는지.
6. Metadata DB의 내용을 암호화하는데 사용되는 키는 무엇인가?- 암호화하는 key는 airflow.cfg 내부에 있다. 그 key가 무엇인지 찾을 것.
📌 과제 - DAG 작성
https://restcountries.com/v3/all를 호출해 나라별로 다양한 정보를 얻을 수 있는 API가 존재한다.- 모든 국가의 정보를 매번 Full Refresh로 구현해서 정보를 읽어오게 할 것.
- API 결과에서 3 개의 정보를 추출해 Redshift 각자 스키마 밑에 테이블 생성되게 할 것.
- country: ["name"]["official"]
- population: ["population"]
- area: ["area"]
- 단 이 DAG를 UTC로 매주 토요일 오전 6 시 30 분에 실행되게 만들어 볼 것.
✍ 회고
- 과제를 하면서 DAG를 작성하는 방법에 대해 더 많이 배우게 되지 않을까 생각한다. airflow의 코드를 직접 구현해 보니까 어렵고 생각과 다른 부분들이 많아서 다양한 데이터를 통해 DAG를 설계해 봐야 되겠다고 생각했다. airflow는 주로 실습을 해야 하는 게 많아서 TIL에는 개념적인 내용만 넣어 두고 실습한 내용들을 git에 관리하기로 했다.

송의 개발 LOG