👌< 스크래핑(scraping) >
데이터를 수집하는 모든 작업을 말한다.
컴퓨터 프로그램이 다른 프로그램으로부터 들어오는 인간이 읽을 수 있는 출력으로부터 데이터를 추출하는 기법이다.
👌< 크롤링(crawing) >
-Web상에 존재하는 Contents를 수집하는 작업(프로그래밍으로 자동화 기능)
1. HTML 페이지르 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법.
2. Open API(Rest API)를 제공하는 서비스에 Oprn API를 호출해서, 받은 데이터 중 필요한 데이터만 추출하는 기법.
3. Selenium등 브라우저를 프로그래밍으로 조작해서, 필요한 데이터만 추출하는 기법.
👌< 파싱(Parsing) >
파싱(Parsing)은 어떤 페이지(문서, html 등)에서 원하는 데이터를 특정 패턴이나 순서로 추출하여 정보로 가공하는 것을 말합니다.
다이아몬드가 많이 나오는 위치로 이동을 한 후에 돌을 캐고 다이아몬드만 쏙쏙 뽑아서 보석으로 가공하는 과정하고 비슷하다고 보면 됩니다.
👌< 기본 용어 >
- http(hyper text transfer protocol)
hyper text는 마우스로 클릭하면 다른페이지로 이동하는 기능.
http는 다음에 나올 html로 작성되어 있는 hyper text를 전송하기 위한 프로토콜(규약, 약속)- URL(Uniform Resource Locator)
인터넷 주소.- HTML(Hyper Text Markup Language)
웹페이지를 작성하는 문법 언어.
F12(개발자 도구)눌러서 볼수 있다.- 웹 브라우저(web browser)
html을 보기 좋게 출력하는 응용 소프트웨어.
👌파이썬으로 웹 스크래핑
- HTML 문서 다운로드 및 파싱
웹 스크래핑을 하려면 먼저 HTML 파일을 다운로드한 후, 해당 HTML 문서를 분석해서 원하는 데이터를 가져와야 한다.
파이썬에서 웹 페이지 다운로드는 requests 모듈을 사용하고 웹 페이지에서 원하는 데이터를 가져가는 파싱(parsing)은 BeautifulSoup 모듈을 사용한다.
- requests 모듈의 get 함수를 사용하면 웹 페이지의 HTML 데이터를 PC에 다운로드할 수 있다.
import requests
url = "http://www.naver.com"
response = requests.get(url)- 파싱
BeautifulSoup모듈은 HTML 파일로부터 원하는 데이터를 파싱하는 데 사용한다.
HTML 문서에서 원하는 데이터를 쉽게 파싱하기 위해서 BeautifulSoup 모듈을 사용한다.
우선 모듈을 임포트하고 BeautifulSoup 객체를 생성한다.
객체를 생성할 때 html 데이터와 HTML 문서를 파싱하는 데 사용할 모듈의 이름인 "html5lib"을 넘겨주면 된다.
pip install bs4
from bs4 import BeautifulSoup
import requests
url = "https://finance.naver.com/item/main.nhn?code=000660"
html = requests.get(url).text
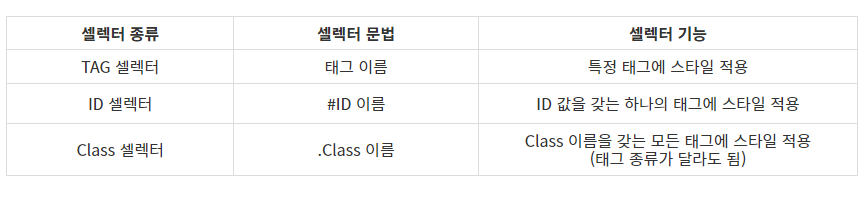
soup = BeautifulSoup(html, "html5lib")- CSS 셀렉터
생성한 BeautifulSoup 객체는 HTML 파싱을 위한 다양한 메서드를 갖고 있다.
그 중에서select()메서드를 사용하면 CSS 셀렉터를 사용해서 HTML 문서를 파싱할 수 있다.
크롬 브라우저를 사용하면 다중 셀렉터를 쉽게 만들 수 있다.
마우스 오른쪽 버튼을 클릭한 후 Copy → Copy selector 메뉴를 선택한다.
CSS selector에서 > 기호는 자식 태그를 의미한다.
아래의 CSS selector는 ID가 'tab_con1'인 태그 안에 있는 세 번째 div 태그 안에 table 태그 안에 tbody 태그 안에 strong 클래스 속성이 부여된 tr 태그 안에 td 태그 안에 있는 em 태그를 의미한다.
ex) #tab_con1 > div:nth-child(3) > table > tbody > tr.strong > td > em
HTML 문서 전체에서 이런 태그 계층 구조를 가진 em 태그를 찾는 것이다.
코드를 실행해보면 nth-of-type을 사용하라는 에러 메시지가 출력된다.
이는 BeautifulSoup 모듈이 CSS 셀렉터를 100% 지원하지 않아 nth-child를 인식하지 못하기 때문에 발생하는 에러다.
BeautifulSoup은 특정 위치의 자식 태그를 선택할 때 nth-child()대신, nth-of-type()을 사용해야 한다.
- Cf. nth-child vs. nth-of-type
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/item/main.nhn?code=000660"
html = requests.get(url).text
soup = BeautifulSoup(html, "html5lib")
# 직접 만든 CSS 셀렉터
tags = soup.select(".lwidth tbody .strong td em")
# 크롬 브라우저가 지원하는 CSS 셀렉터
# tags = soup.select("#tab_con1 > div:nth-of-type(2) > table > tbody > tr.strong > td > em")
tag = tags[0] # 원하는 값만을 파싱했기 때문에 0번만 인덱싱
print(tag.text) 출처&참조:
https://truman.tistory.com/108
https://www.fun-coding.org/crawl_basic2.html
https://dsc-sookmyung.tistory.com/85
