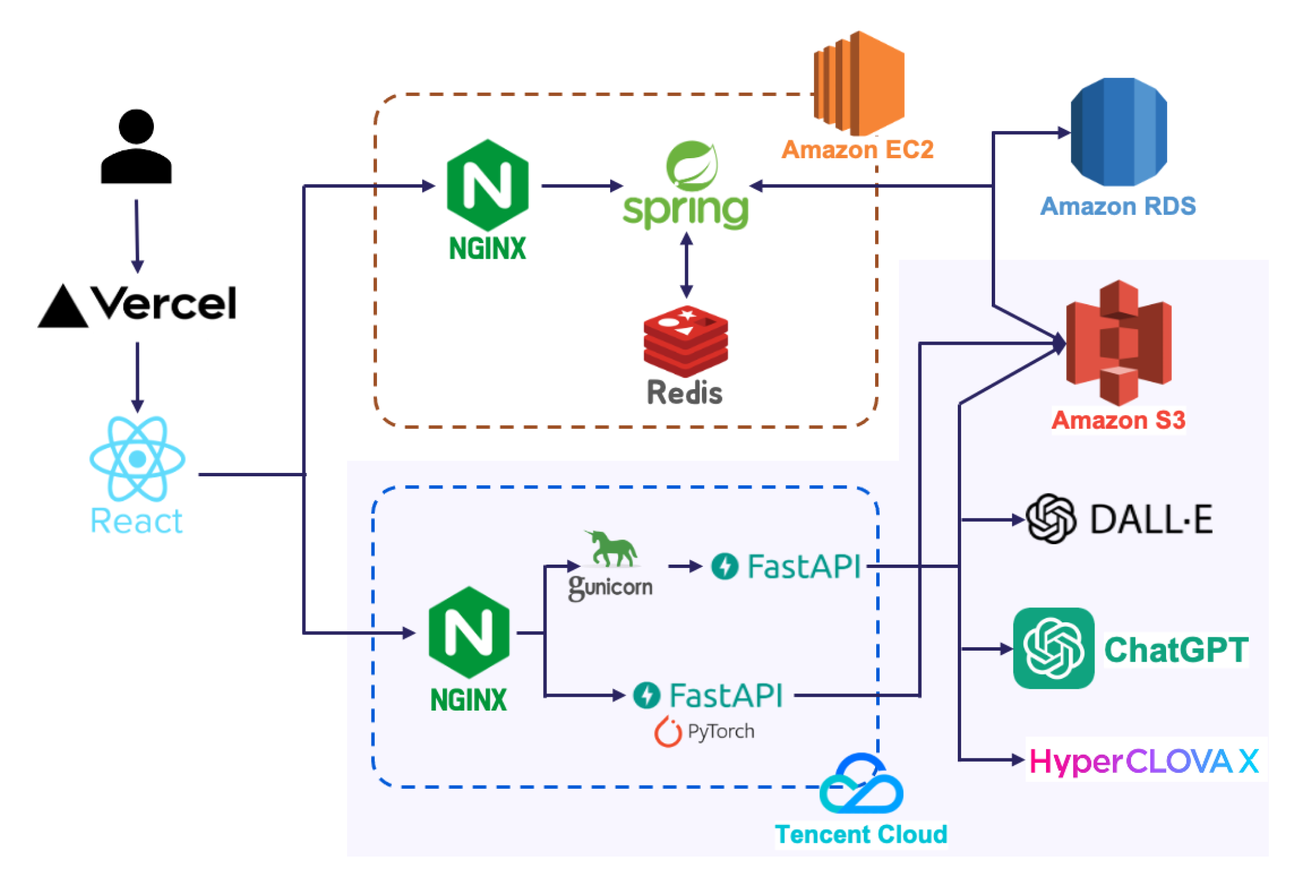
우리 프로젝트에서 시스템 구조도의 보라색 부분을 맡아 구현하였다.
딥러닝 서버를 배포하여 프론트엔드와 연결하고, 주 기능인 동화 생성 기능을 구현하였다.
따로 때어 보면 다음과 같다.
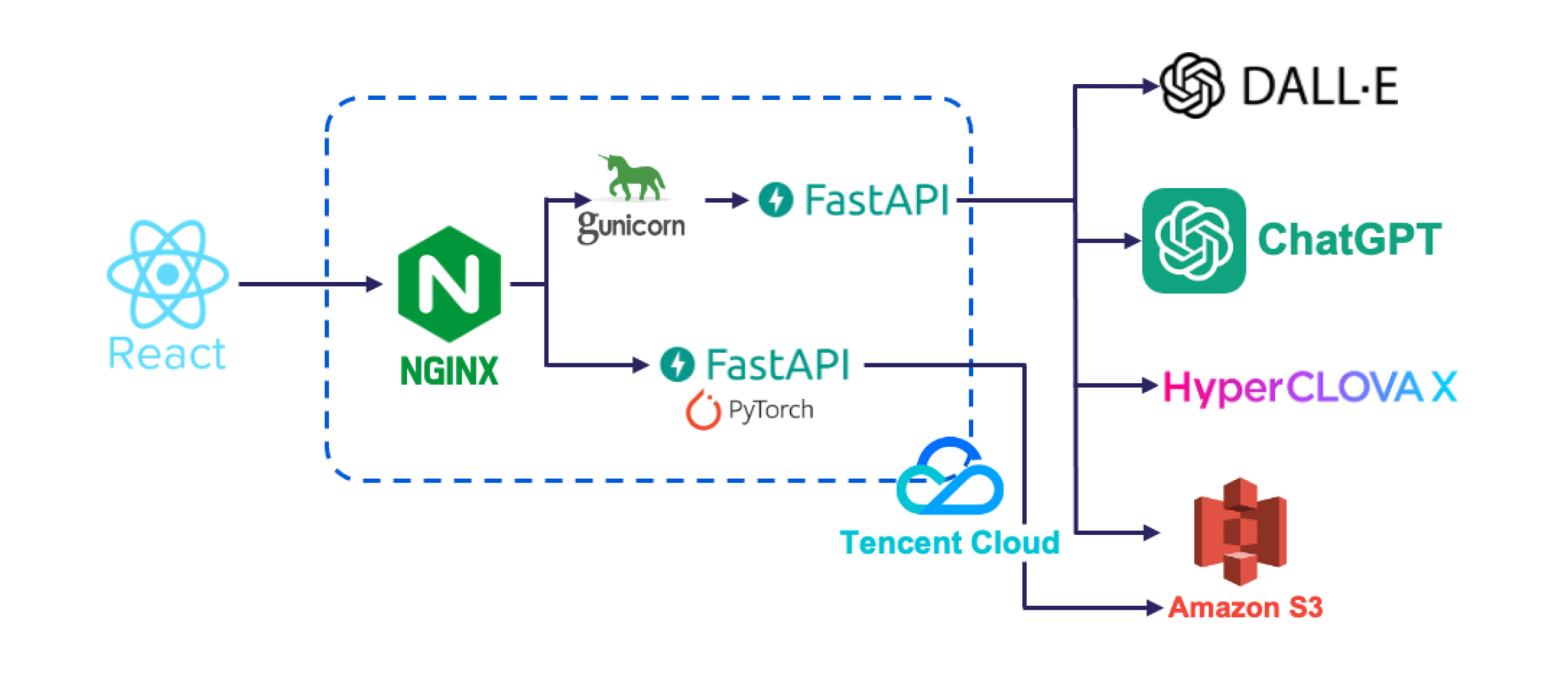
딥러닝 서버
서버 정보 확인
TencetCloud의 Cloud Virtual Machine 인스턴스를 학교에서 제공받았다.
다음과 같은 명령어를 터미널에 입력하여, 제공 받은 인스턴스의 정보를 파악하였다.
- Nvidia Driver, CUDA
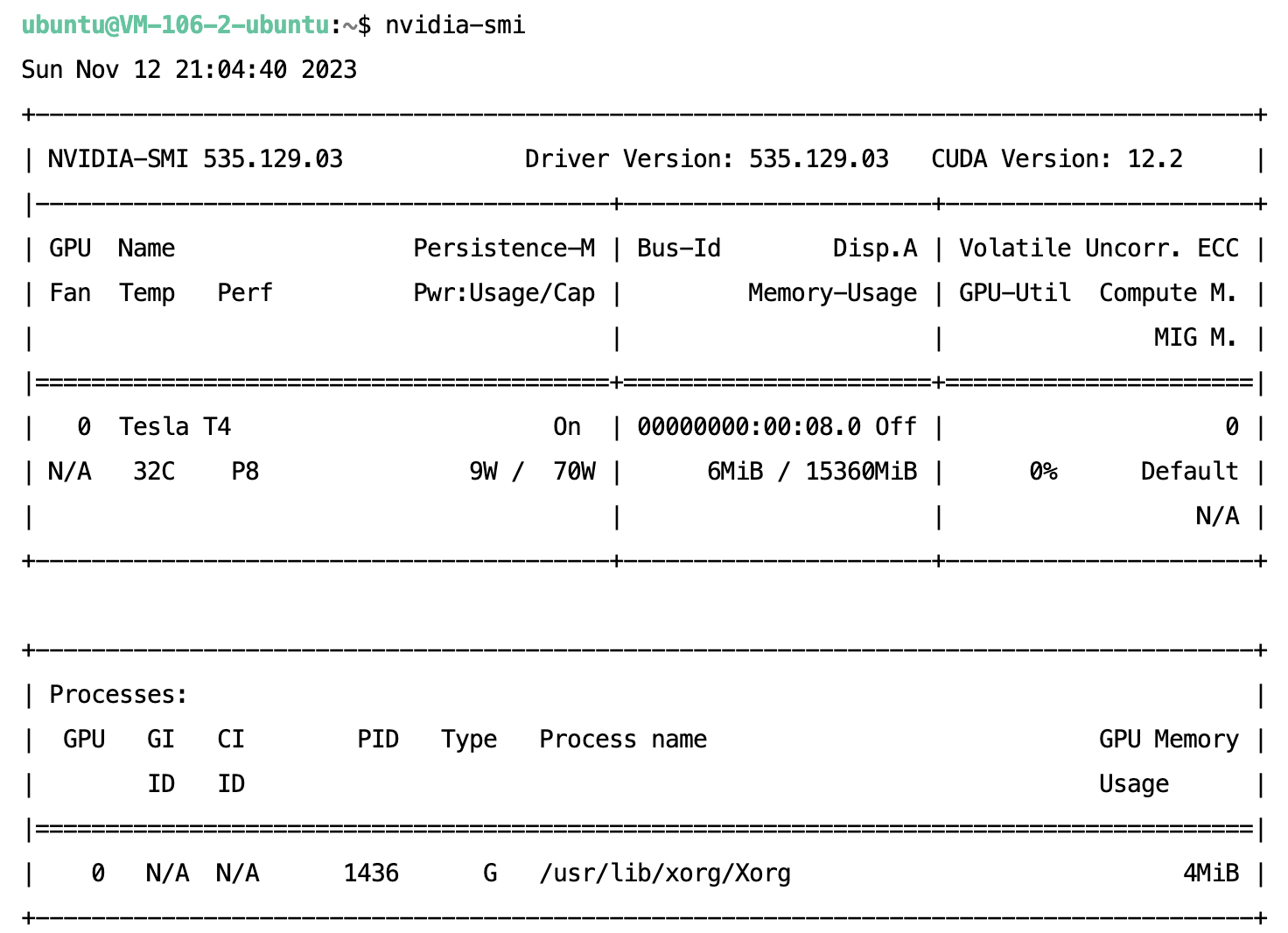
- GPU

