
Inception
2014년에 개최된 ILSVRC에서 우승을 한 모델은 GoogLeNet이다. 이후 Inception이란 이름으로 논문을 발표했다. (즉, Inception V1이 GoogLeNet이다.)
그러나 이 대회에서 우승을 한 GoogLeNet이 실제로 구현하기가 어려워, 준우승을 한 VGG 모델이 더 많이 쓰였다. 이에 GoogLeNet에 변형을 가해 Inception v2와 v3가 나오게 되었다.

Inception V1
그러면 인센셥 버전 원이 나오게 된 흐름을 살펴보자.
인셉션의 기본 아이디어는 CNN의 네트워크를 깊어지게 하자는 것이다.
이렇게 CNN에서 네트워크가 깊어지게 만들면, 일반적으로 성능이 좋아진다.
그러나 overfitting, Vanishing Gradient Problem을 비롯하여 학습해야하는 파라미터의 수가 늘어나 총 학습시간, 연산속도 증가 등의 문제점이 발생한다.
따라서 Dropout을 사용하여 네트워크처럼 sparse하게 연결되는 구조를 만들어 이를 해결하고자 하였으나, 컴퓨터의 연산은 Dense할수록 빠르기 때문에 이는 효율적인 방법이라고 볼 수 없었다. 이에 나오게 된 것이 Inception이다.

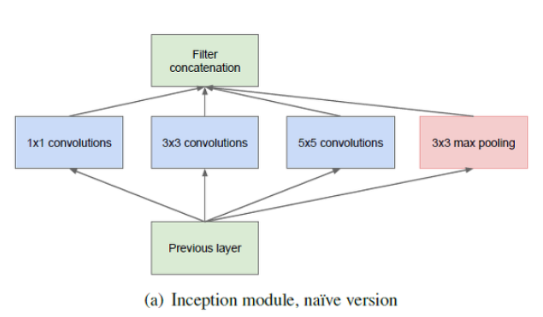
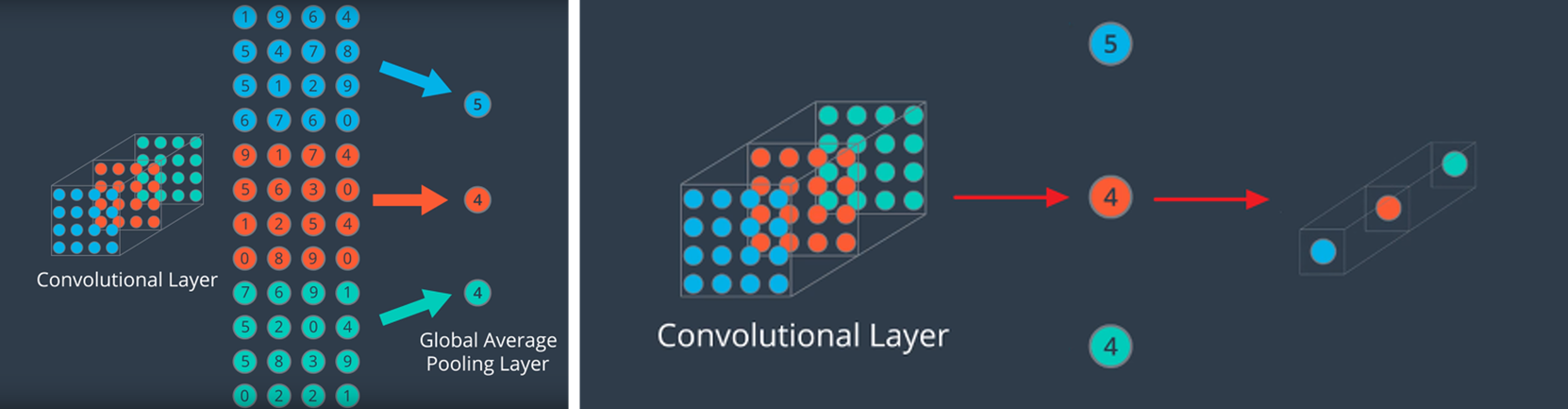
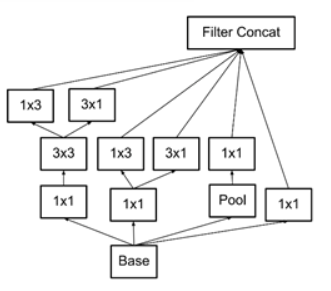
Inception 모듈에서는 feature를 효율적으로 추출하기 위해 1x1, 3x3, 5x5의 Convolution 연산을 각각 수행한다. 3x3의 Max pooling 또한 수행하는데, 입력과 출력의 H, W가 같아야하므로 Pooling 연산에서 적절히 Padding을 추가해준다.
feature 추출 등의 과정은 최대한 sparse함을 유지하고자 했고, 행렬 연산은 이들을 합쳐(concat) 최대한 dense하게 만들고자 했다.
