MBTI 분류기를 구현할 때 메인으로 사용한 SVM을 본 포스트를 통해 자세히 정리해보려 한다.
Support Vector Machine (이하 SVM)은 regression과 classification에 모두 적용될 수 있지만, 보통은 분류작업에 많이 쓰인다고 한다. 데이터양이 한정적인 경우에도 빠른 computational 속도로 분류작업을 처리할 수 있다.
✅ SVM 은 무엇인가?
A support vector machine (SVM) is a supervised machine learning model that uses classification algorithms for two-group classification problems. After giving an SVM model sets of labeled training data for each category, they’re able to categorize new text.
아주 간단히 정리하자면, 분류 알고리즘을 사용하는 지도 (기계)학습 모델이다. 모델이 어떻게 작동하는지 그 메커니즘을 살펴보겠다.
SVM 알고리즘의 목표는 N-차원의 공간에서 hyperplane을 찾는 것인데, 다시 말해 SVM은 data point를 가장 잘 나눌 수 있는 decision boundary을 찾아줄 수 있다.
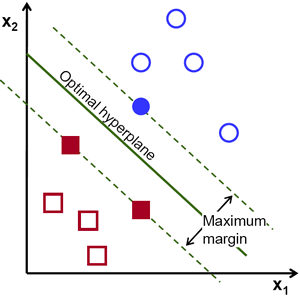
🔼 Best Hyperplane은 margin을 최대화하는 plane이라고 생각하면 된다.
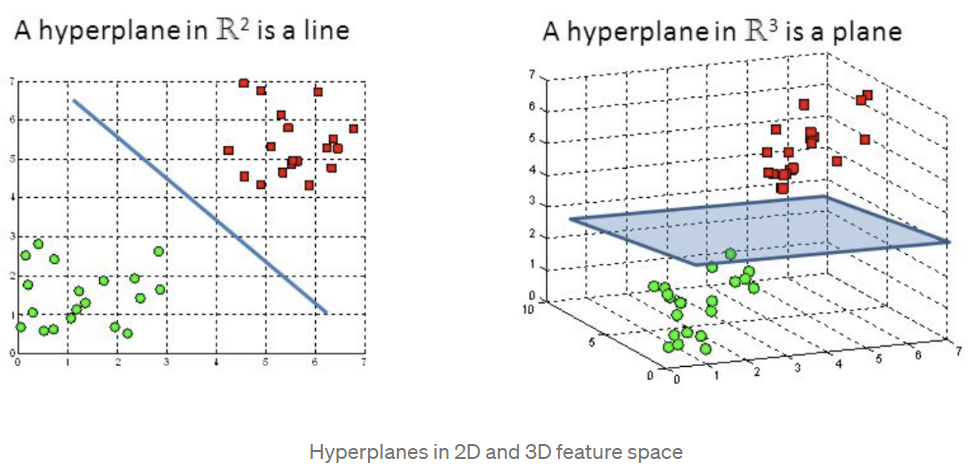
🔼 Feature의 개수에 따라 hyperplane의 형태는 달라진다.
Cost Function

SVM 알고리즘에서는 hinge loss function을 사용해서, data point들과 hyperplane간의 margin을 최대화한다.
예측값과 실제값이 같은 sign인 경우, cost 값이 0이 되고,
그렇지 않은 경우에는 loss value를 계산하게 된다.
위 cost function에 regularization parameter를 더하게 되는데, 이는 margin maximization과 loss의 균형을 맞추기 위해서다. 결과적으로 SVM의 cost function의 형태는 아래와 같아진다.
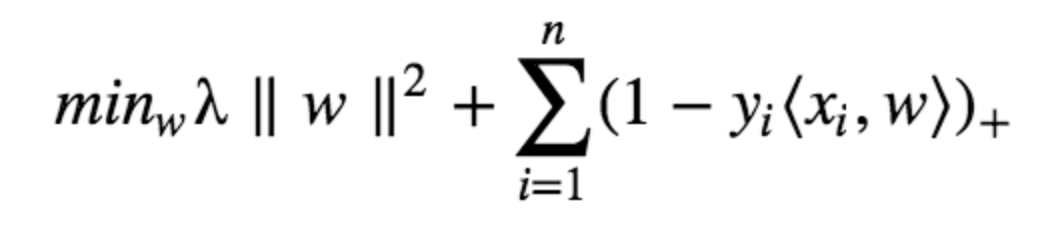
Gradient Updates
Gradient를 찾기 위해 각 weight마다 partial derivatives를 취하게 되는데, 찾은 gradient를 통해 weight를 update할 수 있게 된다.

👉 포스트 상단에 기재한 '사이트2'의 코드를 이용해서 직접 SVM 알고리즘을 구현해보았다. scikit learn의 library로 SVM이 있기 때문에 더욱 쉽게 알고리즘을 적용해볼 수도 있다.
from sklearn.svm import SVC