- CPU

- python

알아낸 딥러닝 서버의 정보를 정리하였다.
Ubuntu Server 20.04 LTS 64bit
GPU: Tesla T4
Nvidia Driver 535.129.03
CUDA 12.2
python 3.8
EIP(Elastic IP) 설정
이는 제공 받은 인스턴스 서버에 도메인을 연결하기 위해서이다.
다음과 같이, TencentCloud CVM console에서 EIP로 설정한다.

도메인 구입 및 EIP와 연결
-
가비아 사이트에 회원가입 및 로그인
-
홈에서 원하는 도메인 명을 입력하여 구입한다.

-
'My가비아' > 'DNS 관리툴' > '가비아 등록 도메인' 선택
-
구입한 도메인 '설정' 선택 후 다음과 같이 설정

Nginx
Nginx를 Reverse Proxy로 사용하여 클라이언트와 두 배포된 어플리케이션이 통신하도록 하였다. Nginx에 SSL 암호화를 적용하였고, Cross-Origin Resource Sharing (CORS) 설정을 하였다.
GPU를 사용하는 프로그램과 사용하지 않는 프로그램을 구분하여 Cloud Virtual Machine에 배포하였다.
이렇게 두 개의 어플리케이션으로 배포한 이유는, 다음과 같이 GPU를 사용하는 프로그램은 여러 프로세스가 하나의 GPU에서 동시에 실행될 수 없어 동기적으로 작업해야 했다.

