개요
- Client -> Django -> S3, Spark -> S3
- 유저가 업로드한 비디오 파일 & Spark에서 이미지 압축 파일를 S3로 전달 > Hdfs로 전달
- 수정 이유
- S3 비용
- 프레임마다 자른 img 압축 파일과 비디오 파일은 사용 빈도가 적음
- 비디오 파일 및 img 압축 파일의 용량이 큼
- Spark
- Spark를 사용 중이기 때문에 Hdfs에 같이 사용이 좋음
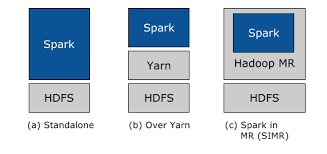
- Spark를 사용 중이기 때문에 Hdfs에 같이 사용이 좋음
- S3 비용
- 수정 이유
TroubleShooting
- S3 사용 빈도와 저장할 파일들이 많아 S3 비용이 많이 나올 가능성이 큼
- .mp4 파일 & 이미지 압축 파일은 사용빈도가 적음
- S3 사용이유
- 사용이 빈번하고 중요한 데이터 저장 > IAM을 이용하여 디렉토리마다 사용 권한을 부여가 가능함
- 데이터의 Upload & Download가 빨라 플랫폼의 원할한 이용이 가능함
- Auto Scaling > Scale Up이 간편함
- S3 사용이유
해결방안
- Hadoop 플랫폼을 사용하여 비디오 파일 & 이미지 압축 파일를 백업 용도로 저장
- Hadoop 채택 이유
- Spark를 사용 중이기 때문에 Hdfs에 같이 사용이 좋음
- 실시간으로 처리할 필요가 없기 때문에 배치 처리를 채택함
- Hadoop 채택 이유
Install
- Hdfs Python API
pip install hdfs - Hdfs API_URL
코드
- Django(Python)
# pip install hdfs
import hdfs
import environ
env = environ.Env(
# set casting, default value
DEBUG=(bool, False)
)
environ.Env.read_env(
env_file=os.path.join(BASE_DIR, '.env')
)
def sendfile():
global num
# 카프카 프로듀서 기본 설정
producer = KafkaProducer(
acks=0,
compression_type='gzip',
bootstrap_servers=[os.environ['kafka_Ip']], # IP주소
value_serializer=lambda v: dumps(v).encode('utf-8'),
)
# hdfs URL로 접근 > URL로 접근하여 파일 업로드 및 다운로드 가능
client_hdfs = InsecureClient(os.environ['hdfs_URL'])
client_hdfs.upload('/', './media/result/' + str(num) + '.mp4')
# 다운로드 기능
# client_hdfs.download('/', './media/result/', overwrite=False, n_threads=1, temp_dir=None, **kwargs)
# Hdfs 업로드 완료 메세지 큐 전달
producer.send('sendvideo', {
'title': str(num) + '.mp4',
})
time.sleep(0.2) # 부하를 막기 위해 0.2초 쉬기
producer.flush() # 데이터 비우기
num += 1결과
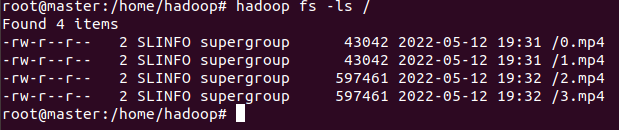
- Hadoop
hadoop fs -ls /를 사용하여 mp4파일이 업로드 된 모습을 확인할 수 있음
URL

사진은 남아 추억이 메모는 남아 스펙이 된다
와 대단하시네요 저도 만들어보고 싶네요