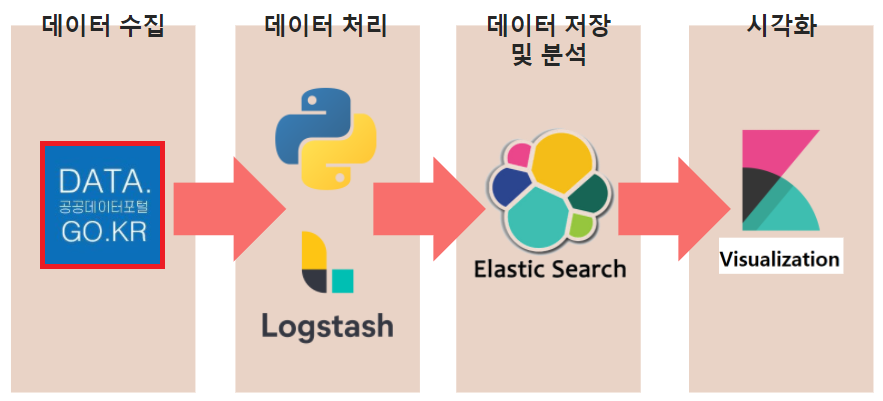
개요
- Data -> Logstash -> Elasticsearch
- 공공 데이터 다운로드 및 정제 개발
Set Up
-
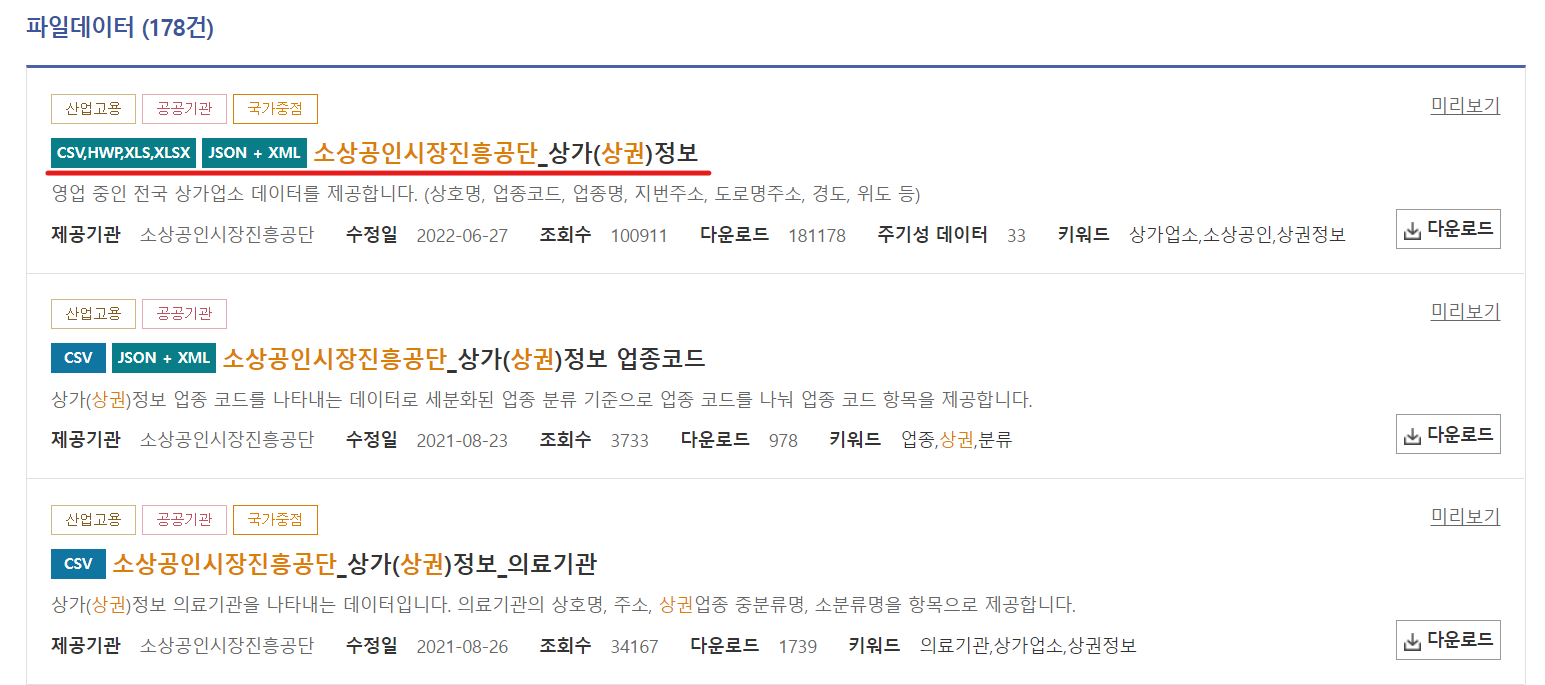
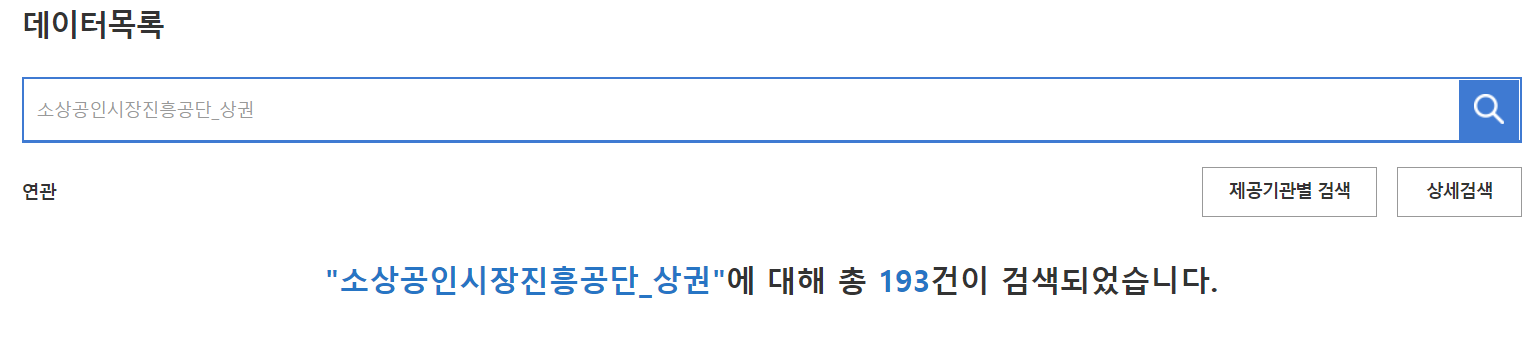
공공데이터 포털에서 '소상공인시장진흥공단_상권' 입력
-
소상공인시장진흥공단_상가(상권)정보 > csv 파일 다운로드
Install
- pandas 라이브러리 설치
pip install pandas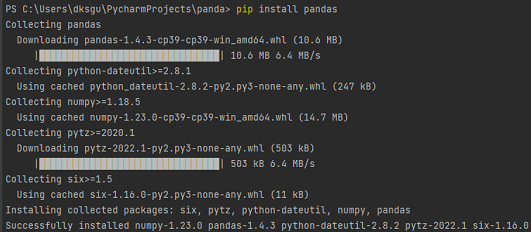
- jupyter 라이브러리 설치
- jupyter notebook 사용 이유
- 셀 단위로 작성하여 실행할 수 있기에 큰 파이썬 파일도 셀 단위로 나누어 번역, 실행하면서 인터랙티브한 동작이 가능
