신경망 톱니바퀴, 텐서의 연산 P75
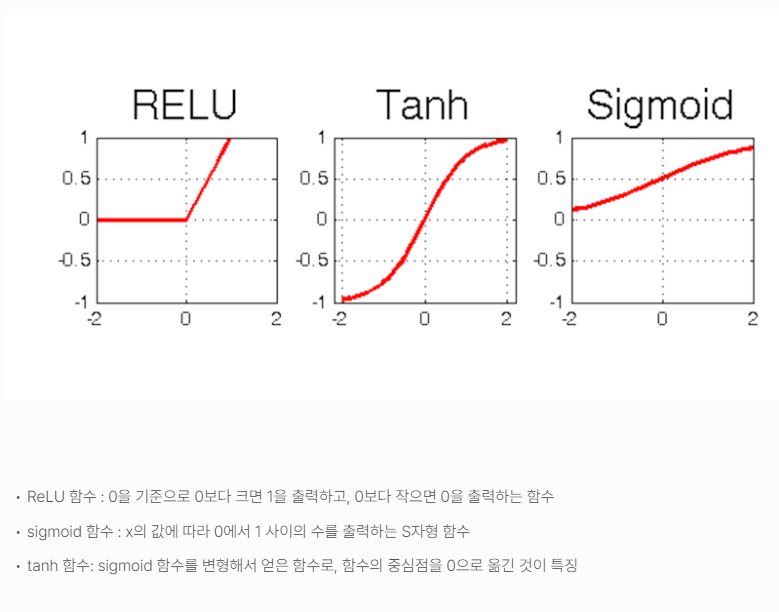
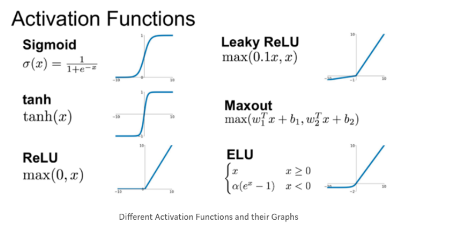
relu: 함수는 입력값이 0보다 크면 입력을 그대로 반환하고 0보다 작으면 0을 반환합니다.

컴퓨터 프로그램을 이진수의 입력을 처리하는 몇 개의 이항 연산(AND, OR, NOR 등)으로 표현할 수 있는 것처럼, 심층 신경망이 학습한 모든 변환을 수치 데이터 텐서에 적용하는 몇 종류의 텐서 연산tensor operation으로 나타낼 수 있습니다. 예를 들어 텐서 덧셈이나 텐서 곱셈 등입니다.
- output = relu(dot(W, input) + b)
- W는 2D 텐서고, b는 벡터입니다. 둘 모두 층의 속성입니다.
좀 더 자세히 알아보겠습니다. 여기에는 3개의 텐서 연산이 있습니다. 입력 텐서와 텐서 W 사이의 점곱(dot), 점곱의 결과인 2D 텐서와 벡터 b 사이의 덧셈(+), 마지막으로 relu(렐루) 연산입니다. relu(x)는 max(x, 0)입니다.
Note 이 절은 선형대수학(linear algebra)을 다루지만 어떤 수학 기호도 사용하지 않습니다. 수학에 익숙하지 않은 프로그래머는 수학 방정식보다 짧은 파이썬 코드를 보는 것이 수학 개념을 이해하는 데 훨씬 도움이 됩니다. 앞으로도 계속 넘파이 코드를 사용하여 설명합니다.
브로드캐스팅
앞서 살펴본 단순한 덧셈 구현인 naive_add는 동일한 크기의 2D 텐서만 지원합니다. 하지만 이전에 보았던 Dense 층에서는 2D 텐서와 벡터를 더했습니다. 크기가 다른 두 텐서가 더해질 때 무슨 일이 일어날까요?
모호하지 않고 실행 가능하다면 작은 텐서가 큰 텐서의 크기에 맞추어 브로드캐스팅broadcasting됩니다. 브로드캐스팅은 두 단계로 이루어집니다.
- 큰 텐서의 ndim에 맞도록 작은 텐서에 (브로드캐스팅 축이라고 부르는) 축이 추가됩니다.
- 작은 텐서가 새 축을 따라서 큰 텐서의 크기에 맞도록 반복됩니다.
텐서 점곱
텐서 곱셈tensor product이라고도 부르는(원소별 곱셈과 혼동하지 마세요) 점곱 연산dot operation은 가장 널리 사용되고 유용한 텐서 연산입니다. 원소별 연산과 반대로 입력 텐서의 원소들을 결합시킵니다.
