
📚 오늘 공부한 내용
1. Data Lake vs Data Warehouse

- 데이터 레이크 (Data Lake)
- 구조화 데이터 + 비구조화 데이터
- 보존 기한이 없는 모든 데이터를 원래 형태로 보존하는 스토리지에 가까움 (스토리지에 부담이 없기 때문에)
- 보통은 데이터 웨어하우스보다 몇 배는 더 큰 스토리지
- 데이터 웨어하우스 (Data Warehouse)
- 상대적으로 가격이 비싼 스토리지를 사용하기 때문에 온갖 종류의 데이터를 저장하기에는 비용적 제약이 있음
- 또한 비구조화 데이터를 저장하기에 어려움이 있음
- 그래서 조금 더 중요한 보존 기한이 있는 구조화된 데이터를 저장하고 처리하는 스토리지
- BI 툴들은 데이터 웨어하우스를 백엔드로 사용
- 보통 데이터 환경이 잘 갖추어진 경우 가지는 데이터 flow
Data Sources -> Data Lake (S3) -> Data Transforms (Spark, Athena) -> Data Warehouse, Data Mart
-> 이때 다양한 데이터 파이프라인의 스케줄러와 관리 툴이 필요한데 그때 쓰이는 것이Airflow
2. Data Pipeline란?
- 데이터를 소스로부터 목적지로 복사하는 작업으로 코딩 혹은 SQL을 통해 이루어진다. SQL의 경우 ELT, 이미 데이터 시스템에 있는 데이터를 정제하는 경우이다.
- 대부분의 경우 목적지는 데이터 웨어하우스가 된다.
- 어떤 경우에는 이 목적지가 외부 시스템이 되기도 한다.
- 데이터 소스 예
- Click stream, call data, ads performance data, transactions, sensor data, metadata, …
- More concrete examples: production databases, log files, API, stream data (Kafka topic)
- 데이터 목적지 예
- 데이터 웨어하우스, 캐시 시스템 (Redis, Memcache), 프로덕션 데이터베이스, NoSQL, S3, ...
- 대부분은 데이터 웨어하우스가 될 거임
3. Data Pipeline 종류
1) Raw Data ETL Jobs
- 보통 데이터 엔지니어가 수행한다.
- 외부와 내부에 있는 데이터 소스를 읽어서 데이터 웨어하우스로 로드하는 것을 말한다.
- 여기서 내부는 같은 회사 내에서 읽는 경우를 말하고 외부는 회사 밖에서 읽는 경우를 말한다. 예를 들어 FACEBOOK 광고로 유입되는 경우.
- 이때 데이터 포맷을 변환할 때 데이터 크기가 커지기 시작하면 Python 코드로만 정제할 수가 없어 Spark와 같은 빅데이터 프로세싱 프로그램을 사용한다.
2) Summary/Report Jobs
- 이미 DW나 DL에 있는 데이터를 INPUT으로 다시 새로운 데이터로 만들어서 DW이나 DL에 저장한다.
- 이런 경우는 리포트나 지표를 계산할 때 입력이 되는 사용하기 쉬운 정보를 만드는 용도이다.
- 특수한 목적을 가지는 데이터 파이프라인이 존재할 수 있다. (AB 테스트 결과 분석)
- SQL을 쓴다고 하면 보통 CTAS를 사용해서 할 수 있고, DBT와 같은 툴을 사용하기도 하며 이런 경우가 일반화되어 있다.
- 데이터 분석가들이 수행한다.
3) Production Data Jobs
- DW로부터 데이터를 읽어 다른 외부 Storage로 쓰는 ETL이다.
- 정보가 PRODUCTION 환경에 성능적으로 영향을 미치는 경우나 머신러닝 모델에서 필요한 피쳐들을 미리 계산해 두는 경우 사용한다.
