정규 표현식
정규 표현식은 특정 규칙을 가진 문자열의 집합을 표현하는 형식 언어로, 찾고자 하는 문자열 패턴을 정의하고 기존 문자열과 일치하는지를 비교하여 문자열을 검색하거나 다른 문자열로 치환하는데 사용한다
세상에는 패턴화된 문자들이 많은데 (이메일, 주민등록번호, 전화번호, 우편번호, URL 등) 패턴화된 문자열에 매번 문자열 메서드(startswith(), endswith(), replace() 등)을 사용하기 힘들다
이때 정규표현식을 사용하면 간단하게 문자열을 검색, 치환 할 수 있다
정규 표현식 사용하기
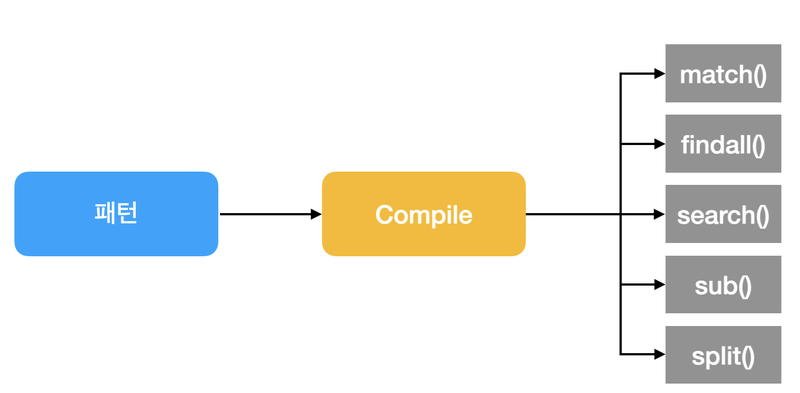
컴파일(comfile)
파이썬에서 표준 라이브러리 모듈인 re를 사용해 정규 표현식을 사용할 수 있다
import re
정규 표현식의 사용법은 두 단계로 나눠진다
1) 찾고자 하는 문자열 패턴 정의
2) 정의된 패턴과 매칭되는 경우 다양한 처리
첫 번째에 해당하는 과정을 컴파일(compile)이라고 한다
# 1단계 : 'the'라는 패턴을 컴파일 한 후 패턴 객체 리턴
pattern = re.compile('the')
# 2단계 : 컴파일된 패턴 객체를 활용 다른 텍스트에서 검색을 수행
pattern.findall('of the people, for the people, by the people')
출력
['the', 'the', 'the']하지만 정규 표현식을 위해서 항상 re.compile()을 호출해야 하는 것은 아니다
아래의 코드는 위의 2단계로 수행한 내역을 컴파일 과정 없이 한 줄로 동일하게 처리한다
re.findall('the', 'of the people, for the people, by the people')
출력
['the', 'the', 'the']꼭 명시적으로 패턴 객체를 생성할 필요는 없지만 패턴 객체를 생성한 경우 해당 객체를 반복 사용 가능하다는 점이 장점이다
메서드
1단계에서 컴파일 한 이후 2단계에서 패턴 객체를 활용해 호출 가능한 메서드와 속성을 알아볼 차례
많이 사용되고 있는 메서드
search(): 일치하는 패턴 찾기, 일치하는 패턴이 있으면 MatchObject를 반환match():search()와 비슷하지만 처음부터 패턴이 검색 대상과 일치해야 한다findall(): 일치하는 모든 패턴 찾기, 일치하는 모든 패턴을 리스트에 담아서 반환split(): 패턴으로 나누기sub(): 일치하는 패턴으로 대체하기
search(),match()등이 리턴하는 MatchObject가 가진 메서드
group(): 실제 결과에 해당하는 문자열을 반환
예제
src = "My name is...."
regex = re.match("My", src)
print(regex)
if regex:
print(regex.group())
else:
print("No!")
