
📚 오늘 공부한 내용
👊 팀 프로젝트
카테고리별 유튜브의 파급력 (조회 수, 좋아요 수, 구독자 수) 데이터 크롤링 및 시각화
1. 웹 페이지의 데이터 콘텐츠 정리 및 분석
- 각자 역할 분담을 하기로 하였다. 다들 데이터 분석 및 추출 작업을 하고 싶어해 각 카테고리를 나눠서 추출해 보기로 하였다. 내 카테고리였던
음악은k-pop 가수나pop 가수들이 조회 수의 주류를 이루었고 이를 유튜버라고 보기 어려울 것 같다는 생각에playlist와곡 해석위주의 유튜버들을 추출했는데 이를 선별하는 과정이 너무 주관적으로 바뀔 것 같아동물로 카테고리를 수정하였다. - 각자 어떤
그래프와 어떤wordCloud를 보여 줄지 정하기 위해 데이터들을 하루 동안 작업해 보고 다시 모여 회의를 할 때는 역할 분담 후 바로 개발에 들어가기로 하였다. 나는 데이터를 분석하기에 앞서 내가 생각한 콘텐츠를 다음과 같이 정리해 보았다.
🔎 내가 생각한 데이터 콘텐츠를 분석 전 정리해 보자
- 유튜브 채널별 구독자 수, 조회수 순위
- 채널별로
최근 100 개의 영상 조회 수 평균(꺾은 선)과구독자 수(막대)비교 ->꺾은 선 그래프로 하면 눈에 잘 보일 것 같음 (이건 조회 수 평균이 아니더라도 댓글 수나 좋아요 수로도 가능할 것 같다
꺾은 선 그래프범례 선택하면 선 보이게 하고 안 보이게 하는 기능 사용하면 어떨까 (비교에는 가장 좋은 것 같음)- 추출한 타이틀만 뽑아서 타이틀로
Word Cloud만들어 보기 일단은 조회 수로만 (유튜버별, 전체)- 각 유튜버의 ViewCount 상위 3-4개의 영상만 뽑아서 Url이랑 썸네일로 보여 주기 (만약 유튜버별 콘텐츠 추가하고 싶다면 좋을 듯)
2. 콘텐츠를 위한 데이터 추출, 시각화
- 1번의 경우 pandas를 이용해 리스트로 출력하고 각 그래프는 수업에서 배웠던