- 이런 경우 사용되는 흔한 타깃 스토리지
- Cassandra/HBase/DynamoDB와 같은 NoSQL
- MySQL 같은 관계형 데이터베이스
- Redis/Memcache와 같은 캐시
- ElasticSearch 같은 검색 엔진
4. 데이터 파이프라인을 만들 때 고려해야 하는 점
1) Full Refresh vs Incremental Update
Full Refresh란 데이터가 작을 경우 가능하면 통으로 복사해서 테이블을 만드는 것을 말한다.- 과거 데이터가 잘못된 게 있어도 매번 다시 읽기 때문에 문제가 없고, 해결 방법이 간단해진다. 다시 새로 읽으면 되기 때문이다. 불필요한 Optimize를 줄일 수 있다.
- 어느 시점에서 데이터가 커지기 때문에 이게 불가능해지는 시점이 오면
Incremental Update를 한다. - 전날 새로 생긴(새로 업데이트된) 데이터만 적재하는 방법을
Incremental Update라고 한다. Incremental Update를 할 때 갖추어져야 하는 것은 created(timestamp), modified(timestamp), deleted(boolean) 필드가 필요하다.- 만약 데이터에 문제가 생기면 과거 모든 데이터를 가지고 와야 하기 때문에 코드를 수정해야 한다. 그래서
Incremental Update가 불필요한 경우Full Refresh를 하는 게 더 효율적이다.
2) 멱등성
- 멱등성(Idempotency)을 보장하는 것이 중요하다.
- 멱등성이란 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용은 달라지지 않아야 한다.
- 데이터 파이프라인이 만약 실패했다면 데이터 정합성이 깨지지 않도로 깔끔하게 실패해야 한다.
- 중요한 critical point들이 모두 one atomic action으로 실행되어야 한다.
3) Backfill
- 백필(Backfill)이 쉬워야 한다.
- 백필(Backfill)이란 과거 데이터를 다시 채우는 과정이다.
4) 데이터 파이프라인 입력, 출력 문서화
- 데이터 파이프라인이 많아지게 되면 이 데이터 파이프라인이 무슨 역할을 하는지도 알기 힘들어진다.
- 그래서 각 데이터 파이프라인의 입력과 출력, 그리고 비지니스 오너(이 데이터를 요청한 사람)를 기록으로 남겨야 한다.
5) 데이터 정리
- 주기적으로 쓸모없는 데이터를 삭제해야 한다.
- 각 파이프라인의 오너들에게 물어보거나 만약 데이터 디스커버리 툴이 있다면 최근 데이터가 작성되었는지 확인할 수 있다. 이를 통해 최근에 쓰이지 않는 데이터들을 확인하고 삭제한다.
6) 사고 리포트 (post-mortem)
- 데이터 파이프라인 사고마다 사고 리포트(post-mortem)을 써야 한다.
- 왜 이 사고가 났는지 이해하고 이 사고의 재발을 방지하기 위한 액션 아이템(action item)을 만드는 것을 말한다.
- 기술 부채의 정도를 이야기해 준다.
7) 데이터 대상 유닛 테스트
- 중요 데이터 파이프라인의 입력과 출력을 확인하는 것이다.
- 아주 간단하게 입력 레코드의 수와 출력 레코드의 수가 몇 개인지 확인하는 것부터 시작한다.
- 데이터 대상 유닛 테스트에서는 중복 레코드를 체크하거나, PK가 보장되는지 체크한다.
5. 실습 및 과제
6. Airflow
- 내용이 길어져 따로 포스팅 해 두었다.
📚 [Airflow] Airflow의 개념과 구성, 장단점
✔ 특강
One way door vs Two way door
- 조금은 위험해 보이는 일이 있다면 그걸 조금 더 안전하게 만들 방법을 찾기
- 나만의 의사 결정 원칙 만들기
- 길게 보면 모두 Two-way
건강한 피드백을 주는 방법
- 좋은 피드백이란 뭘까?