넘파이, 케라스, 씨아노, 텐서플로에서 원소별 곱셈은 * 연산자를 사용합니다. 텐서플로에서는 dot 연산자가 다르지만 넘파이와 케라스는 점곱 연산에 보편적인 dot 연산자를 사용합니다.21
import numpy as np
z = np.dot(x, y)
z = x · y
def naive_vector_dot(x, y):
assert len(x.shape) == 1 # x와 y는 넘파이 벡터입니다.
assert len(y.shape) == 1
assert x.shape[0] == y.shape[0]
z = 0.
for i in range(x.shape[0]):
z += x[i] * y[i]
return z여기서 볼 수 있듯이 두 벡터의 점곱은 스칼라가 되므로 원소 개수가 같은 벡터끼리 점곱이 가능합니다.
행렬 x와 벡터 y 사이에서도 점곱이 가능합니다. y와 x의 행 사이에서 점곱이 일어나므로 벡터가 반환됩니다. 다음과 같이 구현할 수 있습니다
퍼셉트론
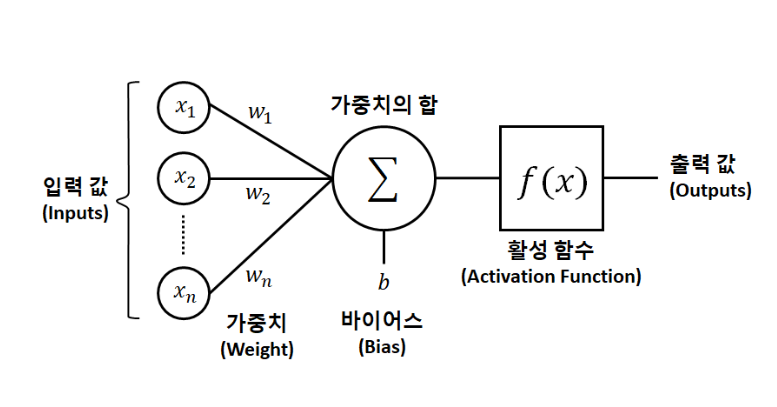
- 퍼셉트론: 인간의 뇌 속의 신경망 구조에서 착안된 것으로 가장 간단한 인공 신경망 중 하나이다. 그리고 입출력이 어떤 숫자이고 각각의 가중치와연관
- FNN : 신호가 입->출로 한 방양만으로 흐른다
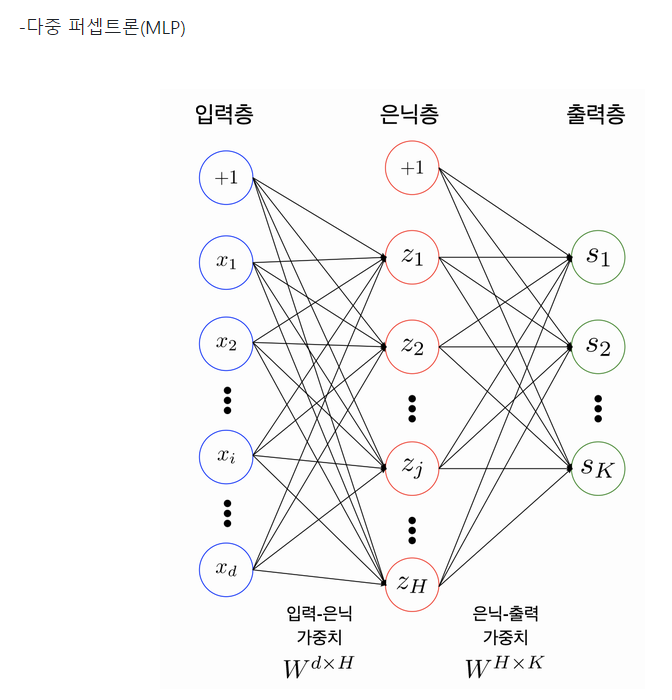
- DNN : 은닉층을 여러 개 쌓아 올린 인공 신경망
- 케라스API : 인공 신경망을 간결하고 다양하게 구현하게 해주는 API.
- MNIST : 숫자 이미지 데이터셋으로 학습용으로 많이 사용있다.
- bias term : 입력값 출력값 모두 0이 되는 경우를 방지.
- 입력층 : 입력 뉴런 + 편향뉴런(항상 1을 출력)으로 구성. 행단위
- 은닉층 : 편향 뉴런 있음, 랜덤하게 가중치 초기화.
- 출력층 : 출력 뉴런있음
- 인공 뉴런층 계산(완전 연결층일 경우)
뉴스기사 분류: 다중 분류 문제 p160
- 로이터 데이터셋 : 뉴스와 기사 토픽의 집합.
