정보 : Opensearch Documentation
https://opensearch.org/docs/latest/opensearch/cluster/
- Opensearch Documentation을 보면서 느낀 건 ElasticSearch Documentation을 복사 붙여넣기 한게 굉장히 많다.
- Refer가 부족한 부분은 ElasticSearch Documentation을 보면서 보완해야 할 것 같다.
1. Cluster 종류
| Node type | Description | Best practices for production |
|---|---|---|
| Cluster manager | 클러스터의 전체 작업을 관리하고 클러스터 상태를 추적합니다. 여기에는 인덱스 생성 및 삭제, 클러스터에 가입하고 나가는 노드 추적, 클러스터의 각 노드 상태 확인(ping 요청 실행), 노드에 샤드 할당 등이 포함됩니다. | 3개의 서로 다른 영역에 있는 3개의 전용 클러스터 관리자 노드는 거의 모든 프로덕션 사용 사례에 적합한 접근 방식입니다. 이 구성을 사용하면 클러스터에 쿼럼이 손실되지 않습니다. 한 노드가 중단되거나 유지 보수가 필요한 경우를 제외하고 두 노드는 대부분 유휴 상태입니다. |
| Cluster manager eligible | 투표 프로세스를 통해 그 중 하나의 노드를 클러스터 관리자 노드로 선택합니다. | 프로덕션 클러스터의 경우 전용 클러스터 관리자 노드가 있는지 확인하십시오. 전용 노드 유형을 달성하는 방법은 다른 모든 노드 유형을 거짓으로 표시하는 것입니다. 이 경우 다른 모든 노드를 클러스터 관리자에 적합하지 않은 노드로 표시해야 합니다. |
| Data | 데이터를 저장하고 검색합니다. 로컬 샤드에서 모든 데이터 관련 작업(인덱싱, 검색, 집계)을 수행합니다. 클러스터의 작업자 노드이며 다른 노드 유형보다 많은 디스크 공간이 필요합니다. | 데이터 노드를 추가할 때 영역 간에 균형을 유지하십시오. 예를 들어, 영역이 3개인 경우 데이터 노드를 각 영역에 대해 하나씩 3개의 배수로 추가합니다. 스토리지 및 RAM이 많은 노드를 사용하는 것이 좋습니다. |
| Ingest | 데이터를 클러스터에 저장하기 전에 미리 처리합니다. 데이터를 인덱스에 추가하기 전에 변환하는 수집 파이프라인을 실행합니다. | 많은 데이터를 수집하고 복잡한 수집 파이프라인을 실행하려는 경우 전용 수집 노드를 사용하는 것이 좋습니다. 데이터 노드가 검색 및 집계에만 사용되도록 데이터 노드에서 인덱싱을 오프로드할 수도 있습니다. |
| Coordinating | 클라이언트 요청을 데이터 노드의 샤드에 위임하고 결과를 수집하여 하나의 최종 결과로 집계한 후 이 결과를 클라이언트로 다시 보냅니다. | 검색 부하가 높은 워크로드의 병목 현상을 방지하려면 몇 가지 전용 조정 전용 노드가 적합합니다. 가능한 한 많은 코어가 있는 CPU를 사용하는 것이 좋습니다. |
| Dynamic | 머신 러닝(ML) 작업과 같은 사용자 지정 작업을 위한 특정 노드를 위임하여 데이터 노드의 리소스 소비를 방지하여 OpenSearch 기능에 영향을 미치지 않도록 합니다. |
- 기본적으로 각 노드는 마스터 Eligible, 데이터, 수집 및 조정 노드입니다. 노드 수 결정, 노드 유형 할당 및 각 노드 유형에 대한 하드웨어 선택은 사용 사례에 따라 다릅니다. 데이터를 보관할 시간, 문서의 평균 크기, 일반 워크로드(인덱스, 검색, 집계), 예상 가격 대비 성능 비율, 위험 허용 오차 등과 같은 요인을 고려해야 합니다.
- 이러한 모든 요구사항을 평가한 후에는 Rally와 같은 벤치마크 테스트 툴을 사용하여 소규모 샘플 클러스터를 프로비저닝하고 다양한 워크로드 및 구성으로 테스트를 실행하는 것이 좋습니다. 이러한 테스트에 대한 시스템 및 쿼리 메트릭을 비교 및 분석하여 최적의 아키텍처를 설계합니다. 랠리를 시작하려면 랠리 설명서를 참조하십시오.
2. Index
-
Opensearch를 활용하는 핵심은 Index라고 볼 수 있음
-
단순히 시스템로그만 불러온다면 Error/Normal/Warning 정도의 분류로 나눌수 있겠지만 정보의 종류가 다양해 질수록 Index가 필요하다.
-
Key / Value 값의 json값을 Index를 통해 원하는 정보를 빠르게 불러 올 수 있어야 한다.
