✔ Oracle Background Process (필수)
오라클의 필수 백그라운드 프로세스는 오라클 서버가 시작되면서 함께 시작되고 오라클 서버가 종료되면 같이 종료된다.
필수 백그라운드 프로세스 중 하나가 죽게 되면 오라클 서버는 죽는다.
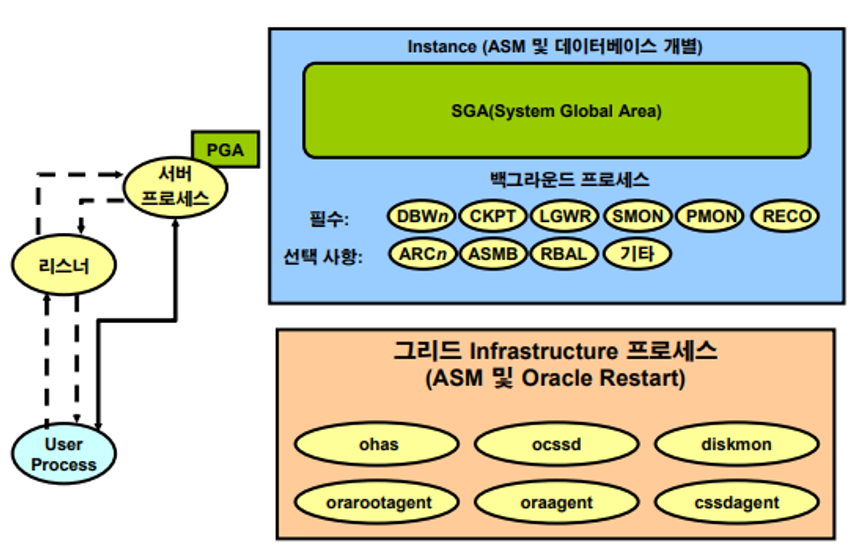
- Instance: 메모리 관련 프로세스
- 그리드 프로세스: 디스크 관련 프로세스
1. DBWn (Database Writers)
- 데이터베이스 버퍼 캐시(Database Buffer-Cache)의 수정된(더티) 버퍼를 디스크에 기록해 준다.
- 이때 더티 버퍼란 메모리에 있지만 아직 디스크에 반영되지 않은 데이터를 말한다.
- 더티 버퍼를 적절한 시점에 기록하지 않으면 메모리 부족 현상 또는 데이터 유실 위험이 증가한다. 그래서 DBWn은 특정 조건이 발생할 때 더티 버퍼를 디스크로 내려쓰는 것.
- DBWn이 데이터베이스 버퍼 캐시의 더티 버퍼의 내용을 파일에 내려쓰는 경우
- 체크 포인트(로그 파일과 데이터 파일의 동기화 시) 발생 시 (장애 복구 시간 단축)
- 더티 버퍼가 임계값을 지났을 때 (메모리를 비우기 위해)
- 타임 아웃 발생 시 (데이터 유실 방지)
- RAC Ping이 발생했을 때 (Real Application Clusters) RAC 환경에서는 여러 인스턴스가 같은 데이터를 공유하게 된다. 그래서 특정 블록을 한 인스턴스에서 다른 인스턴스로 넘겨 줄 때, 디스크에 먼저 기록해야 하는 경우가 발생
- 테이블 스페이스가 Read Only 상태로 변경될 때 더 이상 변경할 수 없는 상태가 되기 전에 저장
- 테이블 스페이스가 오프라인이 될 때 데이터 파일을 사용할 수 없는 상태로 만들기 전 기록해 데이터 무결성 유지
- 테이블 스페이스가 Begin Backup 상태가 될 때 온라인 백업 전 데이터 손실 방지
- Drop Table이나 Truncate Table이 될 때
- Direct Path Read/Write가 진행될 때 대량 데이터 로드 등의 Direct Path 작업은 버퍼를 거치지 않고 디스크를 바로 쓰기 때문에 더티 버퍼를 정리한 후 수행
- 일부 Parallel Query 작업이 진행될 때 동시에 데이터를 처리하기 때문에 변경된 데이터들을 정리한 후에 실행해야 함
2. LGWR (Log Writer)
- Redo Log Buffer도 메모리이기 때문에 서버가 꺼지면 내용이 날아갈 수 있다. 그래서 해당 Log File을 저장하여야 하는데 이때 Redo Log Buffer에 있는 내용을 Redo Log File에 기록하는 프로세서이다.