반면에, GPU를 사용하지 않는 프로그램은 사용자가 느린 응답 속도 때문에 서비스에서 이탈하는 것을 방지하기 위해 빠른 응답을 하여 여러 프로세스가 비동기 작업을 해야 했다.
Nginx 설치
서버의 패키지 목록 업데이트
sudo apt update
sudo apt upgrade
sudo apt autoremovesudo apt install nginxNginx 실행
sudo nginx -t
sudo systemctl start nginx도메인 이름 설정
- /etc/nginx/nginx.conf 파일 수정
cd /etc/nginx
sudo nano nginx.conf- 구매한 도메인의 이름을
server name에 설정
http {
server {
listen 80;
listen [::]:80;
underscores_in_headers on;
server_name {딥러닝 서버 도메인 이름};
}
}Reverse Proxy 설정
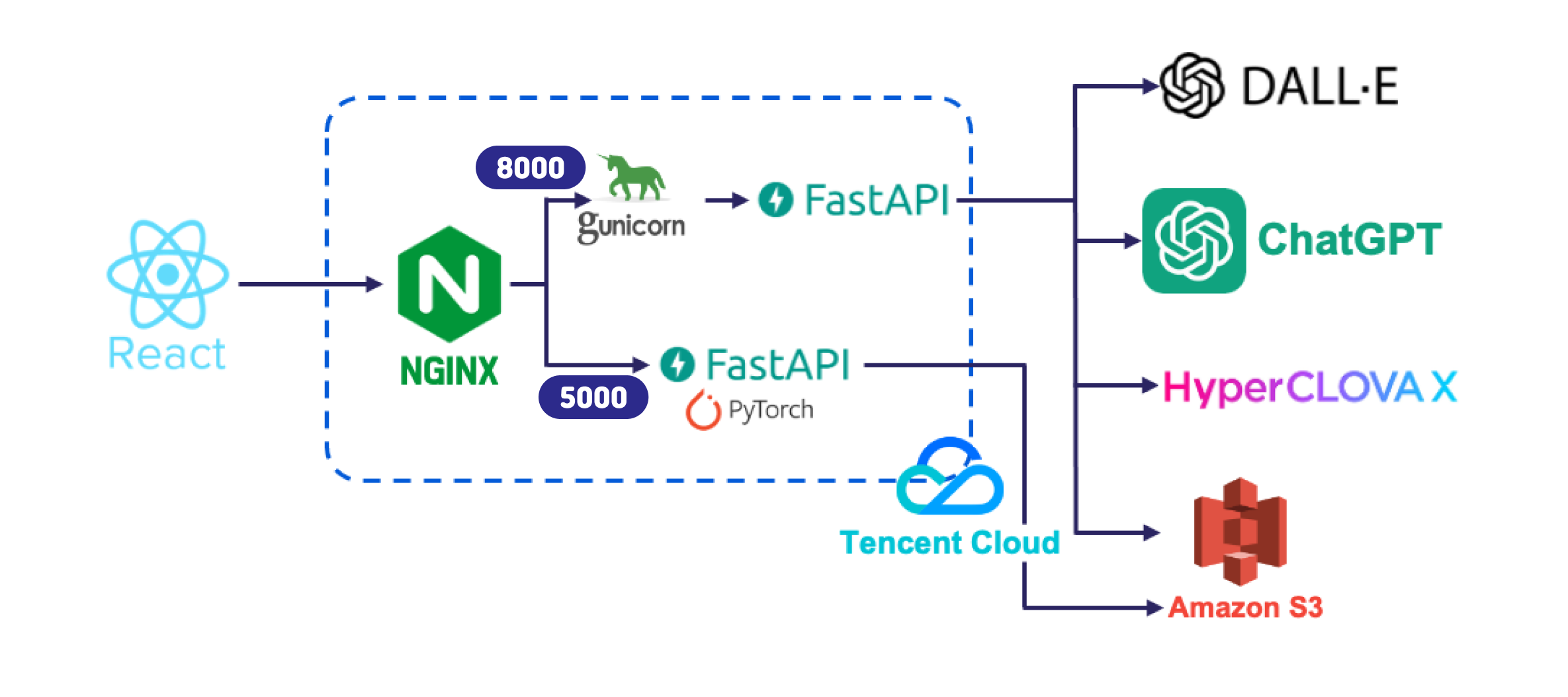
Nginx와 동일한 서버의 8000번 포트에 배포한 어플리케이션, 5000번 포트에 배포한 어플리케이션을 연결한다.
location을/과/music으로 호출 주소 규칙을 설정proxy_pass을http://127.0.0.1:8000,http://127.0.0.1:5000로 호출할 서버 주소 설정- 생성형 AI의 속도가 느린 경우를 대비하여,
proxy_read_timeout을 1000으로 늘린다.
http {
server {
listen 80;
listen [::]:80;
underscores_in_headers on;
server_name {딥러닝 서버 도메인 이름};
location / {
proxy_pass http://127.0.0.1:8000;
proxy_read_timeout 1000;
}
location /music {
proxy_pass http://127.0.0.1:5000;
proxy_read_timeout 1000;
}
}
}SSL 암호화 적용
Cerbot 설치
Ubuntu에서 다음과 같은 코드를 터미널에 입력하여 Cerbot을 설치하였다. (이전 서버에서는 시스템 Python과 아나콘다가 충돌하여 Cerbot 설치에 오류가 있었지만, 이번 서버에서는 잘 설치되었다.)
sudo apt install certbot python3-certbot-nginxSSL 인증서 얻기
sudo certbot --nginx -d example.com -d www.example.com안내 대로 따르다가 다음과 같은 옵션이 나왔을 때 2를 선택해준다.
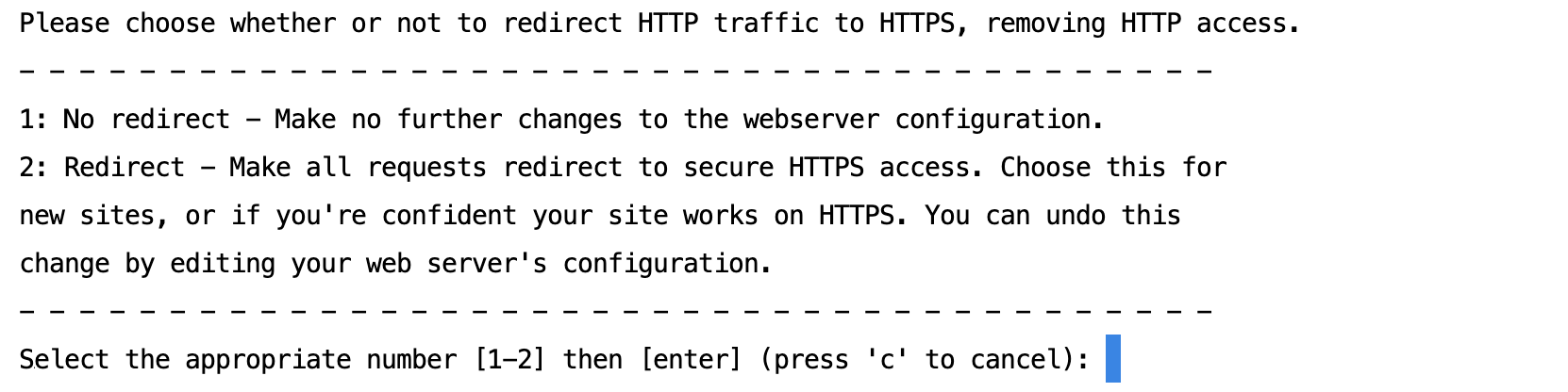
nginx.conf 설정
/etc/nginx/nginx.conf 파일은 다음과 같다.
http {
server {
...
listen [::]:443 ssl ipv6only=on; # managed by Certbot
listen 443 ssl; # managed by Certbot
ssl_certificate /etc/letsencrypt/live/tori-fairytale.store/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/tori-fairytale.store/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
}
server {
if ($host = {딥러닝 서버 도메인 이름}) {
return 301 https://$host$request_uri;
} # managed by Certbot
listen 80;
listen [::]:80;
server_name {딥러닝 서버 도메인 이름};
return 404; # managed by Certbot
}
}
- cerbot 사용해서 갱신 프로세스 테스트
sudo certbot renew --dry-run그 결과, 딥러닝 서버의 주소가 https://~ 가 되었다.
Cross-Origin Resource Sharing (CORS) 설정
nginx.conf 설정
우리 팀 Backend 팀원의 nginx.conf 파일의 도움을 받아 /etc/nginx/nginx.conf 파일에 다음과 같이 코드를 추가하였더니, Frontend와 CORS에러 없이 통신할 수 있었다.
http {
server {
listen 80;
listen [::]:80;
underscores_in_headers on;
server_name {도메인 이름};
location / {
proxy_pass http://127.0.0.1:8000;
proxy_read_timeout 1000;
# Preflight Request 인지
set $FLAG "";
if ($http_origin ~* '{프론트엔드 서버 주소}') {
set $FLAG "A";
}
if ($request_method = OPTIONS) {
set $FLAG "${FLAG}B";
# 모든 Origin 허용
add_header "Access-Control-Allow-Origin" $http_origin always;
# PUT DELETE 허용하지 않음
add_header "Access-Control-Allow-Methods" "GET, POST, DELETE, OPTIONS, HEAD, PUT" always;
# 사용하지 않는 헤더도 허용
# add_header "Access-Control-Allow-Headers" "api_key, Authorization, Origin, X-Requested-With, Content-Type, Accept" always;
add_header "Access-Control-Allow-Headers" "Content-Type, Authorization" always;
add_header "Access-Control-Allow-Credentials" "true" always;
add_header "Access-Control-Max-Age" "3600" always;
return 204;
}
if ($request_method = GET){
# 모든 Origin 허용
add_header "Access-Control-Allow-Origin" $http_origin always;
# PUT DELETE 허용하지 않음
add_header "Access-Control-Allow-Methods" "GET, POST, DELETE, OPTIONS, HEAD, PUT" always;
# 사용하지 않는 헤더도 허용
#add_header "Access-Control-Allow-Headers" "api_key, Authorization, Origin, X-Requested-With, Content-Type, Accept" always;
add_header "Access-Control-Allow-Headers" "Content-Type, Authorization" always;
add_header "Access-Control-Allow-Credentials" "true" always;
#return 200;
}
if ($request_method = POST){
# 모든 Origin 허용
add_header "Access-Control-Allow-Origin" $http_origin always;
# PUT DELETE 허용하지 않음
add_header "Access-Control-Allow-Methods" "GET, POST, DELETE, OPTIONS, HEAD, PUT" always;
# 사용하지 않는 헤더도 허용
#add_header "Access-Control-Allow-Headers" "api_key, Authorization, O>
add_header "Access-Control-Allow-Headers" "Content-Type, Authorization" always;
add_header "Access-Control-Allow-Credentials" "true" always;
# return 201;
}
if ($request_method = PUT){
# 모든 Origin 허용
add_header "Access-Control-Allow-Origin" $http_origin always;
# PUT DELETE 허용하지 않음
add_header "Access-Control-Allow-Methods" "GET, POST, DELETE, OPTIONS, HEAD, PUT" always;
# 사용하지 않는 헤더도 허용
#add_header "Access-Control-Allow-Headers" "api_key, Authorization, O>
add_header "Access-Control-Allow-Headers" "Content-Type, Authorization" always;
add_header "Access-Control-Allow-Credentials" "true" always;
#return 201;
}
if ($request_method = DELETE){
# 모든 Origin 허용
add_header "Access-Control-Allow-Origin" $http_origin always;
# PUT DELETE 허용하지 않음
add_header "Access-Control-Allow-Methods" "GET, POST, DELETE, OPTIONS, HEAD, PUT" always;
# 사용하지 않는 헤더도 허용
#add_header "Access-Control-Allow-Headers" "api_key, Authorization, O>
add_header "Access-Control-Allow-Headers" "Content-Type, Authorization" always;
add_header "Access-Control-Allow-Credentials" "true" always;
#return 200;
}
if ($request_method = PATCH){
# 모든 Origin 허용
add_header "Access-Control-Allow-Origin" $http_origin always;
# PUT DELETE 허용하지 않음
add_header "Access-Control-Allow-Methods" "GET, POST, DELETE, OPTIONS, HEAD, PUT" always;