그러나 이렇게 되면 연산량이 너무 많아지게 된다.
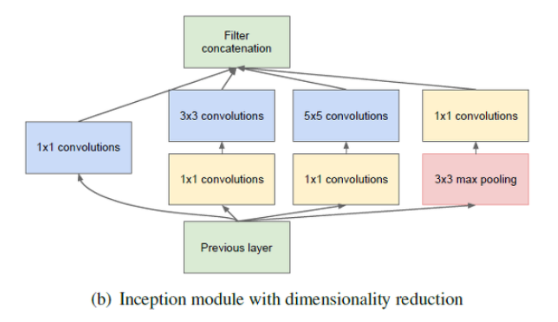
이를 해결하기 위해서 Inception v1은 1x1 Conv를 사용해 dimension reduction을 수행한다.
1x1 Conv 의 효과
① channel 수 조정
Convoultion layer를 사용할 경우, channel의 수는 하이퍼파라미터로 사람이 직접 결정해 주어야 한다. 따라서 1x1 Conv 연산을 하면 channel의 수를 마음껏 조절할 수 있다.
② 계산량 감소
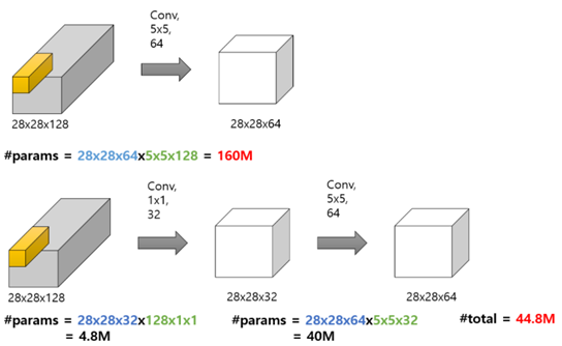
이미지 출처: https://hwiyong.tistory.com/45
③ 비선형성
1x1 Conv 사용 후, 활성화 함수로 ReLU를 사용하여 모델에 비선형성을 증가시켜준다. 따라서 복잡한 패턴을 더 잘 인식할 수 있게 된다.
즉, 1x1 Conv에 넣어 channel을 줄였다가, 3x3나 5x5 Conv를 거치게해 다시 확장하는 느낌이다. 이렇게 되면 필요한 연산의 양이 크게 줄어들게 된다.
또한 max Pooling의 경우 연산 결과의 채널 수가 입력과 동일하므로, 1x1 Conv를 뒤에 붙여 출력의 채널 수를 맞추어주었다. 이렇게 sparse하게 각 연산을 거친 다음, 이들을 합쳐 dense한 output을 만들어내는데, 이때 H와 W는 모두 동일하다는 것에 주의해야한다.
global average pooling
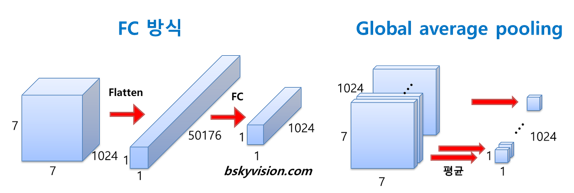
AlexNet, VGGNet 등에서는 fully connected (FC) 층들이 망의 후반부에 연결되어 있다.
그러나 GoogLeNet은 FC 방식 대신에 global average pooling이란 방식을 사용한다.
global average pooling은 전 층에서 산출된 특성맵들을 각각 평균낸 것을 이어서 1차원 벡터를 만들어주는 것이다. 1차원 벡터를 만들어줘야 최종적으로 이미지 분류를 위한 softmax 층을 연결해줄 수 있기 때문이다. 만약 전 층에서 1024장의 7 x 7의 특성맵이 생성되었다면, 1024장의 7 x 7 특성맵 각각 평균내주어 얻은 1024개의 값을 하나의 벡터로 연결해주는 것이다.
이렇게 해줌으로 가중치의 갯수를 상당히 많이 없앨 수 있다. 만약 FC 방식을 사용한다면 훈련이 필요한 가중치의 갯수가 7 x 7 x 1024 x 1024 = 51.3M이지만 global average pooling을 사용하면 가중치가 필요하지 않다.
