오늘은 자료구조 PART01 연결리스트에 관해 알아봤습니다.😀
목차
- 연결리스트의 개념
- 연결리스트의 종류
2-1 단순연결리스트
2-2 원형 연결리스트
2-3 이중 연결리스트
2-4 이중 원형 연결리스트
1. 연결리스트의 개념

정의
① 연결리스트는 첫 번째 노드를 가리키는 헤드 포인터가 필요하다
② 포인터가 다음 노드의 위치를 가리키는 구조로, 전체 노드는 논리적으로 서로 연결된 상태
③ 마지막 노드는 노드의 포이터를 Nil or Null이라 한다
④ 각각 노드는 기억장소에서 서로 이웃할 필요 없다 = 물리적으로 연속적x
⑤ 링크필드로 인한 기억공간이 많이 필요하며, 알고리즘 구현이 복잡하고 탐색시, 비효율적이다.
노드란?🧐
자기자신을 참조하는 구조체를 이용해 정의한다 (data필드+포인터 저장된 link필드)
2. 연결리스트의 종류
2-1. 단순연결 리스트

① 거꾸로 갈 수 있는 방법은 없다. 탐색시간은 포인터를 이용해 순차적, 시간복잡도 O(n)
② 노드를 삽입, 삭제의 경우 선행 노드를 알고 있어야한다.
③ 특정 노드 액세스를 위해서는 처음 노드부터 검색한다.
단순연결 리스트 삽입
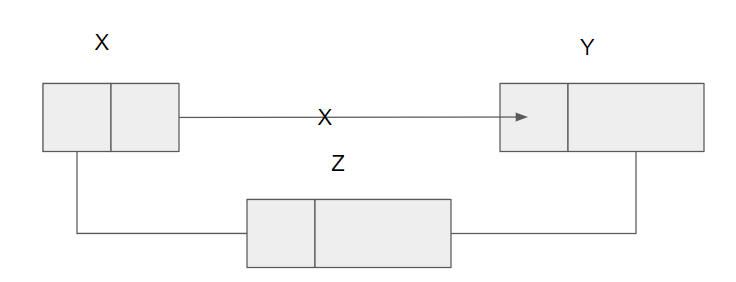
코드
procedure INSERT(Head,item,Y)
/* Y: 삽입할 노드 , X : 삽입 후, Y의 선행 노드 */
call GETNODE(Y)
/* Y노드 생성 */
DATA(Y) ← item
/*Y노드에 데이터 값 저장 */
if(Head=nill) then Head ← Y
LINK(Y) ← nill
/* Head가 NULL인 경우, Head가 Y를 가리키도록하라 */
else LINK(Y) ← LINK(X)
LINK(X) ← Y
/* 마지막 노드는 항상 NULL */
end INSERTvoid insert(listPointer *first, listpointer x)
{
listPointer temp;
MALLOC(temp, sizeof(*temp));
temp →data =50;
if(*first){
temp → link = x → link;
x→ link = temp;
}
else{
temp →link =NULL;
*first =temp;
}
}
단순연결 리스트 삭제
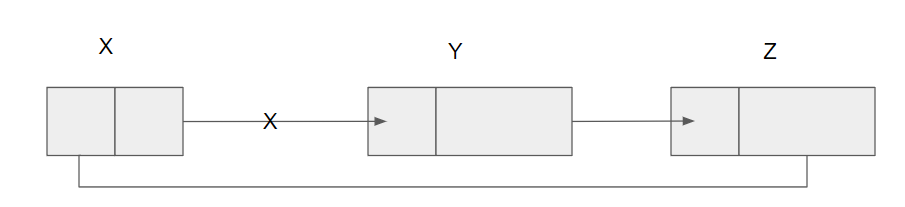
코드
procedure DELETE(X,Y,Head)
/* Y: 삭제할 노드 X: Y의 선행노드*/
if(Head=nil) call List-empty
if(X=nil) then Head ← LINK(Head)
/* 첫번째 노드 삭제 */
else LINK(X) ←LINK(Y)
/*중간 노드 삭제*/
call RET(Y)
end DELTEvoid delete(listPinter *first,listPinter trail,listPinter node){
/* 리스트로부터 노드를 삭제, trail은 삭제될 x의 선행 노드, first는 리스트의 시작 */
if(rail)
trail →link = x →link;
else
*first= (*first) → link;
free(x);
}2-2. 원형 연결리스트