- 기록이 수행되는 경우
- User Process가 트랜잭션을 커밋할 때 Commit 요청이 왔을 때 Redo Log File이 없을 경우 Alert Log 파일에 에러를 기록해 두고 Commit 요청을 수행하지 않고 대기
- Redo Log Buffer가 1/3 찼을 때
- DBWn이 수정된 버퍼를 디스크에 기록하기 전에 LGWR는 DBWn보다 먼저 작동함 문제가 생겨서 데이터가 날아갈 수 있기 때문에 로그에 먼저 기록해 둠
- 3 초마다
3. CKPT (Checkpoint Process)
- 주기적으로 메모리에 있는 내용을 디스크로 내려쓰는 이벤트를 트리거하는 프로세서이다. 체크포인트 프로세스는 직접 데이터를 기록하지는 않는다. DBWn이 실행되도록 트리거해서 변경된 데이터를 저장하도록 유도한다.
- 체크포인트란 현재까지 변경된 데이터를 디스크에 반영하고 데이터 복구를 용이하게 하기 위해 특정 시점 정보를 저장하는 작업을 말한다.
- 체크 포인트 정보는 컨트롤 파일과 각 데이터 파일 헤더에 기록한다.
- 컨트롤 파일 (Control File): 데이터베이스의 메타데이터가 저장된 파일. 가장 최신의 체크포인트 SCN(System Change Number)를 기록함.
- 각 데이터 파일 헤더: 데이터 파일의 맨 앞부분에 체크포인트 SCN을 업데이트함. 이를 통해 특정 시점 이후 변경된 데이터가 존재하는지 확인할 수 있음.
- 체크포인트 프로세스가 발생하는 시점
- 로그 스위치 발생 시
- 데이터베이스 정지(Shutdown Immediate, Shutdown Transactional) 시
- Alter System Checkpoint 명령 실행 시 (관리자가 명령어 실행하면 강제 체크포인트 발생)
- Fast Start Checkpointing 기능 활성화 시 (일정 주기로 자동 체크포인트 발생)
- Redo Log File이 다 찼을 시
4. SMON (System Monitor Process)
- 인스턴스가 비정상 종료되었다 시작되는 시점에 인스턴스 복구를 시키는 역할을 한다.
- 또한 사용되지 않는 공간을 정리하고 테이블 스페이스를 온라인으로 복구하는 역할도 한다.
- Crash Recovery 수행
- 데이터베이스가 비정상적으로 종료(Crash)되었을 때 자동 복구를 수행한다.
- 복구 과정에서 Redo Log를 적용해 손실된 변경 사항을 반영하고, Undo 데이터를 이용해 트랜잭션 롤백한다.
- 트랜잭션이 커밋되었지만 데이터 파일에 변경되지 않은 변경 사항을 Redo Log에 다시 적용한다.
- 커밋되지 않은 트랜잭션은 Undo를 이용해 롤백.
- 임시 테이블 스페이스에서 사용되지 않는 공간을 정리하여 성능을 최적화한다.
- 오프라인 상태였던 테이블 스페이스를 온라인으로 전환할 때 복구 수행한다. 또한 비정상적으로 오프라인이 되었을 경우 Redo Log를 적용해 데이터 정합성을 유지한다.
- 사용하지 않는 임시 세그먼트를 정리한다.디스크 공간을 효율적으로 활용할 수 있게 한다.
- 임시 세그먼트는 order by, 임시 테이블 스페이스, create index, with절, sort merge join, 임시 테이블, 정렬 작업이 일어나는 모든 SQL에서 생성된다.
5. PMON (Process Monitor Process)
- 서버 프로세스들을 감시하고 비정상적으로 종료된 프로세스가 있다면 관련 복구 작업을 진행하는 역할을 한다.
- 유저 프로세스가 비정상적 종료되었다면 사용하고 있던 자원들을 모두 정리한다.
- 아무것도 안 하고 장시간 접속하고 있는 세션을 모니터링하고, 일정 시간 아무것도 하지 못하면 세션을 종료한다.