이미지 출처: https://kevinthegrey.tistory.com/142
최종 Inception V1 모델의 구조
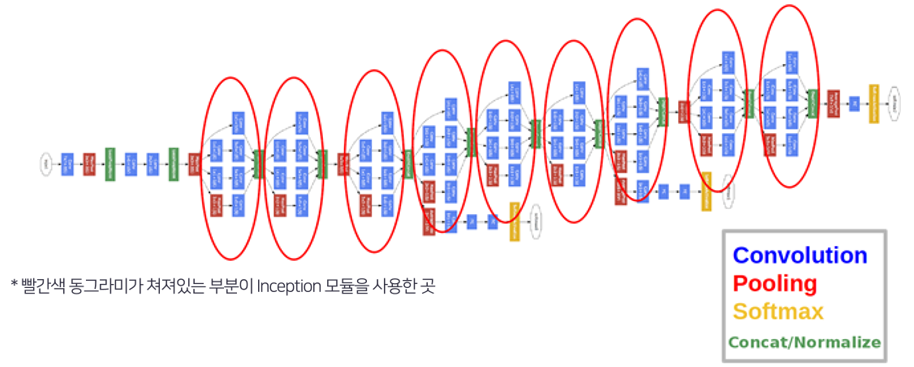
- 네트워크의 얕은 부분, 즉 입력과 가까운 부분에는 Inception 모듈을 사용하지 않았다.
논문에 따르면 이 부분에는 Inception의 효과가 없었다고 한다. 따라서 우리가 일반적으로 CNN하면 떠올리는, Conv와 Pooling 연산을 수행한다. - softmax를 통해 결과를 뽑아내는 부분이 맨 끝에만 있는 것이 아니라, 중간 중간에 있다는 점이다. 이를 auxiliary(보조의) classifier라고 한다.
이렇게 auxiliary classifier를 덧붙이면, Loss를 맨 끝뿐만 아니라 중간 중간에서 구하기 때문에 gradient가 적절하게 역전파되어 Vanishing Gradient를 방지할 수 있다. 대신 이 auxiliary classifier가 지나치게 영향을 주는 것을 막기 위해 0.3을 곱하여 사용한다.
Inception V2로의 발전
3x3 Conv 필터 사용
VGG 모델의 핵심이었던 3x3 Conv 필터 사용을 기존의 Inception V1 모델에 적용하였다.
이 3x3 Conv의 장점을 다음의 예시로 살펴보자.
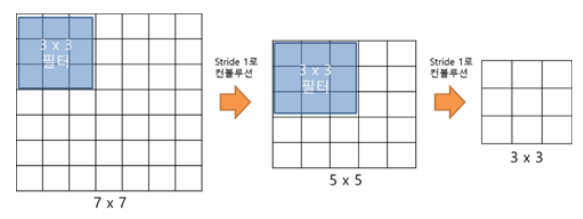
3 x 3 필터로 세 차례 컨볼루션 하는 것은 7 x 7 필터로 한 번 컨볼루션 하는 것과 동일하다.
그러나 3 x 3 필터가 3개면 총 27개의 가중치를 갖는 반면 7 x 7 필터는 49개의 가중치를 갖는다.
이미지 출처: https://bskyvision.com/504
따라서 다음의 그림처럼 기존의 5x5 conv를 3x3 conv 2번으로 바꾸면 파라미터 개수가 25에서 18이 되어 약 28%의 reduction 효과가 있다.
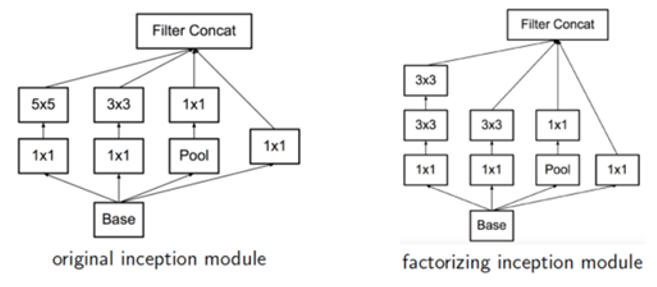
Factorization 사용
일반적으로 n x n 의 형태로 Conv 를 수행하게 되는데, 이를 1xn과 nx1 Convolution으로 분해 할 수 있다.
이러한 기법을 Factorization이라고 한다. 이렇게 하게 되면 n x n개의 파라미터가 n+n개로 되어 큰 절감효과를 얻을 수 있다.
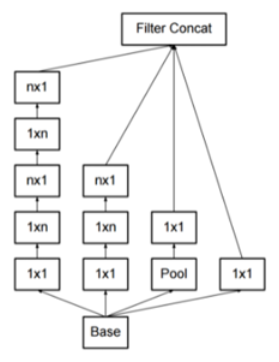
stride 2 적용
stride 2를 적용해서 이미지 사이즈와 계산량을 줄이도록 하였다.