- 팀원과의 신뢰가 중요
- 팀원에 대한 관심이 중요
- 내 의견과 관찰에 기반
- 직접적인 피드백
- 피드백을 줄 때 절대 사용하지 말아야 하는 방법
- 장점과 단점을 번갈아가면서 이야기하는 샌드위치 기법 (안정을 주는 이야기를 하고 단점 이야기를 해야 함)
- 바디랭귀지로 불만을 표출하기
- 다른 사람의 의견 이야기 (내 의견을 이야기해야 함)
- 내가 무슨 이야기를 하려고 하는지 맞춰 보라고 하지 않기
- 건설적 피드백 주는 방법
- 기대와 관찰, 갭 그리고 그에 따른 개선 계획을 준다.
데이터 엔지니어링 미래
- Maxime Beauchemin: Apache Airflow와 Apache Superset 오픈 소스 시작
- Rise of Data Engineer (Maxime Beauchemin 블로그)
- Data Warehouse
- Performance tuning and optimization
- Data Intergration (ETL)
- Data related services
Stitch Data / Fivetran
- Stitch Data는 Simple, extensible ETL built for data teams
- 5 M 레코드를 복사하는데 월 100 불로 가격이 저렴한 편은 아니다
- 소스에 있는 데이터를 다 읽어서 적재하는 건 잘하지만 데이터가 커지면 원본 데이터의 특성을 파악해 새로운 데이터만 적재하는 형식이 잘 되지 않고 비효율적임
- 다양한 데이터 소스와 데이터 시스템 지원하지만 모든 데이터 타입을 지원하지 않음
- 이 둘은 데이터 엔지니어가 하는 일을 조력해 준다고 생각해야 한다
데이터 활용의 민주화/탈중앙화는 거스를 수 없는 트렌드
- 전사적인 데이터 문해력의 중요성
- 데이터 플랫폼의 셀프 서비스화 (인프라의 중요성)
