개요
- 네이버 뉴스에서 실시간, 대용량 데이터를 수집/처리/시각화 프로젝트
- 네이버 뉴스에서 키워드에 맞게 원하는 정보 수집
- 그 정보를 토대로 분야 별로 분류하고 사용자들이 어떤 정보를 더 보는지 확인
프로젝트 기간
- 2022.03.14 ~ 2022.04.01
자원
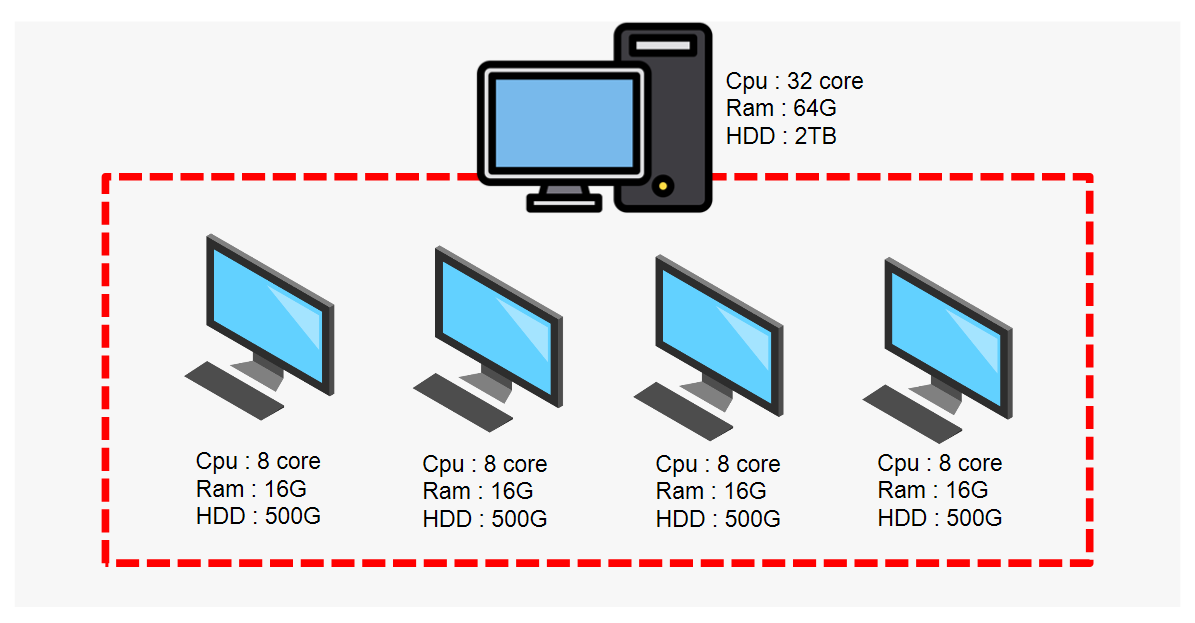
개발환경
- VM-ware workstarion pro 16
- Ubuntu :18.04
- Kubernetes(k8s) :v1.23.5
- Containerd :1.5.10
- Docker :20.10.14
- AWS EC2(Crawler)
- PyCham Community(2021)
- GitHub
- Discord
- TeamViewer
사용기술
- 프로그래밍 언어
- Python(3.9)
- 프로그램
- Kubernetes :v1.23.5
- Containerd :1.5.10
- Docker :20.10.14
- Calico :3.22
- ingress-nginx/controller :v1.0.0
- Metallb :v0.9.3
- Kafka :3.1.0
- Fluentd :4.3
- ElasticSearch :7.17.1
- Kibana :7.17.1
- Prometheus :2.27.1
- Grafana :8.0.3
- Node_exporter 1.1.2
- Hadoop(HDFS) :3.2.2 - 추가 업데이트 중
- Spark :3.1.3 - 추가 업데이트 중
- Apache zeppelin :0.8.0 - 추가 업데이트 중
- Cloud craft
- 백엔드
- Python(3.9)
- Django :2.0.5
- DJango ORM
- APACHE :2.4.29(ubuntu)
- 저장 환경
- ElasticSearch
