
📚 오늘 공부한 내용
1. GROUP BY, AGGREGATE 함수
- 테이블 레코드를 그룹핑해 그룹별로 다양한 정보를 계산하는 함수
- 먼저 그룹핑할 필드를
GROUP BY로 지정해 주고, 그룹별로 계산할 내용을 결정할 때AGGREGATE함수를 사용한다.
💻 실습
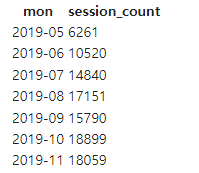
1) 월별 세션 수를 계산하는 SQL
SELECT LEFT(ts, 7) AS MON -- 시간을 문자열로 보고 7자리만 추출, ts는 시간 데이터이기 때문에 7자리를 추출한다는 것은 'yyyy-mm'을 추출한다는 것
, COUNT(1) AS SESSION_COUNT
FROM raw_data.session_timestamp
GROUP BY 1
ORDER BY 1; -- 1을 하면 default인 오름차순으로 (ASC)- 결과
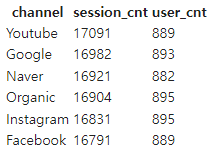
2) 가장 많이 사용된 채널 SQL
- 가장 많이 사용되었다는 정의가 무엇인지? 사용자 기반일 수도 있고, 세션 기반일 수도 있음.
- 필요한 정보가 무엇일까? 채널 정보, 사용자 정보 혹은 세션 정보.
- 먼저 어떤 테이블을 사용해야 할까?
- 사용자의 정보가 필요하다면
user_session_channel - 세션의 시간 정보가 필요하다면
session_timestamp(세션 정보는user_session_channel에도 존재하기 때문) - 아니면 둘을 JOIN 해야 하는가?
- 사용자의 정보가 필요하다면
- 가장 많이 사용
%%sql
SELECT CHANNEL
, COUNT(*) AS SESSION_CNT
, COUNT(DISTINCT USERID) AS USER_CNT
FROM RAW_DATA.USER_SESSION_CHANNEL
GROUP BY 1 -- ORDER BY나 GROUP BY 뒤에 숫자가 붙는 경우는 기준이 되는 컬럼을 정하기 위해서
ORDER BY 2 DESC; -- 지금과 같은 경우 CHANNEL로 그룹핑하고 CHANNEL COUNT를 기준으로 내림차순 정렬
-- 즉, GROUP BY CHANNEL ORDER BY SESSION_CNT DESC와 동일- 결과
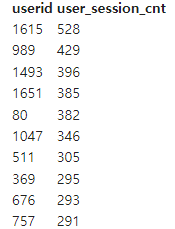
3) 가장 많은 세션을 만들어낸 사용자 ID SQL
SELECT USERID
, COUNT(*) USER_SESSION_CNT
FROM RAW_DATA.USER_SESSION_CHANNEL
GROUP BY 1
ORDER BY 2 DESC- 결과
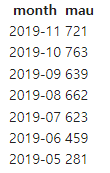
4) 월별 유니크한 사용자 수 (MAU-Monthly Active User) SQL
- 중복 없이 한 사용자는 한 번만 카운트 되어야 함.
- 필요한 정보는 무엇인가? 시간 정보, 사용자 정보.
- 어떤 테이블을 사용해야 하는가?
- 시간 정보와 사용자 정보가 모두 필요함으로user_session_channel,session_timestamp테이블을 둘 다 사용해야 함.- JOIN 기준은?
SESSIONID (PK)
- JOIN 기준은?
TS 컬럼(DATE 형식)에서년-월만 추출하는 방법 (차이가 없음)- TO_CHAR(TS, 'YYYY-MM')
- LEFT(TS, 7)
- DATE_TRUNC('MONTH', TS) =>
2019-11-01 00:00:00과 같은 출력이 나옴. 다른TIMESTAMP 타입이 유지되기 때문. 출력을 다른 경우와 같이YYYY-MM 형식으로 하고 싶다면 추가적인 가공 필요. - SUBSTRING(TS, 1, 7)
-- 내가 문제를 보고 짠 쿼리
SELECT TO_CHAR(S.TS, 'YYYY-MM') AS MONTH
, COUNT(DISTINCT U.USERID) AS MAU -- 같은 사용자는 월별로 몇 번을 방문했든 한 번만 카운트 하도록 처리
FROM RAW_DATA.USER_SESSION_CHANNEL U
, RAW_DATA.SESSION_TIMESTAMP S
WHERE U.SESSIONID = S.SESSIONID -- PK이자 접점인 SESSIONID를 기준으로 JOIN 해 줌
GROUP BY 1
ORDER BY 1 DESC;-- 강의에서 나온 쿼리
SELECT TO_CHAR(S.TS, 'YYYY-MM') AS MONTH
, COUNT(DISTINCT U.USERID) AS MAU
FROM RAW_DATA.SESSION_TIMESTAMP S
JOIN RAW_DATA.USER_SESSION_CHANNEL U -- INNER JOIN 양쪽에 공통적인 레코드들만 남기고 나머지는 조회되지 않도록
ON U.SESSIONID = S.SESSIONID
GROUP BY 1
ORDER BY 1 DESC;- 결과 (결과는 두 쿼리 모두 동일)
5) 월별 채널별 유니크한 사용자 수 SQL
- 4번과 동일하지만 채널별이기 때문에 채널을 그룹핑 조건에 추가해 주어야 함.