# 사용하지 않는 헤더도 허용
#add_header "Access-Control-Allow-Headers" "api_key, Authorization, O>
add_header "Access-Control-Allow-Headers" "Content-Type, Authorization" always;
add_header "Access-Control-Allow-Credentials" "true" always;
#return 200;
}
# 위의 조건들이 TRUE면 요청을 허용한다.
if ($FLAG = "AB") {
add_header "Access-Control-Allow-Origin" $http_origin always;
add_header "Access-Control-Allow-Methods" "GET, POST, DELETE, PUT, OPTIONS" always;
add_header "Access-Control-Allow-Headers, Authorization" always;
add_header "Access-Control-Max-Age" "3600" always;
add_header "Access-Control-Allow-Credentials" "true" always;
return 204;
}
}
}
}Nginx 재실행
sudo systemctl restart nginxFastAPI
FastAPI 세팅
fastapi, uvicorn, gunicorn 설치
pip install fastapi
pip install "uvicorn[standard]" gunicorn[문제 해결] Gunicorn 비동기 작업 적용으로 응답 속도 6배 향상
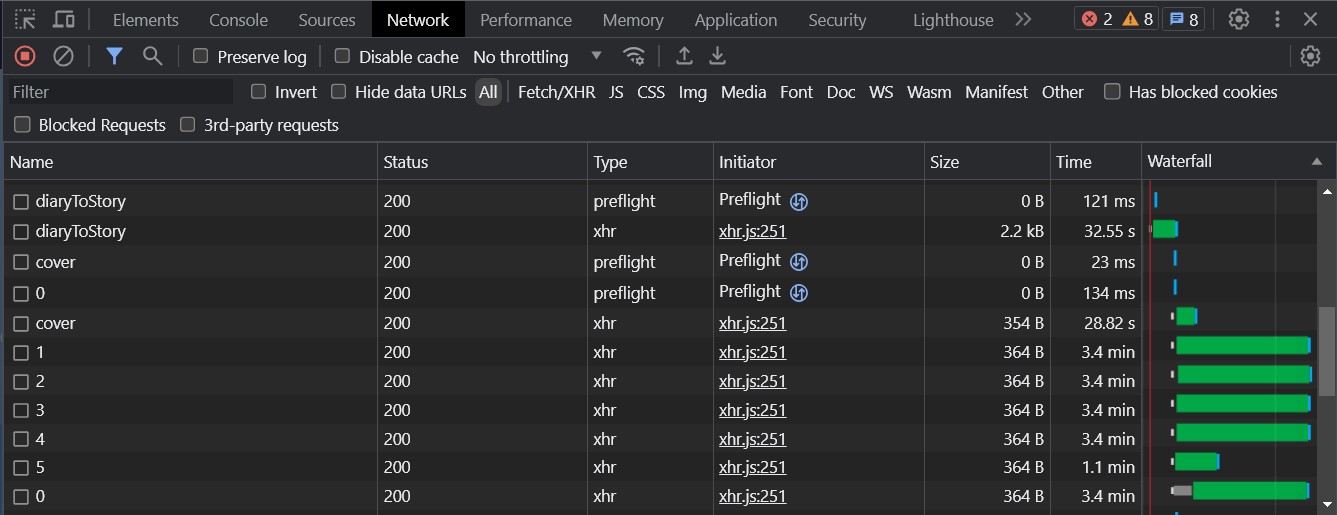
클라이언트에서 비동기적으로 동화책 커버 일러스트와 여러 페이지의 일러스트들을 동시에 호출하지만 응답 속도가 3분 이상으로 너무 느린 문제 상황이 있었다.
FastAPI에서 비동기적으로 응답하도록 설정했지만, 하나의 작업자에서만 실행되어 동기적으로 작업하는 것이 문제였다.
기존에는 ASGI 서버인 uvicorn을 사용하여 네트워크 I/O 처리를 최적화하였다.
uvicorn main:app --reloadmain은 Python 파일을 의미하고, app은 FastAPI 인스턴스를 나타낸다.
--reload는 개발 중 코드 변경을 감지하고 서버를 자동으로 재시작하는 기능이다.
하지만, uvicorn은 하나의 작업자에서만 실행되는 한계가 있다. 그래서 병렬처리를 위해서 WSGI 서버인 gunicorn을 적용하였다.
gunicorn과 uvicorn을 함께 사용하면, FastAPI 애플리케이션을 여러 작업자로 분산하여 처리하고, 동시에 다수의 HTTP 요청을 빠르게 처리할 수 있다.
gunicorn main:app -w 9 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:8000-w는 사용할 워커의 개수이다. 8개는 서버의 cpu의 코어 수를 확인하여 설정하였다.
-k는 사용할 워커의 종류이다. 여기서는 uvicorn 워커를 사용하겠다는 의미이다.
--bind 0.0.0.0:8000에서 0.0.0.0은 IP인데 외부에서 접근 가능하도록 배포한다는 의미이고, 8000은 port이다.
타임아웃 오류가 나서 default 30초에서 10분으로 타임아웃 시간을 늘려주었다.
[2023-09-18 00:54:47 +0900] [97794] [CRITICAL] WORKER TIMEOUT (pid:97798)
gunicorn main:app -w 9 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:8000 --timeout 600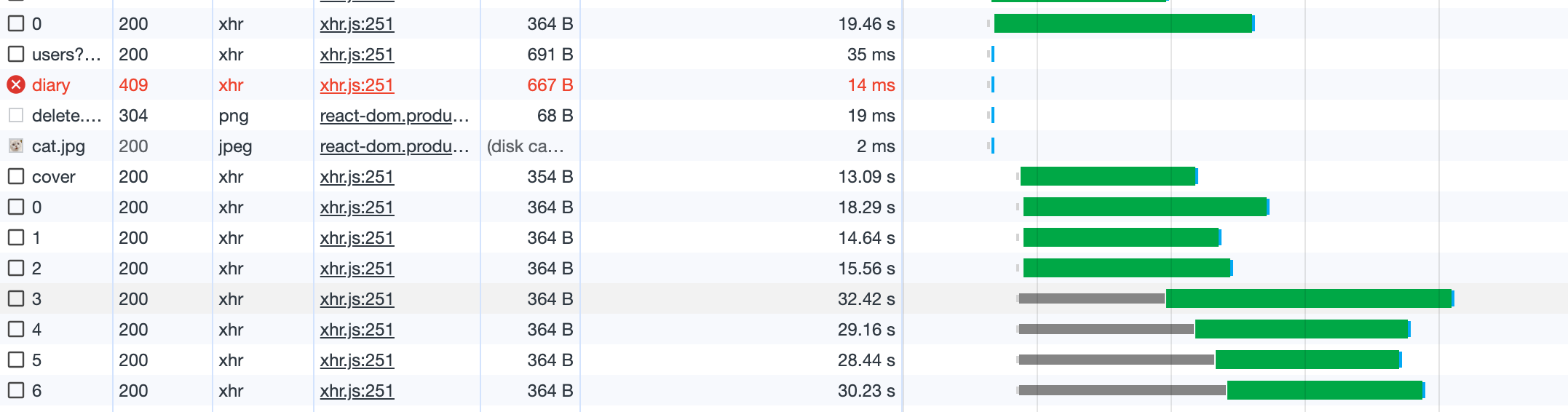
gunicorn 적용 후, 3분 이상에서 30초 정도로 응답 속도가 개선되었다.
1. uvicorn으로만 5000 포트 배포
from fastapi import FastAPI
import uvicorn
app = FastAPI()
if __name__ == "__main__":
uvicorn.run("uvicorn_deploy:app", host="0.0.0.0", port=5000, reload=True)2. gunicorn 적용하여 8000 포트 배포
from fastapi import FastAPI
from gunicorn.app.base import BaseApplication
app = FastAPI()
class StandaloneApplication(BaseApplication):
def __init__(self, app, options=None):
self.options = options or {}
self.application = app
super().__init__()
def load_config(self):
config = {key: value for key, value in self.options.items()
if key in self.cfg.settings and value is not None}
for key, value in config.items():
self.cfg.set(key.lower(), value)
def load(self):
return self.application
if __name__ == "__main__":
options = {
'preload_app': True,
'bind': '%s:%s' % ('0.0.0.0', '8000'),
'worker_class': 'uvicorn.workers.UvicornWorker',
# 'post_worker_init': post_worker_init,
# 'workers': mp.cpu_count() * 2 + 1, # number of GPU worker
'workers': 9,
'timeout': 600,
'reload': True
}
StandaloneApplication(app, options).run()cf. 만약 8000 포트를 사용하는 모든 쓰레드를 삭제하려면 다음과 같은 명령어를 터미널에 입력한다.
kill -9 $(lsof -i:8000 -t) 2>/dev/null생성형 AI를 이용하여 동화책 생성
Frontend와 딥러닝 서버가 통신하기 위해 API 규칙을 팀원들과 함께 정하였다.
OpenAI (ChatGPT, DALLE)
OpenAI 설치
pip install openai
OpenAI 세팅
import openai
import uuid
import json
with open('secrets.json') as f:
secrets = json.loads(f.read())
openai.api_key = secrets['openai_api_key']
MODEL = "gpt-3.5-turbo" # ChatGPT 모델모델은 gpt-3.5-turbo를 선택하였다.
Prompt Engineering
Prompt Engineering을 위해 주로 다음 사이트를 참고하였다.
- https://www.promptingguide.ai/ : prompt engineering의 일반적인 이론에 대해 설명한다.
- https://platform.openai.com/docs/introduction : ChatGPT에서 사용하는 prompt engineering 방법을 설명한다.
- https://dallery.gallery/wp-content/uploads/2022/07/The-DALL%C2%B7E-2-prompt-book-v1.02.pdf: DALLE에서 prompt enginnering으로 가능한 화풍을 확인할 수 있다.
생성형 AI를 이용하여 어린이의 일기를 바탕으로 이야기, 제목, 삽화, 배경음악으로 구성된 동화책 하나가 만들어지는 과정을 그림으로 나타내었다.
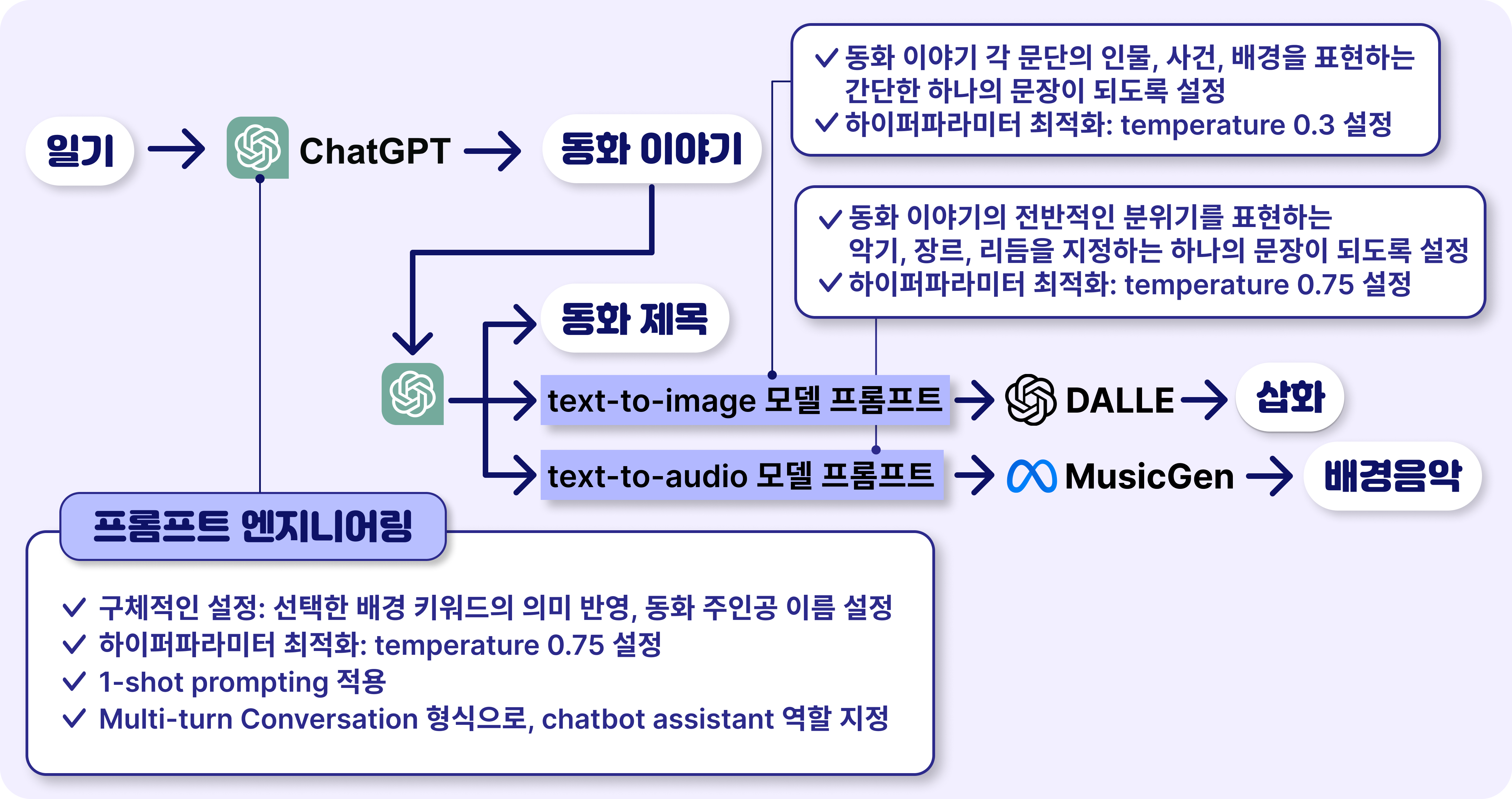
- 어린이가 일기를 작성하면,
ChatGPT가 일기를 기반으로 동화 이야기를 생성해준다. - 생성한 동화 이야기를 바탕으로
ChatGPT가 (1) 동화 제목, (2) DALLE 모델 프롬프트, (3) MusicGen 모델 프롬프트를 생성한다. DALLE와MusicGen은 각각의 만들어진 프롬프트를 입력으로 받아 각각 동화책 (a) 삽화와 (b) 배경음악을 생성한다.
1. ChatGPT로 동화 이야기 생성 API
POST /diaryToStory
Request Body (일기)
{
"name": "고양이",
"title": "",
"contents": "오늘 밤에 자전거를 탔다. 자전거는 처음 탈 때는 좀 중심잡기가 힘들었다. 그러나 재미있었다. 자전거를 잘 타서 엄마, 아빠 산책 갈 때 나도 가야겠다.",
"keyword": "우주"
}
Response Body (동화 제목, 텍스트)
{
"title": "우주 모험, 자전거 꿈",
"texts": [
"한참 연습한 끝에, 고양이는 저녁에 자전거를 타고 마을을 돌아다녔어요. 처음에는 좀 허덕이긴 했지만, 결국에는 잘 탈 수 있게 되었어요. 고양이가 자전거를 잘 타니까, 엄마와 아빠가 산책을 갈 때마다 나도 함께 가야겠다고 생각했어요.",
"그런데 고양이에게는 자전거 타기보다 더 큰 꿈이 있었어요. 고양이는 우주선을 타고 우주로 떠나는 모험을 꿈꾸었어요. 별들과 함께 모험하고, 다른 행성들을 탐험하며, 우주에서 재미있는 일을 할 수 있다는 게 고양이의 꿈이었어요.",
"고양이는 그날 밤, 잠들기 전에 별들을 보면서 꿈을 꾸었어요. 그리고 고양이 앞에 아름다운 우주선이 나타났어요. 고양이는 설레임을 감출 수 없었어요. 그래서 우주선에 올라타고, 무한한 우주로 향해 모험을 시작했어요.",
"고양이는 우주에서 처음으로 보는 행성들을 만났어요. 녹색 풀로 덮인 행성에서 꽃들과 놀고, 파란 바다가 펼쳐진 행성에서 아름다운 물고기들을 볼 수 있었어요. 그리고 또 다른 행성에서는 작은 우주 생물들과 친구가 되어 함께 놀았어요.",
"우주선을 타고 여러 행성들을 방문하면서, 고양이는 우주 다른 생물들과 어울리며 새로운 친구들을 사귀었어요. 함께 놀고 웃으면서, 고양이는 매 순간이 행복했어요.",
"하지만 언젠가는 고양이는 집으로 돌아와야 했어요. 그래서 고양이는 우주선을 타고 지구로 돌아왔어요. 엄마와 아빠에게 모험 이야기를 들려주었고, 그들은 미소 짓더라구요.",
"이후로도 고양이는 자전거를 타면서 언제든 우주 모험을 꿈꿀 수 있었어요. 그리고 고양이는 항상 다른 행성들을 상상하고 모험을 즐길 수 있었어요."