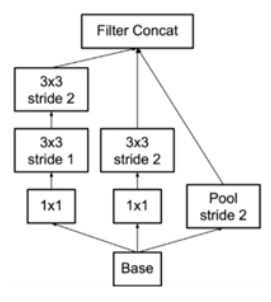
++ Inception v1 에서는 맨 마지막 softmax 말고도 추가로 2개의 Auxiliary Classifiers로 softmax 를 사용했었다. 이때 inception v1의 초반부에 있던 보조 분류기는 성능에 영향을 끼치지 않는 게 확인되어 삭제되었다.
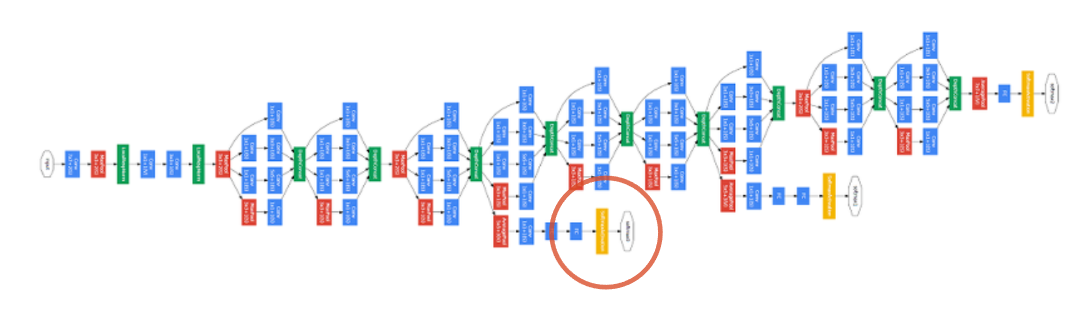
최종 Inception V2 모델의 구조
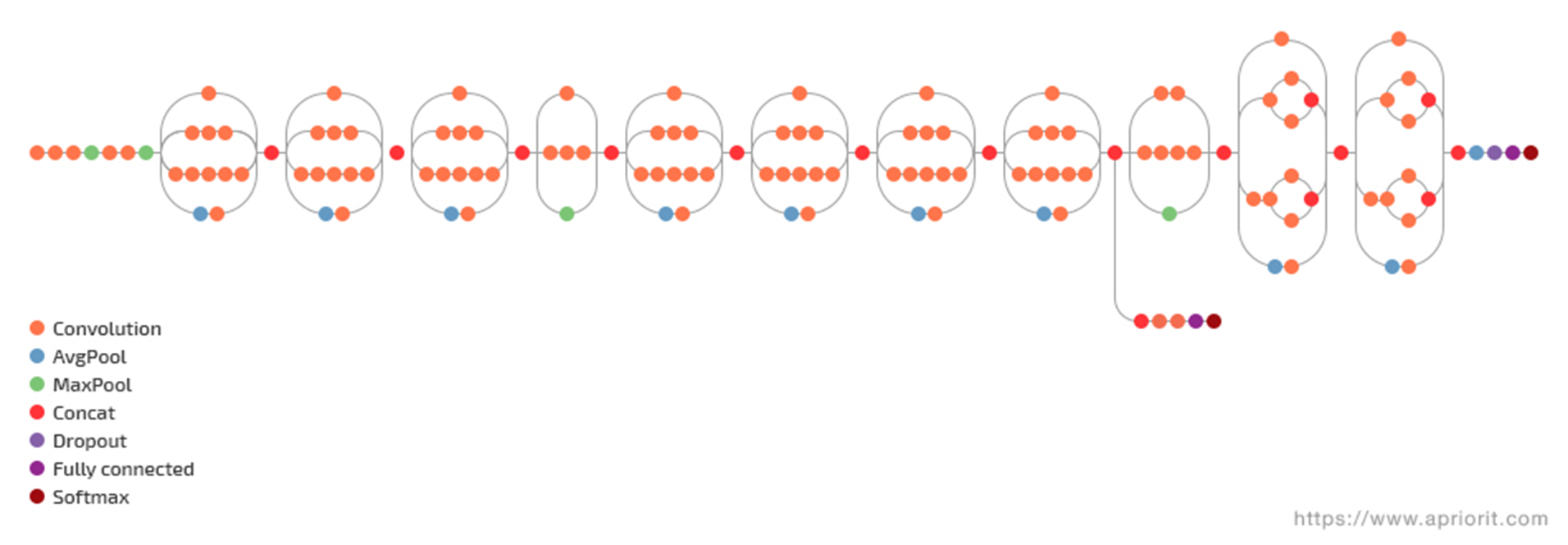
++ 이때, 맨 마지막의 pooling 앞에서 사용되는 inception block은 다음과 같다.