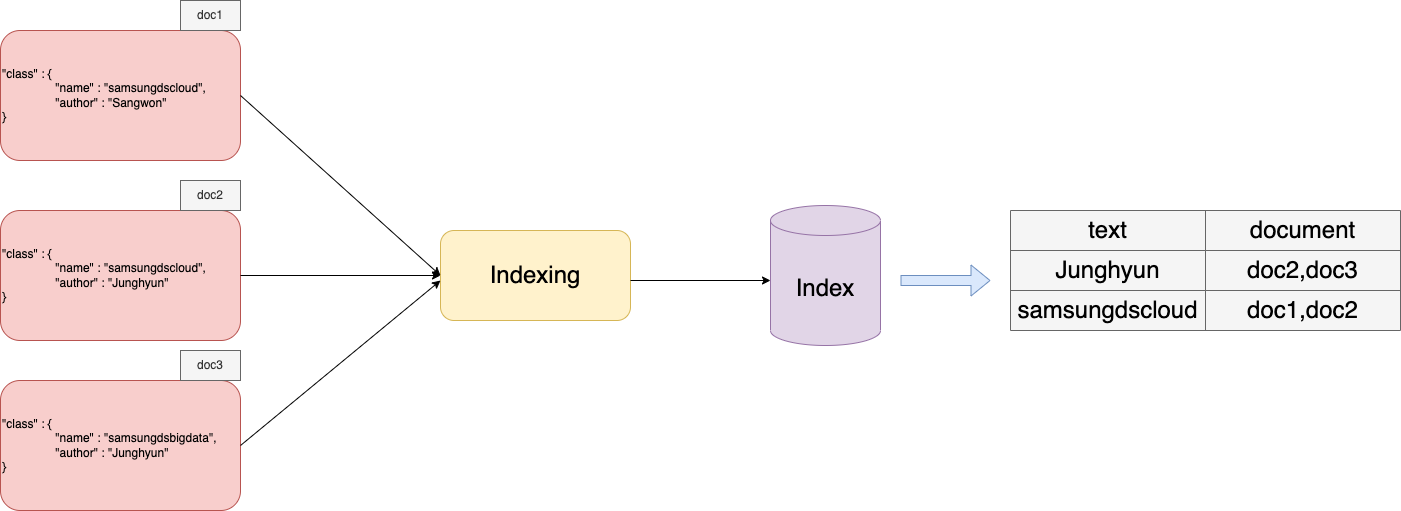
-
데이터가 늘어나는 멀티 클러스터에서 Indexing을 통한 원하는 로그를 빠르게 탐색하기 위해선 Ingest node (전처리 노드)가 필수적으로 필요함.
Opensearch Relational DB CRUD GET Select Read PUT Update Update POST Insert Create DELETE Delete Delete <기존 관계형 DB 및 CRUD와 비교한 Opensearch에서 Indexing 방법>
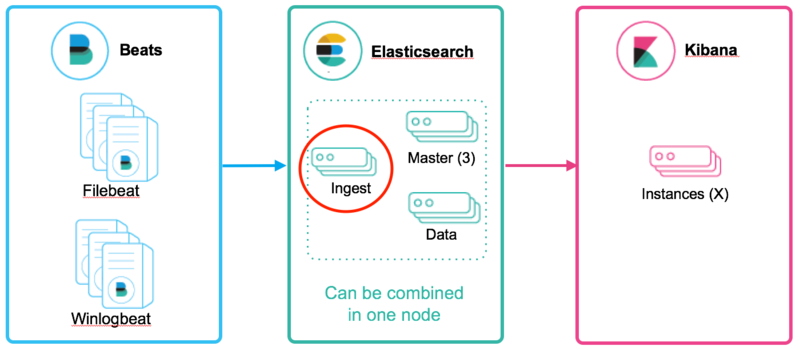
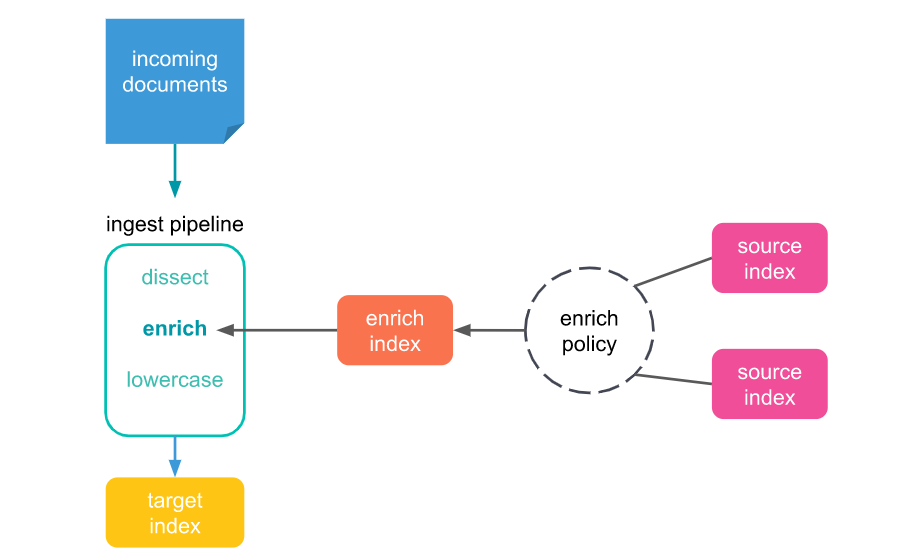
3. Cluster 구성

계속해서 Blue를 이겨내가는 사람 / System Engineer / Server, OS, Storage, Network, Cloud / 이제 다시 코딩으로!!