]
}@app.post("/diaryToStory")
async def diary_to_story(diary: Diary):
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": f'The user will provide you with text delimited by triple quotes. \
You change the text into a story that has the meaning of the keyword \"{keyword_kor2eng.get(diary.keyword, "마법")}\" \
so that it is suitable for children to read and interesting to develop. \
The name of the main character in this story is \"{diary.name}\". \
The story should consist of more than six paragraphs consisting of one or two sentences. \
And please write it in Korean using honorifics.'},
# assistant role 추가
{"role": "user", "content": '"""오늘 밤에 자전거를 탔다. 자전거는 처음 탈 때는 좀 중심잡기가 힘들었다. 그러나 재미있었다. 자전거를 잘 타서 엄마, 아빠 산책 갈 때 나도 가야겠다."""'},
{"role": "assistant", "content": f'{story_template(diary.name, diary.keyword)}'},
{"role": "user", "content": '"""' + diary.contents +'"""'},
],
temperature=0.75,
max_tokens=2048
)
story = response["choices"][0]["message"]["content"] # story
title = create_title(story, diary.keyword)
texts = list(map(lambda x: x.strip("\""), story.split("\n\n")))
return StoryTitleText(title=title, texts=texts)아이들의 상상력을 자극하고 창의적인 동화 이야기를 만들기 위해, 다음과 같은 프롬프트 엔지니어링을 사용하였다.
- 이야기의 내용에 선택한 배경 키워드의 의미 반영하고, 동화 주인공 이름을 설정하기 위해 동화 생성을 어떻게 할지 system에게 구체적인 설정을 주었다.
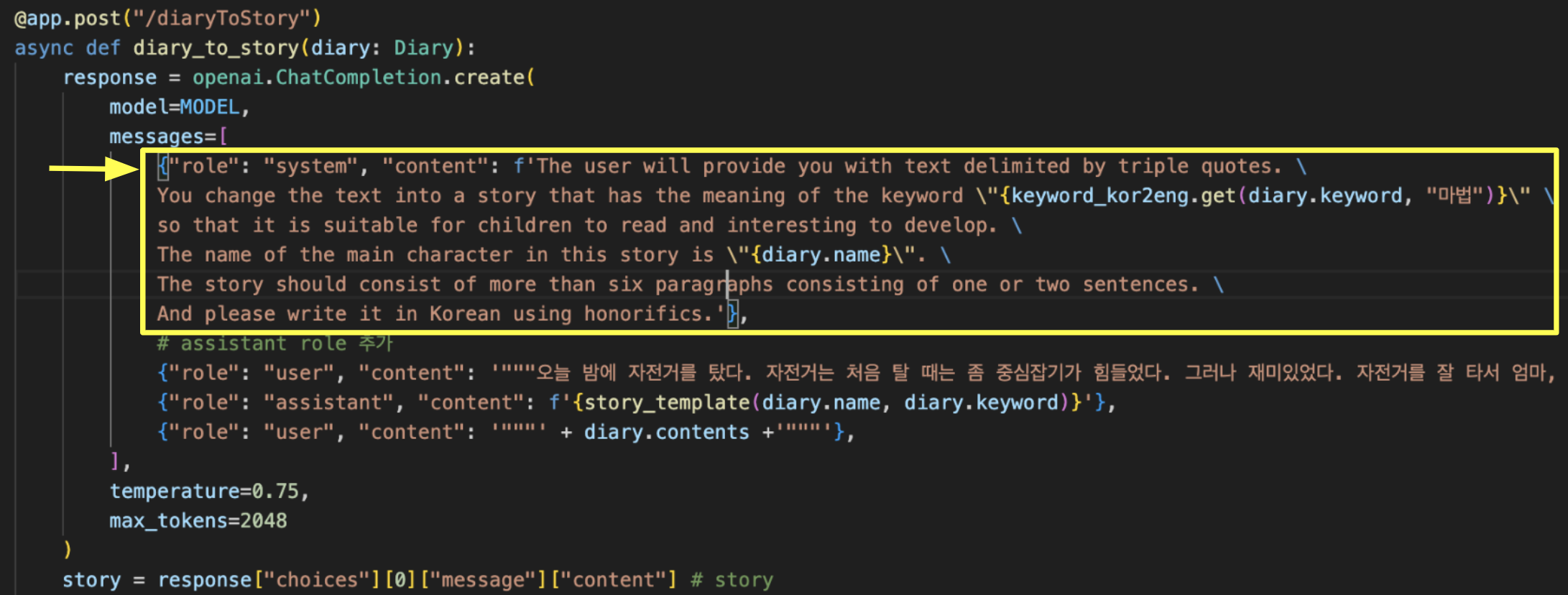
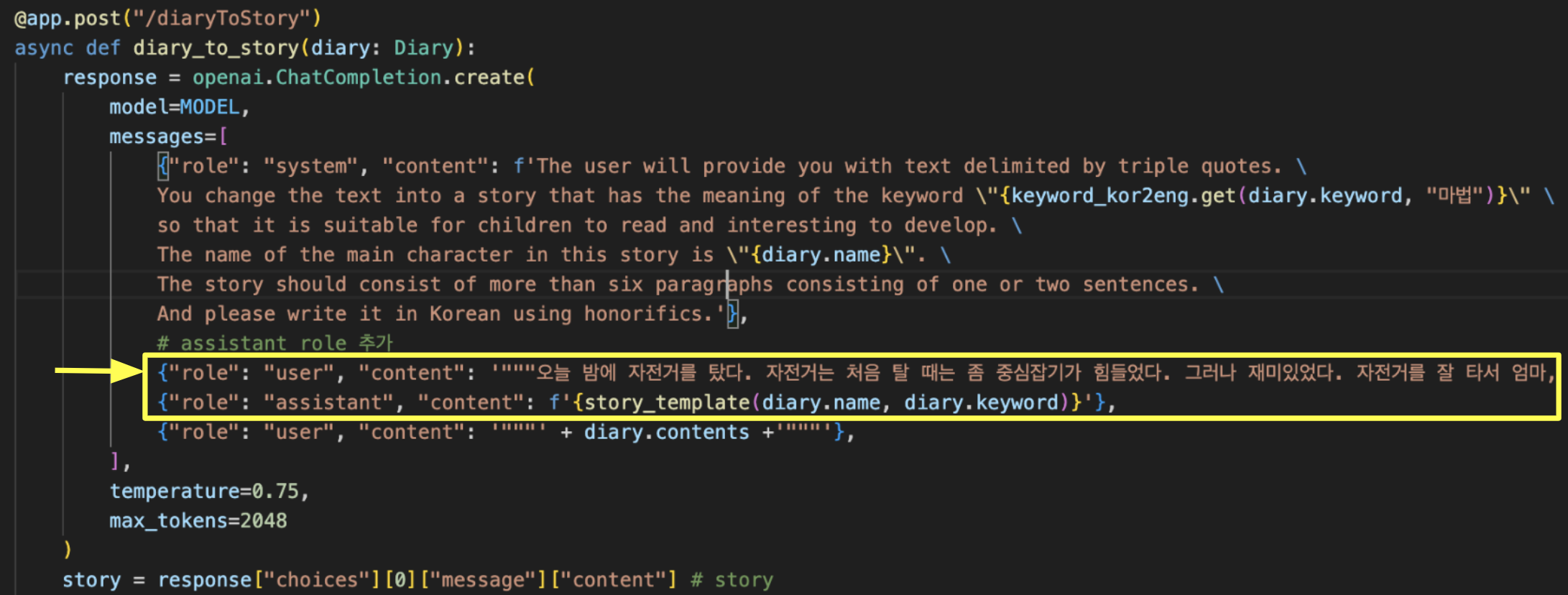
- 이야기의 문단과 문장의 구성을 정하고, 각 문장이 "해요체" 높임을 사용하고, 배경 키워드에 따라 이야기의 전개를 설정하고 하기 위해, Multi-turn Conversation 형식으로, chatbot assistant의 역할을 지정하여 1-shot prompting을 적용하였다.
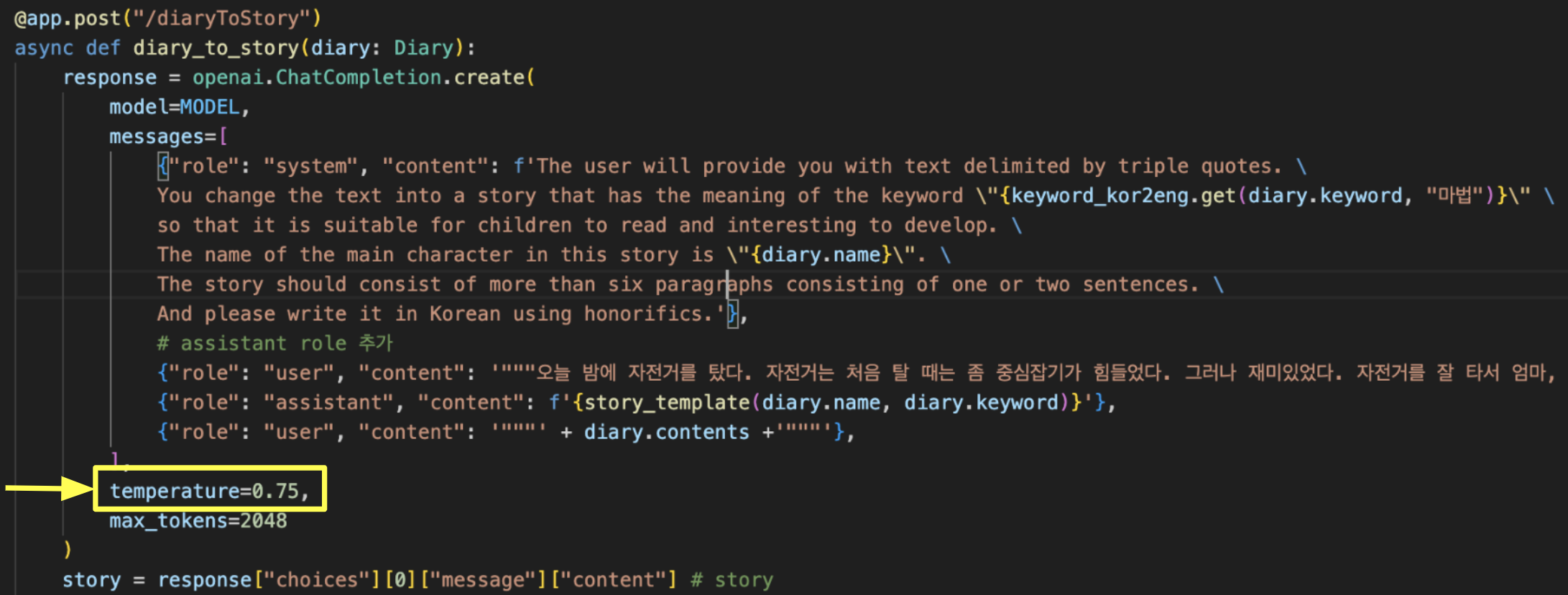
- 하이퍼파라미터를 temperature 0.75로 설정하여 최적화하였다. (temperature 값이 더 높을수록 발생 가능성이 낮은 단어 선택, 창의적인 일인 경우 주로 0.70~0.90이 보편적, 실험적으로 적용해 본 결과 가장 적합한 값 0.75 설정)
2-(1). ChatGPT로 동화 제목 생성 함수
다음은 동화 전체와 동화에 반영될 키워드를 인자로 받아 ChatGPT로 동화 제목을 생성하여 반환하는 함수이다.
def create_title(story: str, keyword: str):
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": f"""The user will provide you with text delimited by triple quotes. \
Please make a creative and impressive title of less than five words that expresses the whole story \
and the meaning of the keyword \"{keyword_kor2eng.get(keyword, "마법")}\" well in Korean."""},
{"role": "user", "content": '"""' + story +'"""'},
],
temperature=0.7,
)
return response["choices"][0]["message"]["content"].strip("\"")2-(2). ChatGPT로 DALLE 프롬프트 생성 함수
다음 함수는 각각의 동화 이야기 문단을 인자로 받아 ChatGPT로 DALLE에 입력될 프롬프트를 생성하여 반환하는 함수이다.
def text_to_image_prompt(text: str):
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "The user will provide you with text delimited by triple quotes. \
Please convert this text into a prompt \
that expresses the situation of the text well for the DALL·E model \
and consists of only one simple sentence and be written in English."},
{"role": "user", "content": '"""' + text +'"""'},
],
temperature=0.3,
)
return response["choices"][0]["message"]["content"] # prompt2-(3). ChatGPT로 MusicGen 프롬프트 생성 함수
다음은 동화 전체 이야기를 인자로 받아 ChatGPT로 MusicGen에 입력될 프롬프트를 생성하여 반환하는 함수이다.
def story_to_music_prompt(story):
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "The user will provide you with text delimited by triple quotes. \
Please convert this text into a prompt \
which composes music that explains and expresses the overall atmosphere and message of the text well \
and contains which instruments to use, musical genre and rhythm. \
The prompt should consist of only one simple sentence and be written in English."},
{"role": "user", "content": '"""' + story +'"""'},
],
temperature=0.75,
max_tokens=2048
)
return response["choices"][0]["message"]["content"] # prompt
3-(a). DALLE로 삽화 생성 함수
다음은 프롬프트를 인자로 받아 DALLE로 삽화를 생성하여 반환하는 함수이다.
def prompt_to_image(prompt: str, style: Optional[str] = "digital art"):
try:
response = openai.Image.create(
prompt=prompt + ", " + style,
n=1,
size="1024x1024",
)
dalle_url = response['data'][0]['url']
except:
return None➡️ 동화책 표지 삽화 생성 API
POST/cover
Request Body (동화 제목, 텍스트)
{
"title": "우주 모험, 자전거 꿈",
"texts": [
"한참 연습한 끝에, 고양이는 저녁에 자전거를 타고 마을을 돌아다녔어요. 처음에는 좀 허덕이긴 했지만, 결국에는 잘 탈 수 있게 되었어요. 고양이가 자전거를 잘 타니까, 엄마와 아빠가 산책을 갈 때마다 나도 함께 가야겠다고 생각했어요.",
"그런데 고양이에게는 자전거 타기보다 더 큰 꿈이 있었어요. 고양이는 우주선을 타고 우주로 떠나는 모험을 꿈꾸었어요. 별들과 함께 모험하고, 다른 행성들을 탐험하며, 우주에서 재미있는 일을 할 수 있다는 게 고양이의 꿈이었어요.",
"고양이는 그날 밤, 잠들기 전에 별들을 보면서 꿈을 꾸었어요. 그리고 고양이 앞에 아름다운 우주선이 나타났어요. 고양이는 설레임을 감출 수 없었어요. 그래서 우주선에 올라타고, 무한한 우주로 향해 모험을 시작했어요.",
"고양이는 우주에서 처음으로 보는 행성들을 만났어요. 녹색 풀로 덮인 행성에서 꽃들과 놀고, 파란 바다가 펼쳐진 행성에서 아름다운 물고기들을 볼 수 있었어요. 그리고 또 다른 행성에서는 작은 우주 생물들과 친구가 되어 함께 놀았어요.",
"우주선을 타고 여러 행성들을 방문하면서, 고양이는 우주 다른 생물들과 어울리며 새로운 친구들을 사귀었어요. 함께 놀고 웃으면서, 고양이는 매 순간이 행복했어요.",
"하지만 언젠가는 고양이는 집으로 돌아와야 했어요. 그래서 고양이는 우주선을 타고 지구로 돌아왔어요. 엄마와 아빠에게 모험 이야기를 들려주었고, 그들은 미소 짓더라구요.",
"이후로도 고양이는 자전거를 타면서 언제든 우주 모험을 꿈꿀 수 있었어요. 그리고 고양이는 항상 다른 행성들을 상상하고 모험을 즐길 수 있었어요."
]
}
Response Body (표지)
{
"coverUrl": "https://bemystory-s3-data.s3.ap-northeast-2.amazonaws.com/e82d1a78-82f3-11ee-a704-7b2ff80a7a30.webp"
}@app.post("/cover")
async def create_cover(story_title_text: StoryTitleText):
whole_text = f"title: {story_title_text.title}\n" + "\n".join(story_title_text.texts)