SELECT TO_CHAR(S.TS, 'YYYY-MM') AS MONTH
, U.CHANNEL
, COUNT(DISTINCT U.USERID) AS MAU
FROM RAW_DATA.SESSION_TIMESTAMP S
JOIN RAW_DATA.USER_SESSION_CHANNEL U
ON U.SESSIONID = S.SESSIONID
GROUP BY 1, 2
ORDER BY 1 DESC, 2;- 결과 (결과는 두 쿼리 모두 동일)

2. CTAS
SELECT를 가지고 테이블을 생성하는 방법- 자주 조인하는 테이블이 있다면
CTAS를 사용해서 조인해 두면 편하게 데이터를 조회할 수 있다.
-- 기존에 해당 테이블이 있었다면 DROP하여 테이블 삭제
DROP TABLE IF EXISTS ADHOC.SESSION_SUMMARY;
-- CTAS를 이용해 ADHOC 데이터베이스에 테이블 생성
CREATE TABLE ADHOC.SESSION_SUMMARY
AS SELECT B.*
, A.TS
FROM RAW_DATA.SESSION_TIMESTAMP A
JOIN RAW_DATA.USER_SESSION_CHANNEL B
ON A.SESSIONID = B.SESSIONID3. 데이터 품질 확인 방법
[SQL] 데이터 품질 확인
중요한 부분이라는 생각이 들어서 따로 포스팅 해 두었다.
🔎 어려웠던 내용 & 새로 알게 된 내용
1. GROUP BY (포지션 or 컬럼)
ORACLE에서는 GROUP BY COLUMN_NAME만 지원하였고, SELECT를 통해 노출이 되는 COLUMN_NAME이라면 모두 GROUP BY 조건절에 들어가야 했다. 그렇지 않으면ORA-00937: 단일 그룹의 그룹 함수가 아닙니다다음과 같은 오류가 발생했는데postgresql의 경우 원하는 컬럼만을 그룹핑 할 수 있으며 1, 2, 3 등 숫자를 통해 SELECT 할 컬럼들의 포지션만으로 그룹핑이 가능하였다.- 예를 들어, 월별 사용자를 조회하는 쿼리라고 하면
ORACLE에서는USERID를 GROUP BY절에 그룹핑 기준으로 넣어 주어야 한다.-- ORACLE SELECT TO_CHAR(S.TS, 'YYYY-MM') AS MONTH , COUNT(U.USERID) AS MAU FROM RAW_DATA.USER_SESSION_CHANNEL U , RAW_DATA.SESSION_TIMESTAMP S WHERE U.SESSIONID = S.SESSIONID GROUP BY S.TS, U.USERID
- 그렇지만
postgresql에서는MONTH라는 새로 만들어진 컬럼을 포지션을 통해GROUP BY해 줄 수 있다. 동일하게GROUP BY MONTH를 해 주어도 같은 결과가 나온다.-- 강의에서 나온 쿼리 SELECT TO_CHAR(S.TS, 'YYYY-MM') AS MONTH , COUNT(DISTINCT U.USERID) AS MAU FROM RAW_DATA.SESSION_TIMESTAMP S JOIN RAW_DATA.USER_SESSION_CHANNEL U ON U.SESSIONID = S.SESSIONID GROUP BY 1
📚 과제
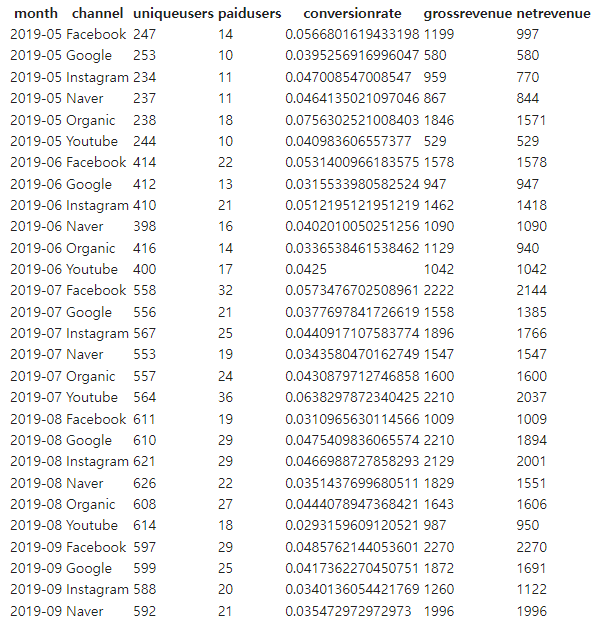
이 네 가지 테이블을 이용해서 채널별 월 매출액 테이블 만들기
Column
- month
- channel
- uniqueUsers (총 방문 사용자)
- paidUsers (구매 사용자: refund한 경우도 판매로 고려) - session_transaction에 존재하는 사용자
- conversionRate (구매 사용자/ 총 방문 사용자) - float 형식으로 소수점 단위가 나오도록 해야 함