- 데이터 분석을 위한 파이썬 파일 작성 후 실행하였을 때, 차트, 표 등의 결과값 출력도 바로 바로 직관적으로 볼 수 있고, 이후 Github에 주피터 노트북의 결과 출력 방식 그대로 올릴 수 있다
- jupyter notebook 사용 이유
pip install jupyter
jupyter notebookCode
-
csv 파일 읽기
- 데이터의 이름이 커서 깨지게 나오는 모습을 확인할 수 있음


- 데이터의 이름이 커서 깨지게 나오는 모습을 확인할 수 있음
-
csv 파일 컬럼

-
'상호명' 컬럼에 '스타벅스'가 포함된 data 핸들링
- contains 함수는 특정 문자가 포함된 문자열을 뽑음
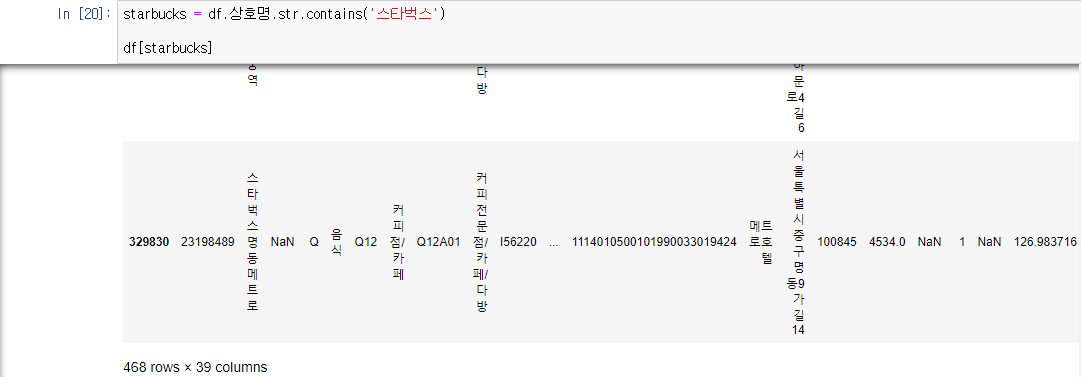
- contains 함수는 특정 문자가 포함된 문자열을 뽑음
-
'상호명' 컬럼에 '이디야'가 포함된 data 핸들링