prompt = text_to_image_prompt(whole_text)
prompt = prompt_to_one_sentence(prompt)
cover_url = prompt_to_image(prompt)
return Cover(coverUrl=cover_url)➡️ 동화 이야기 문단마다 삽화 생성 API
POST /textToImage/{pageNum}
Request Body (동화 문단 하나)
{
"text" : "고양이는 우주에서 처음으로 보는 행성들을 만났어요. 녹색 풀로 덮인 행성에서 꽃들과 놀고, 파란 바다가 펼쳐진 행성에서 아름다운 물고기들을 볼 수 있었어요. 그리고 또 다른 행성에서는 작은 우주 생물들과 친구가 되어 함께 놀았어요."
}
Response Body (일러스트 한개)
{
"imgUrl": "https://bemystory-s3-data.s3.ap-northeast-2.amazonaws.com/a0e92630-82ed-11ee-a704-7b2ff80a7a30.webp%22",
"pageNum": 3
}@app.post("/textToImage/{pageNum}")
async def text_to_image(pageNum: int, paragraph: Paragraph):
prompt = text_to_image_prompt(paragraph.text).strip("\"")
prompt = prompt_to_one_sentence(prompt)
img_url = prompt_to_image(prompt)
return Illustration(imgUrl=img_url, pageNum=pageNum)cf. DALLE에 입력할 프롬프트가 단순할수록 그림의 형체가 분명하게 나타나는 경향이 있었다. 그래서 ChatGPT가 만든 DALLE에 입력할 프롬프트가 만들어진 후 아래의 prompt_to_one_sentence()를 적용하여, 혹시라도 ChatGPT가 DALLE에 입력할 프롬프트를 두 문장 이상 생성한 경우 한 문장으로 단순하게 만들어주었다.
def prompt_to_one_sentence(prompt: str):
prompt = prompt.split('.')[0] + "."
return promptMusicGen
MusicGen Inference
PyTorch 2.0 이상 설치
pip install 'torch>=2.0'설치된 PyTorch 버전에 비해 CUDA 버전이 너무 낮아서 PyTorch가 GPU를 사용하지 못하는 오류가 있었다. 그래서 Nvidia driver를 다시 설치하여 CUDA 버전을 가장 최신으로 변경했더니, 다음과 같이 PyTorch가 잘 작동하였다.
musicGen 모델 소스코드 빌드
git clone https://github.com/facebookresearch/audiocraft.git
cd audiocraft
pip install -e .audiocraft 깃허브의 inference 코드로 각 모델들을 실행한 결과, 가장 작은 크기의 300M transformer decoder인musicgen-small로도 꽤 괜찮은 음악이 만들어졌기 때문에 이 모델을 선택하였다. 이 모델로 1초당 1초 짜리 음악을 만들 수 있었고, 한번 실행 시 약 800M 정도 VRAM을 차지했다.
다음과 같이, 하이퍼파라미터를 설정하여 30초 음악을 생성하도록 하였다.
use_sampling(bool, optional): use sampling if True, else do argmax decoding.top_k(int, optional): top_k used for sampling.duration(float, optional): duration of the generated waveform.
from audiocraft.models import MusicGen
model = MusicGen.get_pretrained('facebook/musicgen-small', device=torch.device("cuda"))
model.set_generation_params(
use_sampling=True,
top_k=250,
duration=30
)Jupyter Notebook에서 실행되는 Inference 코드를 바탕으로,
from audiocraft.utils.notebook import display_audio
output = model.generate(
descriptions=[prompt],
progress=True, return_tokens=True
)
display_audio(output[0], sample_rate=32000)전체 소스코드를 분석하여 다음과 같이 python 파일로 Inference 되도록 변경하였다.
outputs = model.generate(
descriptions=[prompt],
progress=True, return_tokens=True
)
wav = outputs[0][0].detach().cpu().float()
assert wav.dtype.is_floating_point
if wav.dim() == 1:
wav = wav[None]
elif wav.dim() > 2:
raise ValueError("Input wav should be at most 2 dimension.")
assert wav.isfinite().all()[문제 해결] inference 시 memory leak, 메모리 과부하 문제 해결
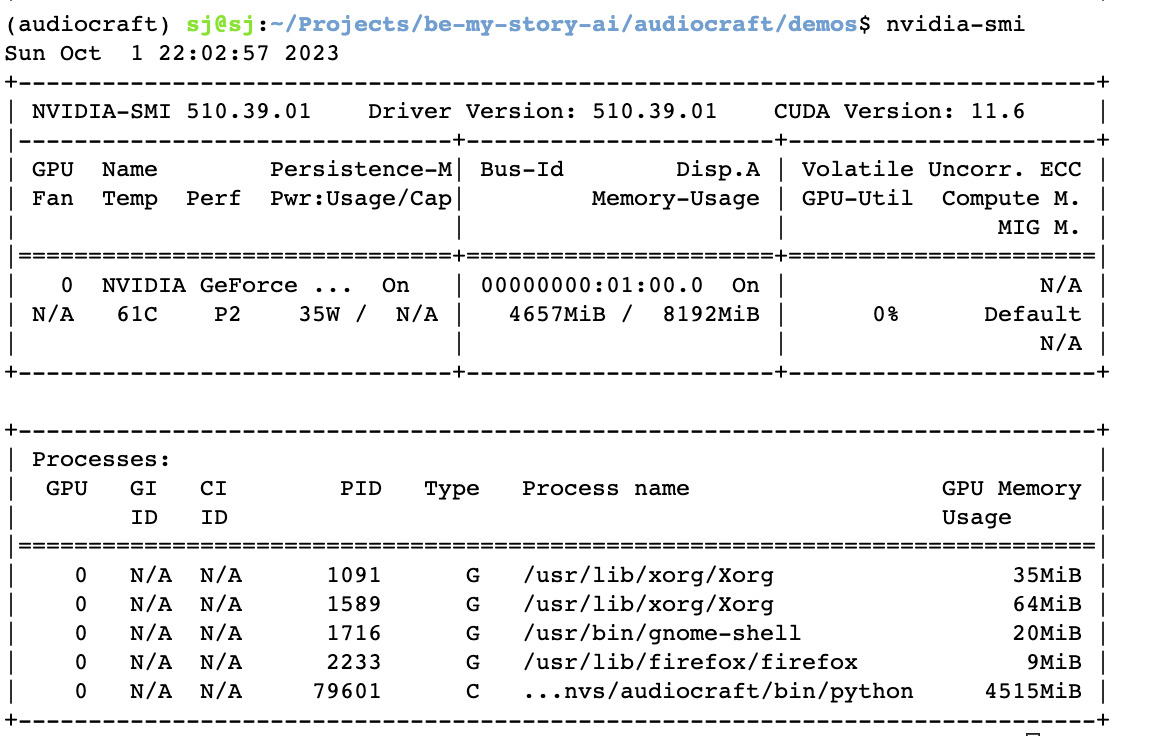
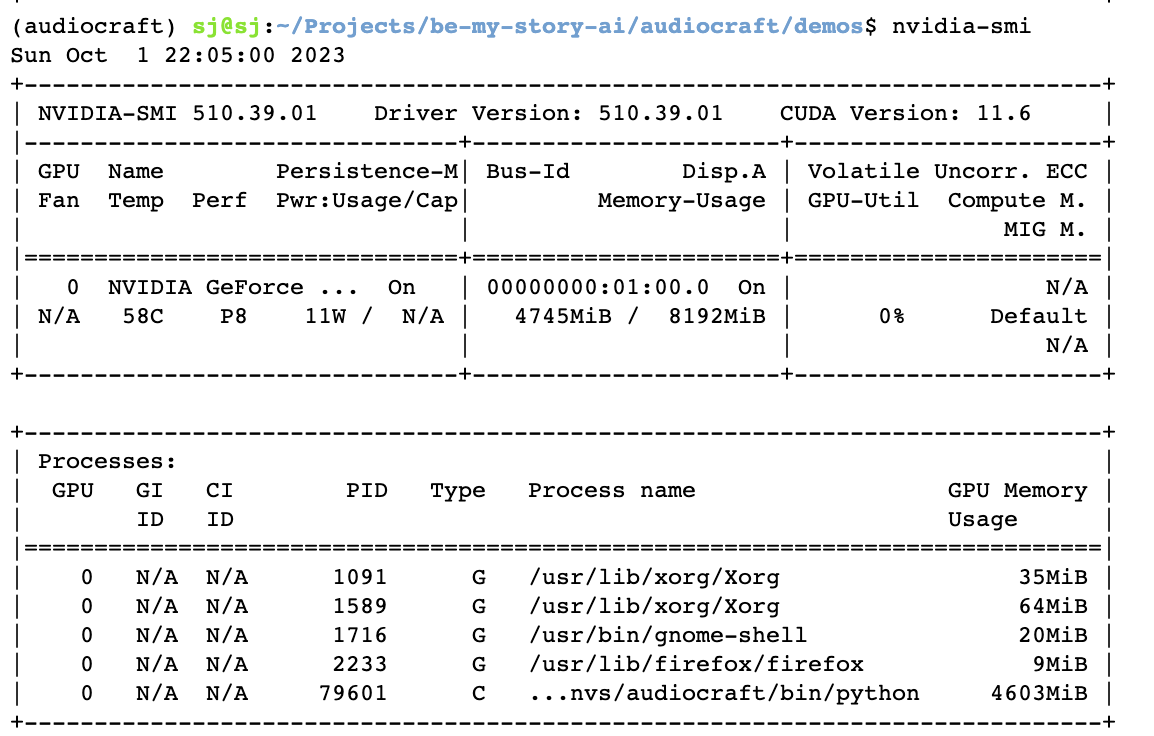
실행할 때 프로세스에 할당된 GPU Memory가 실행 후에도 계속 사용되는 문제가 있었다.
다음 세 가지 방법을 적용하였다.
- inference 시 gradient 계산을 하지 않도록
torch.no_grad()를 설정 - 안 쓰는 tensor 객체를 바로
del하여 gpu cache를 비우기 - garbage collection 소환 후 gpu cache 비우기
import gc
with torch.no_grad(): # gradient 계산 하지 않음
# wav 생성
outputs = model.generate(
descriptions=[prompt],
progress=True, return_tokens=True
)
wav = outputs[0][0].detach().cpu().float()
assert wav.dtype.is_floating_point
if wav.dim() == 1:
wav = wav[None]
elif wav.dim() > 2:
raise ValueError("Input wav should be at most 2 dimension.")
assert wav.isfinite().all()
del outputs, wav # 안 쓰는 tensor 객체 gpu cache를 비우기
gc.collect() # garbage collection 소환 후,
torch.cuda.empty_cache() # gpu cache를 비우기그 결과, 다음과 같이 MusicGen 모델 Inference 하는 동안 VRAM의 사용량이 2000MB 이상까지 치솟았다가, Inference 후 VARM의 사용량이 원래대로 돌아갔다.
S3에 이미지, 음성 저장
tqdm, boto3, pillow 설치
pip install tqdm boto3
pip install pillowS3 연결
import uuid
import io
import boto3
from botocore.exceptions import ClientError
from tempfile import NamedTemporaryFile
from PIL import Image
import torchaudio
with open('secrets.json') as f:
secrets = json.loads(f.read())
BUCKET_NAME = secrets['aws_s3_bucket']
ACCESS_KEY = secrets['aws_access_key']
SECRET_KEY = secrets['aws_secret_key']
LOCATION = secrets['aws_s3_location']
S3_URL = f'https://{BUCKET_NAME}.s3.{LOCATION}.amazonaws.com'
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY
)읽기 가능한 파일 객체를 S3에 업로드
buffer에 바이너리모드 파일 객체를 담아 S3에 업로드하는 방식이다.
object_name = str(uuid.uuid1()) + '.jpg'
file = requests.get(dalle_url).content # 텍스트가 아닌 바이너리모드로 열린 파일 객체
try:
s3_client.upload_fileobj(
io.BytesIO(file),
BUCKET_NAME,
object_name
)
except ClientError as e:
return None저장된 이미지 객체를 webp 포맷으로 S3에 업로드
임시 파일을 만들 때 사용하는 모듈 tempfile을 사용하여, 생성된 이미지 파일은 webp 포맷으로 서버에 저장되어 S3에 업로드된 뒤, 함수 실행 후 서버에서 삭제된다.
image.save()를 사용하여, 바이너리모드로 열린 파일 객체를 이미지 파일로 저장한다.
object_name = str(uuid.uuid1()) + '.webp'
file = requests.get(dalle_url).content # 텍스트가 아닌 바이너리모드로 열린 파일 객체
image = Image.open(io.BytesIO(file))
with NamedTemporaryFile("wb", suffix=".webp", delete=False) as file:
image.save(file.name, format="webp") # 바이너리모드로 열린 파일 객체를 이미지 파일로 저장한다.
try:
s3_client.upload_file(
file.name,
BUCKET_NAME,
object_name
)
except ClientError as e:
return NonePyTorch에서 생성된 음성을 wav 포맷으로 S3에 업로드
공식문서에 따르면, PyTorch에서 생성된 음성은 torchaudio.save() 의 src 매개변수에 Tensor 객체로 인자로 전달하여 저장할 수 있다.