- 리스너에 동적으로 데이터베이스 서비스를 등록한다. (12c 이전까지만 12c부터는 리스너에 서비스를 동적으로 등록하는 기능을 담당하는 별도의 프로세서가 생김. LREG(Listener Registeration) 그렇기 때문에 문제 출제 시, 그 이후의 PMON 역할에 해당 부분은 제외되어야 함.)
✔ Redo 로그
- 오라클 데이터베이스에서 트랜잭션 변경 사항을 저장하는 파일로 장애 발생 시 데이터를 복구하는 데 사용된다.
- Redo Log는 데이터 파일에 기록되기 전 변경 사항을 먼저 저장해 데이터 유실을 방지한다.
- WAL(Write Ahead Logging)기법에도 사용되는데 이는 트랜잭션이 발생하면 먼저 Redo Log에 기록한 후 나중에 데이터 파일에 반영되는 것을 말한다.
- Redo Log를 기반으로 **장애 발생 시 변경 사항을 재반영(Roll Forward)하거나 트랜잭션 취소 시 Undo 데이터와 함꼐 사용해 롤백(Roll Back)을 수행한다.
1. 동작 방식
- LGWR(Log Writer) 프로세스에 의해 관리된다.
- 사용자가 데이터 변경(DML 명령)을 수행
- 변경 사항이 Redo Log Buffer(SGA 영역)에 저장
- LGWR 프로세스가 Redo Log Buffer의 내용을 Redo Log File로 기록
- 체크 포인트에서 DBWn이 데이터를 실제 데이터 파일로 기록
- Redo Log를 활용해 장애 발생 시 데이터 복구
2. Redo Log의 구조
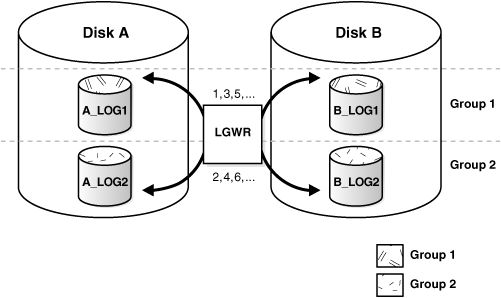
- Redo Log Buffer (메모리): SGA(System Global Area)내에 위치하며 트랜잭션 변경 사항이 임시적으로 저장되는 공간이다. LGWR 프로세스가 Redo Log File을 기록하기 전까지 데이터를 보관한다.
- Redo Log File (디스크): LGWR 프로세스가 Redo Log Buffer의 내용을 디스크에 기록하는 실제 로그 파일이다. 최소 2 개 이상의 그룹으로 구성되며 순환 방식으로 사용된다. 트랜잭션이 커밋될 때 변경 사항이 반드시 Redo Log File에 기록되며 파일이 꽉 차면 다음 그룹으로 이동(Log Switch 발생)한다. 이때 로그 스위치가 너무 자주 발생하면 LGWR의 부하가 발생하고 체크포인트 발생이 증가하므로 성능 저하가 일어난다.또한 아카이브 로그 공간 역시 부족해진다. 이와 반대로 로그 스위치가 너무 오래 걸리면 복구 시간이 길어지고, Redo Log Buffer가 가득 차서 성능 저하가 발생한다. 일반적으로 권장 주기는 10 분에서 15 분에 한 번씩 발생하는 것이 좋다.