- 데이터 활용을 위한 서비스 필요 (데이터 카탈로그 -> 데이터 디스커버리 서비스)
- 데이터 품질 모니터링의 중요성
- Data Observability, DataOps
데이터 엔지니어로 데이터 품질에 신경 쓰고 데이터 활용이란 측면에서 셀프 서비스화 다른 영역으로 기술과 경험을 확장하는 것이 중요하다.
DataOps
- Data Pipeline 모니터링 포인트들은?
- Data 이상은 다양한 카테고리를 포함
- 레코드 수 증감을 확인
- 통계 형태 변화 Data Drift
- NULL 값 필드는 무엇인가?
- PK가 지켜지는가?
- 중복 레코드 있는가?
- 스키마가 변경되었는가?
- Data + DevOps
- 아직 한국에는 있지 않지만 미국에는 직군으로 등장하기 시작함
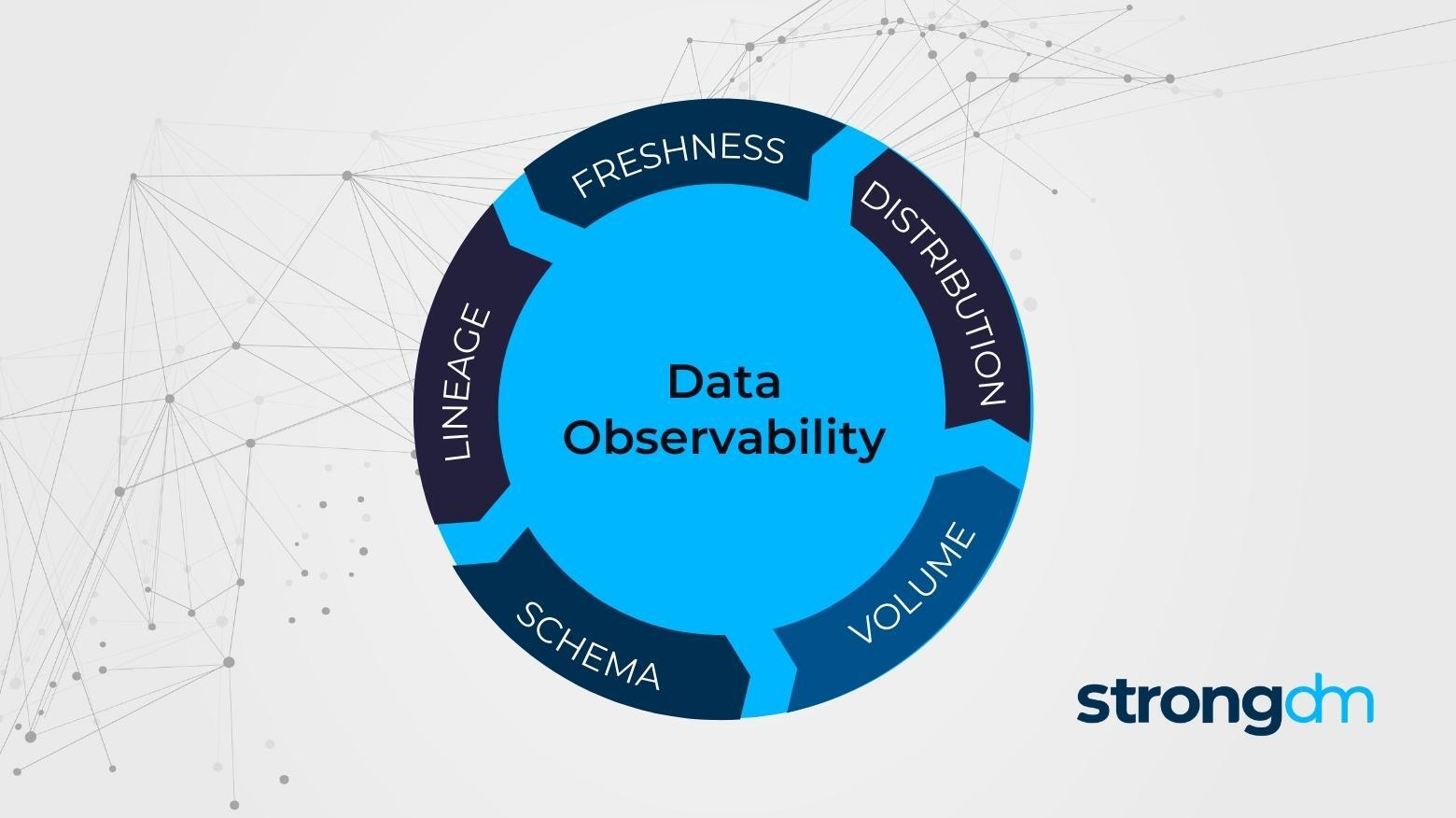
- 여기서 중요한 개념이 Data Observability이고, 이는 시스템 내의 데이터가 얼마나 fresh하고, 데이터의 품질이나 포맷은 어떤지, 데이터의 크기는 어떤지 등 해당 상황에 대해 깊이 있는 관찰을 통해 근본 원인을 파악할 수 있는 개념이다.
🔎 어려웠던 내용 & 새로 알게 된 내용
📘 과제 - 생성한 ETL의 문제 개선
- 먼저
NAME_GENDER라는 테이블에ETL을 통해 데이터를 적재한 후 다음과 같은 쿼리로 데이터를 조회해 보았다.SELECT GENDER , COUNT(1) GENDER_CNT FROM SSONG_JI_HY.NAME_GENDER GROUP BY 1
- 이때 두 가지 문제가 발생하게 되는데 이 문제를 개선하는 것이 과제였다.
❓ 문제 1
- GENDER 1의 경우 올바른 데이터가 아니라 헤더이다. 현재 헤더 역시 데이터로 읽혀 적재가 되었다. 이 문제를 어떻게 해결할 수 있을까?