다음 코드에서 torchaudio.save() 함수를 사용하여, PyTorch에서 생성된 WAV-formatted Tensor 객체 wav를 음성 파일로 저장한다.
with NamedTemporaryFile("wb", suffix=".wav", delete=False) as file:
torchaudio.save(file.name, wav, sample_rate=sample_rate, format='wav')
try:
s3_client.upload_file(
file.name,
BUCKET_NAME,
object_name
)
except ClientError as e:
return None3-(b) 최종적으로 완성된, MusicGen으로 배경음악 생성 함수
ChatGPT로 생성된 프롬프트를 입력받아 MusicGen으로 배경음악을 생성하여 반환하는 함수이다.
def prompt_to_music(prompt, sample_rate=32000):
object_name = str(uuid.uuid1()) + '.wav'
with torch.no_grad():
# wav 생성
outputs = model.generate(
descriptions=[
prompt
],
progress=True, return_tokens=True
)
wav = outputs[0][0].detach().cpu().float()
assert wav.dtype.is_floating_point, "wav is not floating point"
if wav.dim() == 1:
wav = wav[None]
elif wav.dim() > 2:
raise ValueError("Input wav should be at most 2 dimension.")
assert wav.isfinite().all()
# s3에 저장
with NamedTemporaryFile("wb", suffix=".wav", delete=False) as file:
torchaudio.save(file.name, wav, sample_rate=sample_rate, format='wav')
try:
s3_client.upload_file(
file.name,
BUCKET_NAME,
object_name
)
except ClientError as e:
return None
del outputs, wav
gc.collect()
torch.cuda.empty_cache()
music_url = f"{S3_URL}/{object_name}"
return music_url➡️ 동화책 배경음악 생성 API
POST /music
Request Body (동화 텍스트)
{
"texts": [
"한참 연습한 끝에, 고양이는 저녁에 자전거를 타고 마을을 돌아다녔어요. 처음에는 좀 허덕이긴 했지만, 결국에는 잘 탈 수 있게 되었어요. 고양이가 자전거를 잘 타니까, 엄마와 아빠가 산책을 갈 때마다 나도 함께 가야겠다고 생각했어요.",
"그런데 고양이에게는 자전거 타기보다 더 큰 꿈이 있었어요. 고양이는 우주선을 타고 우주로 떠나는 모험을 꿈꾸었어요. 별들과 함께 모험하고, 다른 행성들을 탐험하며, 우주에서 재미있는 일을 할 수 있다는 게 고양이의 꿈이었어요.",
"고양이는 그날 밤, 잠들기 전에 별들을 보면서 꿈을 꾸었어요. 그리고 고양이 앞에 아름다운 우주선이 나타났어요. 고양이는 설레임을 감출 수 없었어요. 그래서 우주선에 올라타고, 무한한 우주로 향해 모험을 시작했어요.",
"고양이는 우주에서 처음으로 보는 행성들을 만났어요. 녹색 풀로 덮인 행성에서 꽃들과 놀고, 파란 바다가 펼쳐진 행성에서 아름다운 물고기들을 볼 수 있었어요. 그리고 또 다른 행성에서는 작은 우주 생물들과 친구가 되어 함께 놀았어요.",
"우주선을 타고 여러 행성들을 방문하면서, 고양이는 우주 다른 생물들과 어울리며 새로운 친구들을 사귀었어요. 함께 놀고 웃으면서, 고양이는 매 순간이 행복했어요.",
"하지만 언젠가는 고양이는 집으로 돌아와야 했어요. 그래서 고양이는 우주선을 타고 지구로 돌아왔어요. 엄마와 아빠에게 모험 이야기를 들려주었고, 그들은 미소 짓더라구요.",
"이후로도 고양이는 자전거를 타면서 언제든 우주 모험을 꿈꿀 수 있었어요. 그리고 고양이는 항상 다른 행성들을 상상하고 모험을 즐길 수 있었어요."
]
}
Response Body (BGM)
{
"musicUrl": "https://bemystory-s3-data.s3.ap-northeast-2.amazonaws.com/b521c298-82f1-11ee-a704-7b2ff80a7a30.wav"
}@app.post("/music")
async def story_to_music(story_text: StoryText):
texts = "\n".join(story_text.texts)
prompt = story_to_music_prompt(texts)
music_url = prompt_to_music(prompt)
return Music(musicUrl=music_url)
생성된 동화책 예시
입력한 일기
- 주인공 이름: "고양이",
- 일기 내용: "오늘 밤에 자전거를 탔다. 자전거는 처음 탈 때는 좀 중심잡기가 힘들었다. 그러나 재미있었다. 자전거를 잘 타서 엄마, 아빠 산책 갈 때 나도 가야겠다."
- 키워드: "우주"
표지
제목: "우주 모험, 자전거 꿈"