- Hadoop(HDFS) - 추가 업데이트 중
- 프론트엔드
- Javascript
- HTML, CSS
주요 키워드
- Clustering
- Kubernetes(k8s) x Contaierd
- EFK(elasticsearch + fluentd + kibana)
- Kafka
- Prometheus&grafana
- Real-Time Crawling
- Real-Time Storage
- Real-Time Processing
- Git 관리
시스템 흐름도
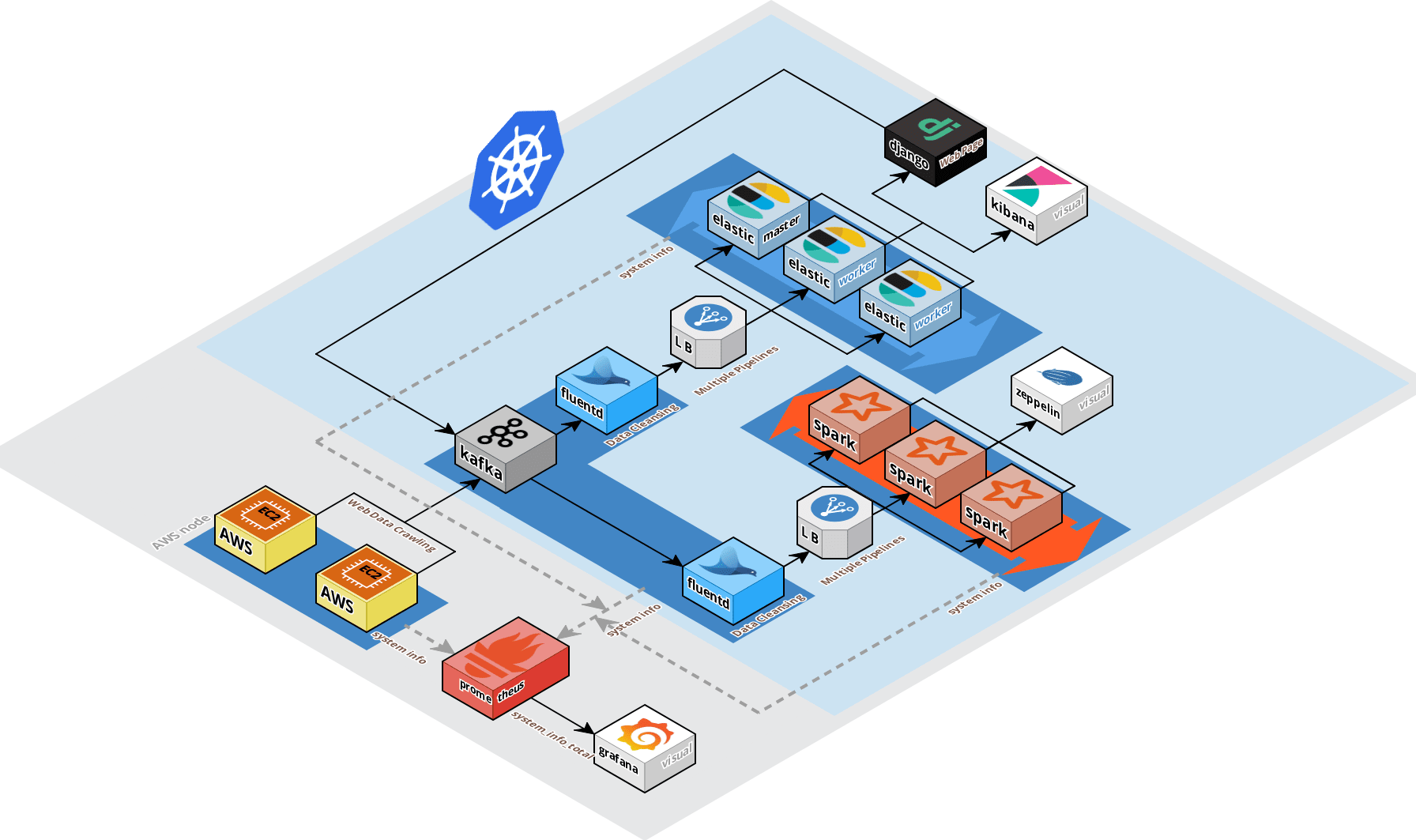
데이터 파이프라인
-
쿠버네티스 환경 : 쿠버네티스 클러스터 환경을 구축, Deployment (Pod, ReplicaSet, Volume), Service(LoadBalancer, Cluster IP)
-
Crawling DATA
- EC2 -> 카프카 -> 플루언티드 -> 엘라스틱서치 -> 키바나
- Python 코드를 사용하여 인터넷 뉴스에서 원하는 데이터로 수집 및 정제 -> Kafka -> Fluentd를 통해 ElasticSearch에 저장, Kibana로 시각화
-
LOG DATA
- Django -> Kafka -> Fluentd -> Apache Spark -> Apache Zeppelin
- 시각화된 데이터를 Django 웹서버에 구현, 사용자들의 로그를 Kafka -> Fluentd를 통해 Apache Spark에서 분석, 처리하고 Apache Zeppelin으로 시각화
-
모든 컴퓨터의 상태
- Kubernetes -> Prometheus -> Grafana
- Kubernetes 아래 모든 Pods의 정보를 Prometheus에서 받고 상태를 Grafana로 시각화
URL
영상
- 담당 파트 : 4:34~12:13

사진은 남아 추억이 메모는 남아 스펙이 된다