matplotlib과seaborn을 통해서 추출할 수 있었다. 그 과정에서 pandas를 통해 DataFrame으로 만들어 두면 seaborn으로 출력할 때 정렬을 조금 더 쉽게 할 수 있다는 것을 알게 되었다.
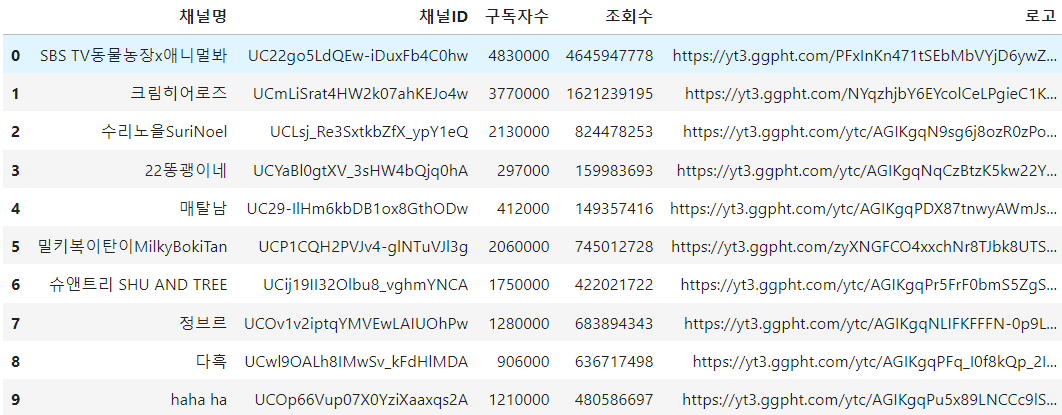
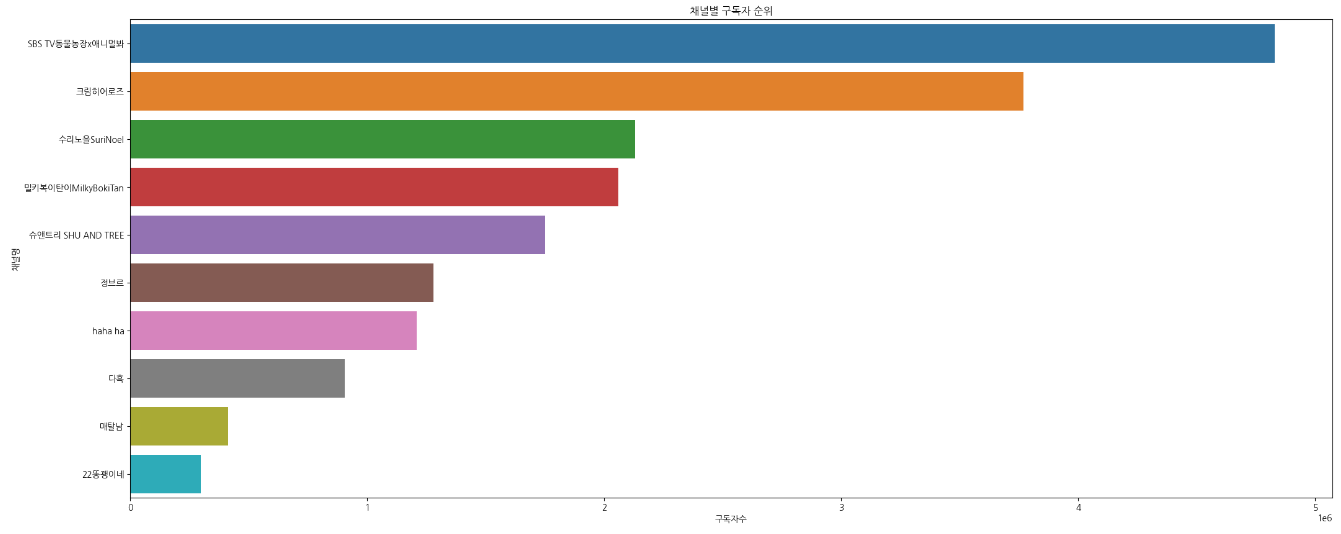
- YoutubeAPI의 크롤링의 어려움은
데이터 할당량을 초과하지 않고 어떻게 쓸 수 있을까인 것 같다. 매번 다시 조회를 해 오게 한다면 금방 할당량을 초과해 버리고 만다. 1 번으로 분석 시간이 끝났으나 1 번부터 4 번까지가 모두 들어간 화면이면 좋을 것 같다는 생각을 했다.
Youtube 채널 데이터 인기 순위 Pandas, Seaborn을 통한 시각화
3. 역할 분담
- 조원 중에서는 내가 생각했던 콘텐츠와 비슷하게 생각하여 2 번을 주로 작업한 사람이 있었고, 3 번을 주로 작업한 사람이 있어 이를 합친다면 좋은 프로젝트가 될 것 같다는 생각이 들었다.
- 역할을 크게 두 개로 나누게 되었다.
데이터 분석 및 가공, 적재와프론트 & 서버 구축으로 나누기로 하였다. 나는프론트 & 서버 구축을 맡게 되었는데 아마 서버가 주가 될 것 같다.
🔎 어려웠던 내용 & 새로 알게 된 내용
1. seaborn 그래프의 정렬
✍ 회고
일주일 동안의 TIL은 프로젝트에 내가 적용해 본 것들을 따로 포스트를 파고 해당 링크를 추가하고, 전체적으로 프로젝트 회의나 내가 프로젝트 과정을 겪으면서 느낀 회고 위주로 정리될 것 같다. 각자 카테고리를 정해 데이터를 분석하니 웹 화면을 어떻게 구성할지를 명확하게 생각할 수 있었다. 주로 구독자 수, 조회 수, 댓글 수를 이용한 데이터가 주가 될 것 같다. 우리가 배웠던 것을 최대한으로 활용하기 위해 Matplotlib을 통한 그래프 데이터, WordCloud를 이용한 키워드 데이터 그리고 Django를 통한 서버 구축을 할 예정이다.

송의 개발 LOG