출력
<re.Match object; span=(0, 2), match='My'>
My
** regex의 "My" 값을 "Your"로 변경할 경우 출력 값
None
No!패턴 특수문자
패턴이야말로 정규 표현식을 강력하게 해주는 도구이다
특수문자 혹은 메타문자라고 불리는 [] - . ? * + {} /등을 이용해 특수 패턴을 만들 수 있다
[ ]: 문자-: 범위.: 하나의 문자?: 0회 또는 1회 반복*: 0회 이상 반복+: 1회 이상 반복{m, n}: m ~ n\d: 숫자, [0-9]와 동일\D: 비 숫자, [^0-9]와 동일\w: 알파벳 문자 + 숫자 + , [a-zA-Z0-9]와 동일\W: 비 알파벳 문자 + 비숫자, [^a-zA-Z0-9_]와 동일\s: 공백 문자, [ \t\n\r\f\v]와 동일\S: 비 공백 문자, [^ \t\n\r\f\v]와 동일\b: 단어 경계\B: 비 단어 경계\t: 가로 탭(tab)\v: 세로 탭(vertical tab)\f: 폼 피드\n: 라인 피드(개행문자)\r: 캐리지 리턴(원시 문자열)
너무 많다 외우기도 어렵겠다
예제로 조금씩 익혀본다
예제 1
문자를 명확하게 정할 수 없지만 규칙이 있을 때
2020이나 2021과 같은 특정 연도를 찾을 때는 re.compile("2020")을 사용하면 되지만
1000년 이후의 연도를 모두 찾고 싶을 때 숫자는 \d이므로 \d\d\d\d를 사용하면 숫자 4개가 연달아 있는 부분을 찾을 수 있다. 하지만 1000년 이후이므로 앞자리가 1 또는 2
1~2를 의미하는 [1-2]를 사용하고 숫자 세 개를 연달아 [1-2]\d\d\d를 사용
# 연도(숫자) 찾기
text = """
The first season of America Premiere League was played in 1993.
The second season was played in 1995 in South Africa.
Last season was played in 2019 and won by Chennai Super Kings (CSK).
CSK won the title in 2000 and 2002 as well.
Mumbai Indians (MI) has also won the title 3 times in 2013, 2015 and 2017.
"""
pattern = re.compile("[1-2]\d\d\d")
pattern.findall(text)
출력
['1993', '1995', '2019', '2000', '2002', '2013', '2015', '2017']예제 2
전화번호를 찾을 때도 이와 비슷하다. 전화번호는 숫자 3자리-4자리-4자리로 이루어져 있다면
\d\d\d와 \d\d\d\d를 사용 중간에 -가 필요
#- 전화번호(숫자, 기호)
phonenumber = re.compile(r'\d\d\d-\d\d\d\d-\d\d\d\d')
phone = phonenumber.search('This is my phone number 010-1111-1111')
if phone:
print(phone.group())
print('------')
phone = phonenumber.match ('This is my phone number 010-1111-1111')
if phone:
print(phone.group())
출력
010-1111-1111
------위 코드의 경우 search()와 match()를 사용했는데 match()의 경우 패턴과 검색 대상이 처음부터 일치하지 않으므로 아무것도 출력되지 않는 것을 볼 수 있다
또 \d\d\d를 \d{3}으로 바꿔서 표현할 수 있다
phonenumber = re.compile(r'\d{3}-\d{3}-\d{4}')-\d{4}가 두 번 반복되는 것도 (-\d{4}){2}로 바꿔서 표현 가능
phonenumber = re.compile(r'\d{3}(-\d{4}){2}')전부 동일한 출력값을 확인할 수 있다
예제 3
복잡한 정규 표현식
#- 이메일(알파벳, 숫자, 기호)
text = "My e-mail adress is doingharu@aiffel.com, and tomorrow@aiffel.com"
pattern = re.compile("[0-9a-zA-Z]+@[0-9a-z]+\.[0-9a-z]+")
pattern.findall(text)이해가 잘 안된다면 @를 기준 앞 뒤로 나눠서 파악한다
앞 : [0-9a-zA-Z]+ 숫자 0~9 알파벳 대소문자 A~Z, a~z가 여러번(+)나온다
뒤 : [0-9a-z]+\.[0-9a-z]+ 는 \.을 기준으로 동일하다
[0-9a-z]+은 숫자 0~9, 소문자 a~z가 여러번 나타난다는 의미
뒤에는 .com 말고도 다양한 도메인이 허용됨
정리
정규 표현식 구현 순서를 그림과 함께 간단하게 정리
import re를 통해 정규식 모듈을 불러온다re.compile()함수로 Regex객체를 만든다- 검색할 문자열의 Regex 객체의
search(),findall()메소드로 전달한다