- grossRevenue (Refund 포함) - amount 필드를 sum
- netRevenue (Refund 제외)
-- 내가 작성한 쿼리 SELECT TO_CHAR(B.TS, 'YYYY-MM') AS month , A.CHANNEL AS channel , COUNT(DISTINCT(CASE WHEN A.USERID IS NOT NULL THEN A.USERID END)) AS uniqueUsers --DISTINCT를 사용해 중복을 제거하면 NULL도 포함되므로 NULL인 경우는 COUNT 되지 않도록 제외 , COUNT(DISTINCT(CASE WHEN C.SESSIONID IS NOT NULL THEN C.SESSIONID END)) AS paidUsers , CONVERT(float, paidUsers) / CONVERT(float, uniqueUsers) conversionRate --convert를 사용하여 소수점 자리까지 계산되도록 , SUM(C.AMOUNT) AS grossRevenue , SUM(CASE WHEN C.REFUNDED THEN 0 ELSE C.AMOUNT END) AS netRevenue --refunded가 True면 환불받은 거라 카운트가 되지 않아야 함 FROM RAW_DATA.USER_SESSION_CHANNEL A , RAW_DATA.SESSION_TIMESTAMP B , RAW_DATA.SESSION_TRANSACTION C WHERE A.SESSIONID = B.SESSIONID (+) AND A.SESSIONID = C.SESSIONID (+) GROUP BY 1, 2 ORDER BY 1, 2만약
LEFT JOIN절을 사용한다면 다음과 같은 쿼리도 가능해 보인다.SELECT TO_CHAR(B.TS, 'YYYY-MM') AS month , A.CHANNEL AS channel , COUNT(DISTINCT(CASE WHEN A.USERID IS NOT NULL THEN A.USERID END)) AS uniqueUsers , COUNT(DISTINCT(CASE WHEN C.SESSIONID IS NOT NULL THEN C.SESSIONID END)) AS paidUsers , CONVERT(float, paidUsers) / CONVERT(float, uniqueUsers) conversionRate , SUM(C.AMOUNT) AS grossRevenue , SUM(CASE WHEN C.REFUNDED THEN 0 ELSE C.AMOUNT END) AS netRevenue FROM RAW_DATA.USER_SESSION_CHANNEL A LEFT JOIN RAW_DATA.SESSION_TIMESTAMP B ON A.SESSIONID = B.SESSIONID LEFT JOIN RAW_DATA.SESSION_TRANSACTION C ON A.SESSIONID = C.SESSIONID GROUP BY 1, 2 ORDER BY 1, 2
- 결과

✍ 회고
- 인터뷰를 할 때 일부러 질문을 모호하게 하는 이유는 이 부분을 짚고 넘어갈 수 있는지 없는지를 확인하려는 것이다. 항상 어떤 질문을 받았을 때 그냥 넘길 게 아니라 나한테 묻고자 하는 게 무엇인지 명확하게 좀 더 생각해 봐야 되겠다고 생각했다.
- 데이터를 다룸에 있어서 이 데이터가 적합한 것인지를 계속 의심하고 검증하려고 해야 한다. 어제 수업과 오늘 수업에서 한기용 강사님이 계속 강조했던 부분이다. 데이터를 다루는 데이터 엔지니어가 되기 위해서 가장 많이 기억해야 할 부분이라는 생각이 들었다.

송의 개발 LOG