운영하는 서비스의 지표 업데이트 반영을 위한 파이프라인 수정 작업 중 이전 파이프라인 에서 뷰테이블에 중복 row 가 있지만, 가장 마지막 에서 group by를 하는 것을 발견했다.
마지막 단계에서 Inner Join 도 행하기 때문에 group by 를 미리 취하는게 좋지 않을까? 하는 단순한 호기심이 들어서 테스트 해보았다.
실험 예시 테이블 및 쿼리
실험을 하기 위해 예시 테이블을 아래와 같이 생성하였다.
(속도 실험을 위한 것이므로 데이터 크기 정보만 기재했다.)
| Table | (records, fields) |
|---|---|
B | (2991, 165) |
C | (5195, 15) |
ID_TBL | (280,3) |
ID_TBL group by 시 | (173,3) |
C INNER JOIN ID_TBL | (276,3) |
RPT | (171,3) |
실험하고자 하는 쿼리 case 1 은 아래 와 같다. (실제 쿼리와는 다른 쿼리입니다.)
WITH YM_TBL AS (
SELECT CAST(YM as String) AS YM
FROM B
WHERE DT >= '{DT}'
GROUP BY 1
)
, ID_TBL AS (
SELECT LID
, SID
, CAST(YM as String) AS R_REFYM
FROM B
WHERE YM IN (SELECT YM FROM YM_TBL)
GROUP BY 1,2,3 --case1
)
, RPT AS (
SELECT M.LID
, M.SID
, S.YM
FROM C M
INNER JOIN ID_TBL S
ON M.LID=S.LID
--GROUP BY 1,2,3
)
SELECT * FROM RPT비교 대상이 되는 대조쿼리는 아래와 같다.
WITH YM_TBL AS (
SELECT CAST(YM as String) AS YM
FROM B
WHERE DT >= '{DT}'
GROUP BY 1
)
, ID_TBL AS (
SELECT LID
, SID
, CAST(YM as String) AS R_REFYM
FROM B
WHERE YM IN (SELECT YM FROM YM_TBL)
--GROUP BY 1,2,3
)
, RPT AS (
SELECT M.LID
, M.SID
, S.YM
FROM C M
INNER JOIN ID_TBL S
ON M.LID=S.LID
GROUP BY 1,2,3
--case2
)
SELECT * FROM RPT실험 결과
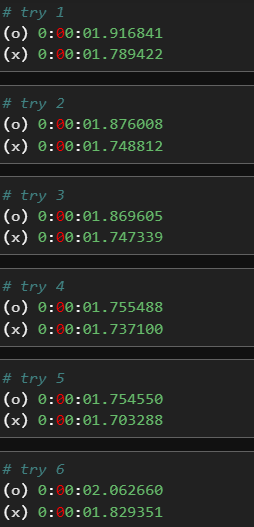
이미지에는 6번 시도까지만 있지만 20번은 넘게 해보았고,
단 한 번의 오차없이 case2 (대조군) 쿼리가 수행시간이 더 짧았다.
그리고 시행횟수가 많아질 수록 case1 는 더 느려졌다.
case1 과 case2 실행순서도 바꿔보았지만, 다른 결과는 나오지 않았다.
처음에 쿼리 group by 시점에 의문을 가졌던 것은 RPT 서브쿼리에서 수행하는 레코드 수 가 큰 C 테이블과의 inner join 때문이었는데..
정작 group by 하는 테이블의 레코드 수 차이가 (280,3) vs (276,3) 실행시간에는 더 큰 영향을 미침을 알 수 있었다.
4 records 차이지만 실제 데이터 크기는 4*3 이며,
실제 파이프라인에서는 필드가 더 많아지므로 더 큰 차이를 가짐을 알 수 있다.
다음 번엔 이런 쓸데없는(?) 의문으로 시간을 쓰지 않도록 join 내부 로직과 group by 로직에 대해서도 스터디해야겠다 :)