Inception v2 수정사항 정리
- 3x3 Conv 필터 사용 => 연산량 절감
- n x n 의 형태의 Conv를 1xn과 nx1 Convolution으로 분해 => 연산량 절감
- inception v1의 초반부에 있던 보조 분류기 삭제
- stride 2를 사용 => 이미지 사이즈 축소, 계산량 절감
Inception V3로의 발전
RMSProp Optimizer 사용
이때 RMSProp는 많이 변화한 변수는 최적값에 근접했을 것이라는 가정을 하며, 업데이트 횟수에 따라 학습률을 조절하는 Adagrad에 지수 가중 이동 평균의 컨셉을 사용하여 최신 기울기들이 더 크게 반영되도록 한 것이다.
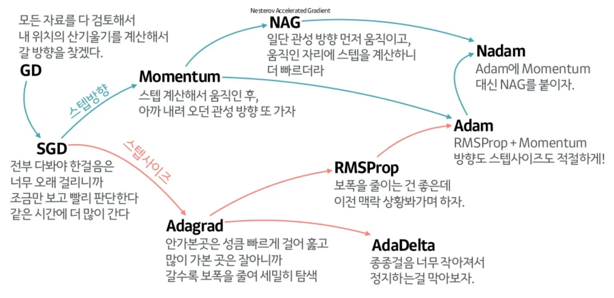
이미지 출처: https://www.slideshare.net/yongho/ss-79607172
Label Smoothing을 사용
Hard label(One-hot encoded vector로 정답 인덱스는 1, 나머지는 0으로 구성)을 Soft label(라벨이 0과 1 사이의 값으로 구성)로 스무딩하는 것을 의미한다. 즉, 레이블을 부드럽게 깎아서 일반화 성능을 높이고자 하는 것이다.
K개의 클래스에 대해서, 스무딩 파라미터(Smoothing parameter)를 α라고 할 때, k번째 클래스에 대해서 다음과 같이 스무딩을 한다.
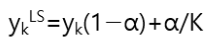
이렇게 하게 되면 보다 더 일반화 성능을 향상시킬 수 있다는 장점이 있다.
Batch Normalization을 적용
일반적으로 정규화를 하는 이유는 학습을 더 빨리 하기 위해서 또는 Local optimum 문제에 빠지는 가능성을 줄이기 위해서 사용한다.
다음 그림과 같이 정규화를 통해 왼쪽에서 오른쪽으로 만들어, local optimum 에 빠질 수 있는 가능성을 낮춰주게 된다.
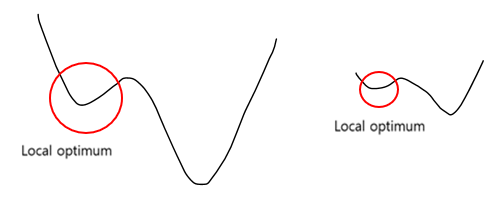
이렇게 하게 되면 vanishing gradient 문제를 해결하며 학습속도 또한 감소되게 된다.
이 Batch Normalization을 네트워크에 적용시킬 때는, 특정 Hidden Layer에 들어가기 전에 Batch Normalization Layer를 더해주어 input을 modify해준 뒤 새로운 값을 activation function으로 넣어주는 방식으로 사용한다. 이때, 활성화 함수에 원래는 Wx+b 형태로 weight를 적용시키는데, Batch Normalization을 사용하고 싶을 경우 normalize 할 때 beta 값이 바이어스의 역할을 대체할 수 있기 때문에 b를 없애준다. 결과적으로 Wx에 대해 Batch Normalization을 한 후, activation function을 적용하게 된다.
알고리즘의 개요는 다음과 같다.

Training 할 때는 mini-batch의 평균과 분산으로 normalize 하고, scale factor(감마)와 shift factor(베타)를 이용하여 새로운 값을 만든다.
이때 감마와 베타는 다른 레이어에서 weight를 학습하듯이 역전파에서 학습하면 된다.
Test 할 때는 training할 때 계산해놓은 값의 이동 평균으로 normalize 한다.
(각 iteration 당 평균과 분산이 있었는데, 이를 총 iteration으로 평균을 낸다. 이때 분산의 평균에는 m/(m-1)을 곱하여 준다.)
[자습용 참고 자료]
Batch Normalization 참고 영상
