0. 영화 대본 다운로드 및 HDFS 파일시스템에 업로드
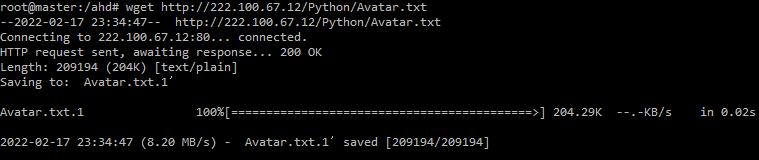
1)영화대본 Avatar.txt를 다운
wget http://222.100.67.12/Python/Avatar.txt
2) Avatar.txt 파일을 HDFS 파일시스템 최상위 디렉토리에 업로드
hadoop fs -put Avatar.txt /3) HDFS 파일시스템에 Avatar.txt파일이 저장되었는지 확인
hadoop fs -ls /

1. 영화대본 파일 WordCount
1) /result` Avatar.txt을 매핑 후, 단어들의 개수를 셔플해 result 디렉토리에 저장
`hadoop jar /opt/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount [HDFS에 있는 대본 파일]
2) 정상적으로 명령어가 실행되었다면, /result디렉토리에 _SUCCESS, part-r-00000 파일이 생성됨

2. 영화대본 파일 다운로드
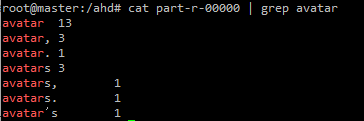
1) part-r-00000 파일을 다운로드
hadoop fs -get /result2/part-r-000000 .2)다운로드 받은 파일의 일부분
cat part-r-00000 | grep avatar

사진은 남아 추억이 메모는 남아 스펙이 된다