-- 현재 로그 스위치 주기 확인
SELECT SEQUENCE#
, FIRST_TIME
, NEXT_TIME
FROM V$LOG_HISTORY ORDER BY FIRST_TIME DESC;- Redo Log Group과 Multiplexing: Redo Log는 최소 2 개 이상의 그룹으로 구성되며 각 그룹에는 1 개 이상의 Redo Log Member가 포함된다. 멀티플렉싱을 통해 동일한 내용을 여러 개의 Redo Log File에 기록해 장애 대비가 가능하다. (그림에서 A_LOG1, A_LOG2는 같은 내용을 가진 Redo Log File로 멀티플렉싱 된 것)
3. Redo Log 관련 SQL 명령어
-- Redo Log 확인
SELECT GROUP#, STATUS, MEMBER FROM V$LOGFILE;
-- 로그 스위치 강제 실행
ALTER SYSTEM SWITCH LOGFILE;
-- Redo Log 그룹 추가 (현재 데이터베이스에 새로운 Redo Log 그룹인 Group 3을 추가하는 명령어)
ALTER DATABASE
ADD LOGFILE
GROUP 3 ('/oradata/redo03.log') -- 3번 그룹, Redo Log 파일의 경로 및 파일명
SIZE 100M --Redo Log File 크기: 100 MB
;
-- 멀티플렉싱 적용
ALTER DATABASE
ADD LOGFILE
GROUP 3 ('/oradata/redo03a.log', '/oradata/redo03b.log')
SIZE 100M;✔ 오라클에서 사용하는 메모리 캐시
오라클 데이터베이스에서 사용하는 주요 메모리 캐시는 SGA(System Global Area)와 PGA(Program Global Area)로 나뉘게 된다.
❗️ SGA 영역
1. 데이터베이스 버퍼 캐시(Database Buffer Cache)
- 데이터 블록을 저장하는 캐시이며 디스크에서 읽어온 데이터 블록을 메모리에 저장해 성능을 향상시킨다.
- 데이터 변경이 발생하면 이곳에 더티 버퍼로 저장된다.
- 보통 사용자가 테이블을 조회하면 디스크에서 데이터를 읽어 캐시에 저장하고, 같은 데이터를 요청 시 디스크가 아닌 캐시에서 데이터를 가지고 와 성능을 향상시킨다. 변경된 데이터는 더티 버퍼로 저장되며 DBWn이 일정 주기마다 데이터를 디스크에 저장한다.
2. 공유 풀 (Shared Pool)
- SQL 실행 계획, PL/SQL 코드, 딕셔너리 정보 등을 저장하는 메모리 캐시이며 반복 실행되는 SQL을 빠르게 처리해 파싱 비용 절감을 한다.
- 구성 요소로는 라이브러리 캐시와 데이터 딕셔너리 캐시가 있다.
- 라이브러리 캐시 (Library Cache)는 SQL, PL/SQL, 실행 계획을 저장해 재사용이 가능하도록 관리한다.
- 데이터 딕셔너리 캐시 (Data Dictionary Cache)는 테이블, 인덱스, 사용자 정보 등의 데이터 딕셔너리 정보를 저장하며 DDL을 실행할 때도 사용한다.
3. 로그 버퍼 (Redo Log Buffer)
- 트랜잭션 변경 정보를 저장하는 캐시로 커밋 발생하면 LGWR 프로세스가 Redo Log File에 저장한다.
- 장애 발생 시 Redo Log를 이용해 데이터 복구 가능하다.
4. 자바 풀 (Java Pool)
- JVM(Java Virtual Machine) 관련 코드와 데이터를 저장한다. JAVA 기반의 저장 프로시저, 함수 실행 시 필요하다.
5. 스트림 풀 (Streams Pool)
- 오라클 스트리밍(Replication) 작업을 위한 캐시로 GoldenGate, 데이터 복제, AQ(Advanced Queuing)에서 사용한다.
❗️ PGA 영역 (개별 프로세스 메모리)
- 각 사용자 세션이 개별적으로 사용하는 메모리 영역이다.
- 보통 정렬(Sort Area), 해시 조인(Hash Join Area), 비트맵 조작 등의 연산을 수행한다.
- Result Cache(결과 캐시)는 쿼리의 실행 결과를 메모리에 저장하는 캐시로 같은 쿼리를 반복해서 실행할 때 성능 향상이 가능하게 해 준다. 즉, 쿼리 실행 후 결과를 메모리에 저장해 두고 동일한 쿼리가 실행될 때 디스크를 읽지 않고 메모리를 바로 결과로 가지고 오는 방식이다.
✔ 옵티마이저 힌트 종류 (18 번)
이전 작성한 힌트 관련 글
이전 힌트와 관련된 내용을 velog에 기록한 적이 있는데 여기에 기록되지 않은 틀린 힌트들만 오답 노트에 기록.
1. SWAP_JOIN_INPUTS
- SWAP_JOIN_INPUTS은 조인 연산을 수행할 때 조인 순서를 바꾸는 힌트이다.