배경음악
https://bemystory-s3-data.s3.ap-northeast-2.amazonaws.com/b521c298-82f1-11ee-a704-7b2ff80a7a30.wav
이야기

"한참 연습한 끝에, 고양이는 저녁에 자전거를 타고 마을을 돌아다녔어요. 처음에는 좀 허덕이긴 했지만, 결국에는 잘 탈 수 있게 되었어요. 고양이가 자전거를 잘 타니까, 엄마와 아빠가 산책을 갈 때마다 나도 함께 가야겠다고 생각했어요."

"그런데 고양이에게는 자전거 타기보다 더 큰 꿈이 있었어요. 고양이는 우주선을 타고 우주로 떠나는 모험을 꿈꾸었어요. 별들과 함께 모험하고, 다른 행성들을 탐험하며, 우주에서 재미있는 일을 할 수 있다는 게 고양이의 꿈이었어요."

"고양이는 그날 밤, 잠들기 전에 별들을 보면서 꿈을 꾸었어요. 그리고 고양이 앞에 아름다운 우주선이 나타났어요. 고양이는 설레임을 감출 수 없었어요. 그래서 우주선에 올라타고, 무한한 우주로 향해 모험을 시작했어요."

"고양이는 우주에서 처음으로 보는 행성들을 만났어요. 녹색 풀로 덮인 행성에서 꽃들과 놀고, 파란 바다가 펼쳐진 행성에서 아름다운 물고기들을 볼 수 있었어요. 그리고 또 다른 행성에서는 작은 우주 생물들과 친구가 되어 함께 놀았어요."

"우주선을 타고 여러 행성들을 방문하면서, 고양이는 우주 다른 생물들과 어울리며 새로운 친구들을 사귀었어요. 함께 놀고 웃으면서, 고양이는 매 순간이 행복했어요."

"하지만 언젠가는 고양이는 집으로 돌아와야 했어요. 그래서 고양이는 우주선을 타고 지구로 돌아왔어요. 엄마와 아빠에게 모험 이야기를 들려주었고, 그들은 미소 짓더라구요."

"이후로도 고양이는 자전거를 타면서 언제든 우주 모험을 꿈꿀 수 있었어요. 그리고 고양이는 항상 다른 행성들을 상상하고 모험을 즐길 수 있었어요."
cf. secrets.json 설정
깃허브에 비밀 정보들을 노출하지 않기 위해서 .gitignore 파일에 secrets.json을 설정한다.
app/secrets.jsonsecrets.json에 비밀 정보들를 저장하고 코드에서 다음과 같이 읽고 사용한다.
import json
with open('secrets.json') as f:
secrets = json.loads(f.read())졸프를 마무리하며