- contains 함수는 특정 문자가 포함된 문자열을 뽑음
- 이디야 커피는 'EDIYA', '이디야'를 같이 쓰는 모습을 확인할 수 있음


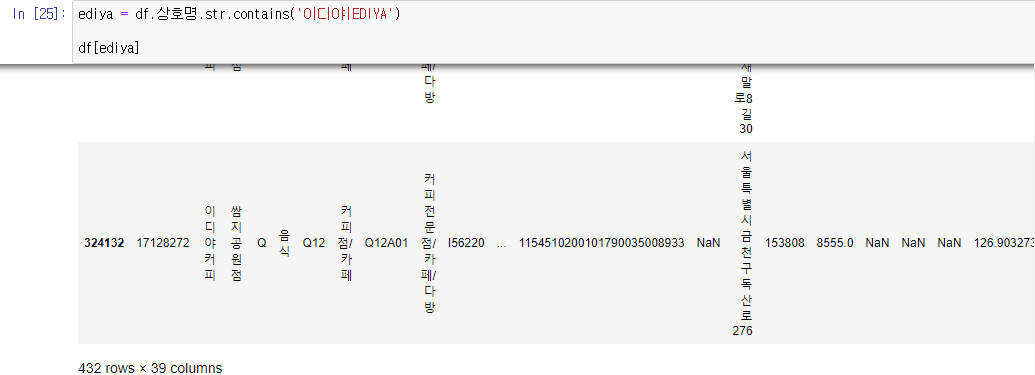
-
Ediya, Starbucks에서 필요한 '위도', '경도' 컬럼만 정제
- rename을 사용하여 '상호명' -> '브랜드명' 으로 변경
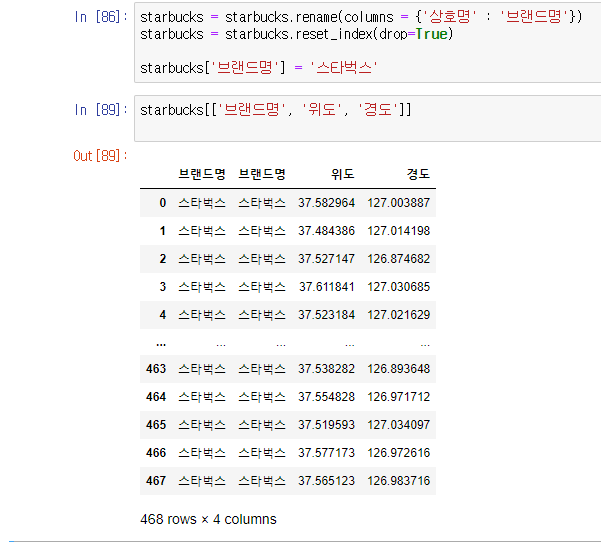
- rename을 사용하여 '상호명' -> '브랜드명' 으로 변경
-
Ediya, Starbucks 병합 및 다운로드
- axis=0이면 아래로, axis=1이면 옆으로
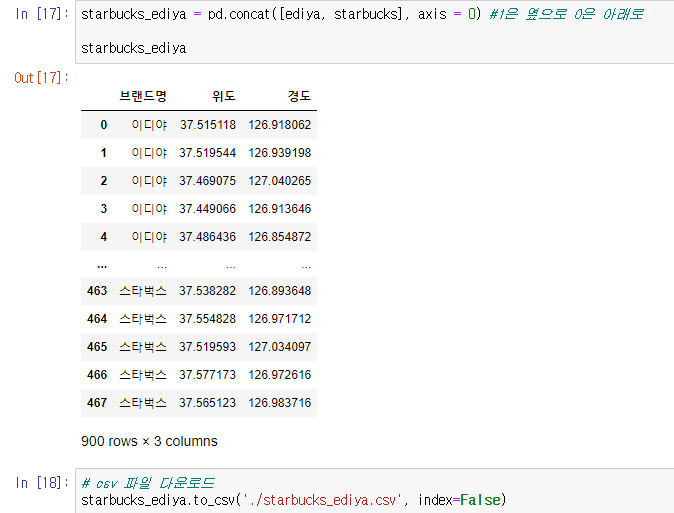
- axis=0이면 아래로, axis=1이면 옆으로
URL

사진은 남아 추억이 메모는 남아 스펙이 된다