- 하나의 조인 조건을 반대로 바꾸거나 입력 테이블의 순서를 바꿔서 조인 성능을 최적화하려는 경우 사용된다.
- 중첩된 조인(Nested Loops Join)이나 해시 조인(Hash Join)에서 유용하게 사용할 수 있지만 쿼리 성능에 영향을 미칠 수 있기 때문에 주의 깊게 사용해야 한다.
- 해당 힌트와 반대인 NO_SWAPPABLE_JOIN의 경우 조인 입력을 바꾸지 않도록 강제한다. 이는 기본적인 조인 순서를 유지해 특정 조인 순서가 성능상 유리할 경우 유용하다.
SELECT /*+ SWAP_JOIN_INPUTS */ *
FROM employees e, departments d
WHERE e.department_id = d.department_id;2. UNNEST
- UNNEST는 서브 쿼리나 복합 쿼리의 결과를 펼치는 역할을 한다.
- 서브 쿼리가 실행되기 전에 옵티마이저에게 서브 쿼리의 결과를 펼쳐서 메인 쿼리와 결합하도록 지시한다.
- 즉, 서브 쿼리를 다시 처리하지 않고 메인 쿼리와 서브 쿼리의 결과를 함께 결합하여 옵티마이저가 단일 실행 계획을 만들 수 있도록 한다.
- 서브 쿼리 최적화가 용이해지고, 비효율적인 서브 쿼리를 피할 수 있다.
- 서브 쿼리가 자주 실행되는 상황 혹은 복잡한 서브 쿼리에서 유용하다.
- 해당 힌트와 반대되는 힌트로는 NO_UNNEST가 있는데 이는 서브 쿼리를 펼치지 않도록 지시하여 원래의 서브 쿼리 형태로 실행되게 한다.
-- unnest를 쓸 경우 서브 쿼리가 펼쳐져
-- employees와 departments 테이블이 조인되는 형태로 진행
SELECT /*+ UNNEST */ *
FROM employees e
WHERE e.salary > (SELECT AVG(salary) FROM employees);✔ SQL 트레이스 정보를 이용한 버퍼 캐시 히트율 계산
1. SQL Trace
- SQL 트레이스는 오라클 데이터베이스에서 SQL 쿼리의 실행 경로와 성능 정보를 기록하는 기능이다.
- 데이터베이스가 실행한 쿼리의 실행 계획과 I/O 비용, 대기 이벤트 등 성능 문제를 분석하는 데 중요한 정보를 제공한다.
- 로그 파일에 기록할 수 있으며 주로 성능 분석과 튜닝을 위해 사용된다.
-- 특정 세션에서 SQL 트레이스를 시작하고
ALTER SESSION SET SQL_TRACE = TRUE;
-- 완료한다
ALTER SESSION SET SQL_TRACE = FALSE;
--해당 트레이스 파일은 보통 user_dump_dest 디렉토리 내 생성된다.2. 버퍼 캐시 (Buffer Cache) 히트율
- 버퍼 캐시는 오라클 데이터베이스가 디스크에서 읽은 데이터를 메모리에 캐시하는 공간이다.
- 이때 버퍼 캐시 히트율은 메모리에서 데이터를 읽을 확률을 말하며, 계산식은 다음과 같다.

- 버퍼 캐시 히트율은 높을수록 메모리에서 데이터를 읽는 비율이 높아 성능이 좋다는 뜻이고, 낮을수록 디스크에서 데이터를 더 많이 읽어야 하므로 성능 저하를 의미한다.
- 이때 메모리에서 읽은 데이터 수는 캐시에서 바로 찾을 수 있는 데이터 수를 말하며 논리적 I/O - 물리적 I/O를 의미 전체 읽은 데이터 수는 총 읽은 블록 수를 말하며 논리적 I/O를 의미한다.
- 문제에서 논리적 I/O는 query에서 이미 읽은 횟수를 말하므로 query(SQL 쿼리 실행 중 읽은 데이터 블록) + current(현재 처리되고 있는 행의 수, fetch 단계에서 반환된 데이터를 추적할 때 유용)를 말하고 물리적 I/O는 disk(디스크에서 읽은 데이터)를 말함.

송의 개발 LOG