# 4-11) 로이터 데이터셋 로드하기
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=10000)# 4-12) 로이터 데이터셋을 텍스트로 디코딩하기
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_newswire = " ".join([reverse_word_index.get(i - 3, "?") for i in train_data[0]]) # 0.1.2는 패딩,문서시작,사사전에 없음을 위해 예약되어 있으므로 인덱스에서 3을 뺍니다.# 4-3) 정수 시퀀스를 멀티-핫 인코딩으로 인코딩하기
from pyparsing import results
import numpy as np
def vectorize_sequences(sequences,dimension =10000):
results= np.zeros((len(sequences),dimension)) #크기가 ()인 모든원소가 0인 행렬를 만든다.
for i, sequence in enumerate(sequences):
for j in sequence:
results[i,j]= 1. # 특정 인덱스 위치만 1로 바꾼다.
return results# 4-13) 데이터 인코딩하기
x_train= vectorize_sequences(train_data) # 훈련 데이터를 벡터로 바꾼다.
x_test = vectorize_sequences(test_data) #테스트 데이터를 벡터로 바꾼다.# 4-14) 레이블 인코딩하기
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
y_train = to_one_hot(train_labels)
y_test = to_one_hot(test_labels)
# (1) 묶음
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import keras
from keras import Sequential # Sequential : 연속적으로 시간이 흐름,클래스다.
from keras import optimizers # optimizers :
from keras.layers import Input ,Dense # Dense:밀집 <-> sparse:희소하다
# 4-15) 모델 정의하기
model = keras.Sequential([
Dense(64, activation="relu"),
Dense(64, activation="relu"),
Dense(46, activation="softmax")
])
# 4-16) 모델 컴파일하기
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy", # 원-핫 인코딩
metrics=["accuracy"])# 4-17) 검증 세트 준비하기
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = y_train[:1000]
partial_y_train = y_train[1000:] # 4-18) 모델 훈련하기
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val)) ## 4-19) 훈련과 검증 손실 그리기
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()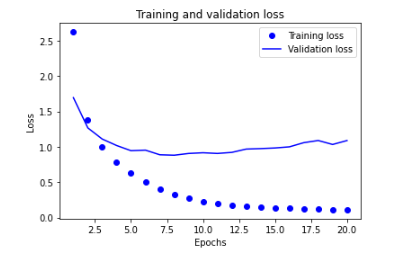
# 4-20) 훈련과 검증 정확도 그리기
plt.clf()
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "bo", label="Training accuracy")
plt.plot(epochs, val_acc, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()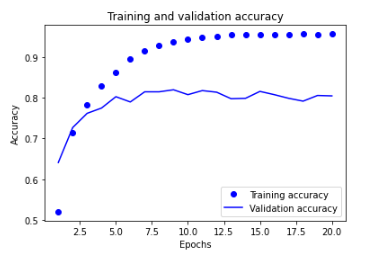
# 4-21) 모델을 처음부터 다시 훈련하기
model = keras.Sequential([
Dense(64, activation="relu"),
Dense(64, activation="relu"),
Dense(46, activation="softmax")
])
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"])
model.fit(x_train,
y_train,
epochs=9,
batch_size=512)
results = model.evaluate(x_test, y_test)
argmax, argmin 함수
최대값, 최소값의 위치 인덱스를 반환하는 함수 np.argmax와 np.argmin
np.argmax / np.argmin 함수 기본 사용법
np.argmax 함수는 함수 내에 array와 비슷한 형태(리스트 등 포함)의
input을 넣어주면 가장 큰 원소의 인덱스를 반환하는 형식입니다.
다만, 가장 큰 원소가 여러개 있는 경우 가장 앞의 인덱스를 반환합니다.
https://spartacodingclub.kr/blog/dl-> relu 그림
https://hwk0702.github.io/ml/dl/deep%20learning/2020/07/09/activation_function/-> 함수 종류
https://neocarus.tistory.com/entry/%EB%94%A5%EB%9F%AC%EB%8B%9D%EC%9D%98-%EC%88%98%ED%95%99%EC%A0%81-%EA%B5%AC%EC%84%B1-%EC%9A%94%EC%86%8C-> 텐서 연산
https://velog.io/@qsdcfd/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%A9%94%EC%BB%A4%EB%8B%88%EC%A6%98-> 퍼셉트론
https://tensorflow.blog/%EC%BC%80%EB%9D%BC%EC%8A%A4-%EB%94%A5%EB%9F%AC%EB%8B%9D/2-3-%EC%8B%A0%EA%B2%BD%EB%A7%9D%EC%9D%98-%ED%86%B1%EB%8B%88%EB%B0%94%ED%80%B4-%ED%85%90%EC%84%9C-%EC%97%B0%EC%82%B0/-> 책 정리
https://playground.tensorflow.org/->