🔑 해결 방법
- 인덱스 슬라이싱을 통해
Transform 과정에서 헤더의 경우 제외하고 리스트 처리가 이루어지게 해 준다.def transform(text): lines = text.strip().split("\n") records = [] for l in lines: (name, gender) = l.split(",") # l = "Jihye,F" -> [ 'Jihye', 'F' ] records.append([name, gender]) return records
- 이전의
transform코드가 다음과 같았다면 처음split시 아예 첫 번째 라인을 제외 처리되도록 해 주는 것이다.def transform(text): lines = text.strip().split("\n")[1:] records = [] for l in lines: (name, gender) = l.split(",") # l = "Jihye,F" -> [ 'Jihye', 'F' ] records.append([name, gender]) return records
- 이제 transform을 실행해 적재할 데이터에 헤더가 들어가지 않는지 확인해 보자.
lines = transform(data)
- 다음과 같이 헤더인 [NAME, GENDER]이 사라졌음을 알 수 있다.
❓ 문제 2
- 해당
ETL을 두 번 하게 되면 이전에 한 데이터가 삭제되지 않아 중복 데이터가 발생하게 된다. 이런 경우멱등성이 깨지게 되는데 이 문제는 어떻게 해결할 수 있을까?🔑 해결 방법
- 적재해 주는
Load 함수의 수정이 필요하다. 두 번 ETL 과정을 돌릴 시 중복 데이터 문제가 발생하는 오류 해결을 위해서DELETE쿼리문을 추가해 준다.- 이 과정을
Full refresh라고 부른다. 매번 전체 데이터를 새로 가지고 오는 것이다.- 다만 이런 경우
DELETE는 수행되고,INSERT는 수행되지 않는다거나DELETE가 수행되지 않고INSERT가 수행되면 데이터의 정합성이 깨지게 되므로SQL Transaction개념으로BEGINEND를 통해 각각의 쿼리가 하나의 플로우로 같이 돌아갈 수 있게 구현해 준다.- 이전 코드가 다음과 같았다면,
def load(records): # BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음 cur = get_Redshift_connection() # DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태 for r in records: name = r[0] gender = r[1] print(name, "-", gender) sql = "INSERT INTO SSONG_JI_HY.NAME_GENDER VALUES ('{n}', '{g}')".format(n=name, g=gender) cur.execute(sql)
- 각각 주석을 따라 추가적인 코드를 작성해 주도록 한다.
def load(records): schema = "SSONG_JI_HY" # BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음 cur = get_Redshift_connection() try: cur.execute("BEGIN;") cur.execute(f"DELETE FROM {schema}.name_gender;") # DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태 for r in records: name = r[0] gender = r[1] print(name, "-", gender) sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')" cur.execute(sql) cur.execute("COMMIT;") # cur.execute("END;") except (Exception, psycopg2.DatabaseError) as error: print(error) cur.execute("ROLLBACK;") #롤백을 하게 되면 BEGIN 이전의 상태로 돌아가며 BEGIN-END 사이의 변경들은 다른 쪽에서는 보이지 않는다 COMMIT이 완료되는 순간 물리적 테이블에 반영된다#변환 작업까지 끝낸 lines를 load(적재)해 줌 load(lines)%%sql SELECT GENDER , COUNT(1) GENDER_CNT FROM SSONG_JI_HY.NAME_GENDER GROUP BY 1
- 이제 다시 조회해 두 번 돌렸을 때 101 개의 데이터가 한 번 더 쌓이는 문제가 해결되었는지를 확인해 보자.
- 총 헤더 데이터 제외 100 개의 데이터가 다시 적재된 것을 볼 수 있고, 이전 데이터가 삭제되었음을 확인할 수 있다.
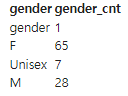

✍ 회고
- Airflow를 북스터디를 통해 일주일 정도 먼저 학습을 진행하고 있었다. 그래서 그런지 Airflow에 대한 개념은 어렵지 않았고 한 번 더 복습하는 느낌으로 쉽게 이해할 수 있었다. 얼른 파이프라인 하나를 구현해 보고 싶다.
- 예전에 일할 때는 배치 작업에서 주로 Transaction을 사용하였는데 배치나 ETL 자동화 작업이나 늘 데이터의 정합성이 중요하기 때문에 Transaction이라는 개념은 중요하고 개념뿐만 아니라 일을 하면서도 많이 활용될 것이라고 생각했다.

송의 개발 LOG