정의
① 마지막 노드가 null link 대신 리스트의 처음 노드의 포인트를 가진다.
② 마지막 노드를 변경하기 위해서는 마지막을 찾을 때 까지 모든 노드 탐색
③ head가 마지막을 가리킬 경우, 길이에 상관없이 첫 번째 앞 마지막 노드 위에 일정한 시간으로 노드를 삽입하 수 있다.
장단점
장점
- 어느 한 노드로부터 다른 모든 노드에 접근 가능
- 임의의 노드 검색 시 현재노드 부터 검색 가능
단점
- 노드 검색 시 무한루프에 빠질 수 있다.
- 무한루프 문제는 head 포인터를 두어 방지 가능하다.
노드삽입
- 앞에 삽입
procedure INSERT(T,Y) //T는 마지막 노드를 가리킨다.
if T = nill then T ← Y // 리스트가 빈 상태로 T가 Y를 지시
LINK(Y)← T //Y는 자기자신을 가리킨다.
else LINK(Y) ← LINK(T)// 새 리스트가 첫 번째 노드를 지시
LINK(T)←Y // 마지막 노드의 링크필드가 새 노드를 지시
end INSERT① 원형 리스트가 빈 상태로 T가 새로운 노드 Y를 가리킨다
② 새 노드의 Y의 링크 필드가 첫 번째 노드를 가리키게한다
③ 마지막 노드의 링크 필드가 새로운 노드 Y를 가리키게 한다.
void insertFront(listPinter last, listPPinter node){
if(!(*last)){ //공백일 경우, last가 새로운 항목을 가리키도록 한다.
*last =node;
node → link=node;
}
else{// 공백이 아닌 경우, 리스트 앞에 새로운 항목 삽입
node → link = (*last) →link;
(*last)→link=node;
}
}2-3. 이중 연결리스트

정의
① 원형리스트의 뒤로 순화할 수 없다는 점과 삭제의 번거로움의 단점을 보완했다
② 어떤 노드에 대해 다음 노드 뿐만 아니라 전 노드까지 알수 있도록 하여 양방향 탐색 가능
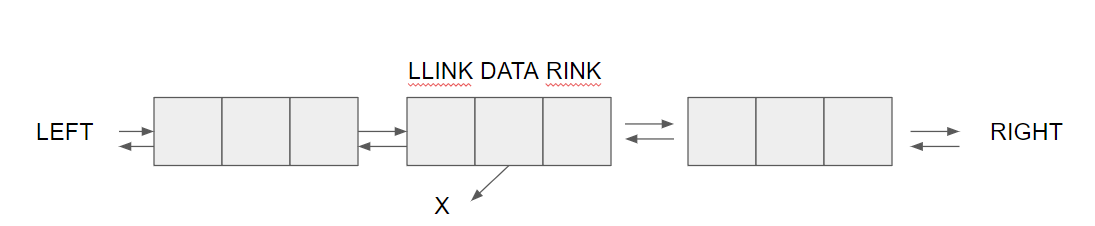
③각 노드에 좌 우측2개의 포인터가 있으며, 각 포인터는 각각 좌우 노드를 가리키는 형태이다
④운영체제의 동적 메모리 관리에 적합하다.
- X = RLINK(LLINK(X)) = LLINK(RLINK(X))
장점
- 양방향 검색이 가능해 속도가 빠르고 선행노드 검색이 쉽다
- 한 노드의 포인터 파괴시, 복구 가능
- 리스트 운행에 따른 알고리즘이 간단하다
단점
- 두 개의 링크를 저장할 기억공간이 낭비된다.
2-4. 이중 원형 연결리스트

정의
마지막 노드의 RLINK는 처음 노드를 가리키게 하고 처음 노드의 LLINK는 마지막 노드를 가리킨다
장점
- 마지막 노드까지 데이터 저장 시, 빈 노드를 찾아 입력할 수 있는 융통성 부여
- 무한루프에 빠지는 것을 방지
단점
- 알고리즘 구현의 복잡성
Head노드란?🧐
데이터를 가지지 않고, 삽입 삭제 코드를 간단하게 할 목적으로 만들어진 노드
가지고 있는 내용
- 첫 번째 노드 포인터
- 리스트 길이
- 마지막 노드 포인터
- 참조계수(자신을 참조하고 있는 포인터 수)
