
linsapce와 arange 차이점
-
np.linsapce (시작,끝,숫자)
: 처음, 끝 값 포함한다.
: 숫자 강조시 사용 -
np.arange ([시작],끝,[구간])
: 끝 값 포함하지 않음. []로 생략가능
: 범위, 구간 강조시 사용(소수점 표시)
import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras import Sequential
from keras import optimizers
from keras.layers import Input ,Dense 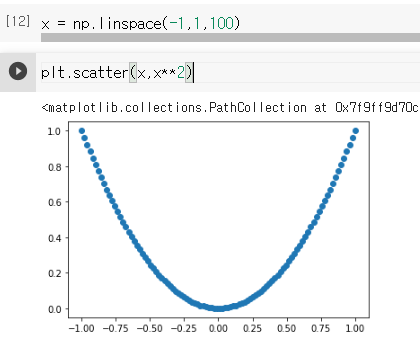
최종 정리
x = np.linspace(-1,1,1000)
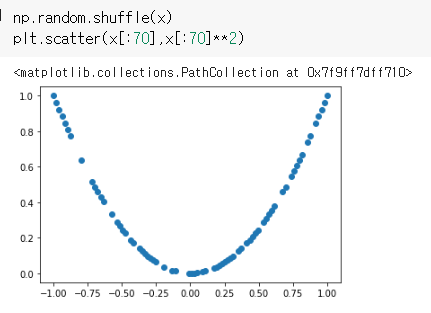
np.random.shuffle(x)
model = Sequential()
model.add(Input(1))
model.add(Dense(units=10,activation='tanh'))
model.add(Dense(units=10,activation='tanh'))
model.add(Dense(units= 1))
model.compile(optimizer='SGD',loss="mse",metrics='mse')
n=800
model.fit(x[:n],x[:n]**2,epochs=100,verbose=0,batch_size=32 )
preds = model.predict(x[n:])
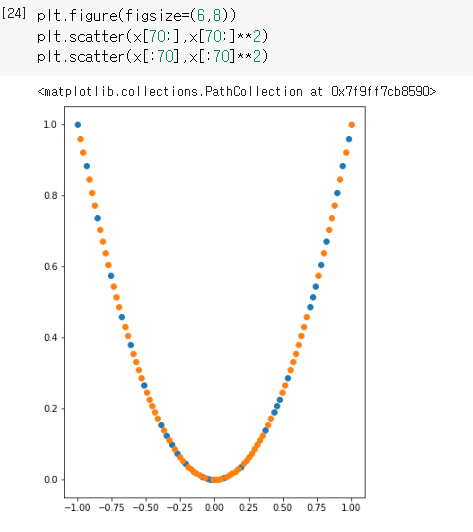
plt.scatter(x[:n],x[:n]**2)
plt.scatter(x[n:],preds)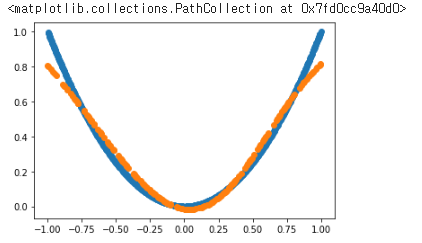
(1) import
import keras
# 2-1) p61
from keras.datasets import mnist
(train_images,train_labels),(test_images,test_labels)= mnist.load_data()
print(train_images.shape)
plt.imshow(train_images[0], cmap="gray") 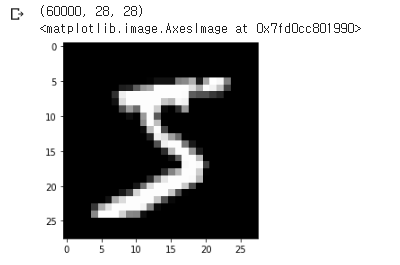
(2) 한줄 세우기
from keras.layers import Dense
# 2-4) 이미지 데이터 준비 p63
train_images=train_images.reshape(60000,28*28) #한줄로 서는 과정
train_images=train_images/255.0
test_images=test_images.reshape(10000,28*28) #한줄로 서는 과정
test_images=test_images/255.0(3) fit,preds
# 2-2) 신경망 구조 p62
from keras.engine import Sequential
model = Sequential()
model.add(Dense(512,activation='relu'))
model.add(Dense(10,activation='softmax'))
# (2-3) 컴파일 단계 p63
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy',metrics='acc')
# 2-5)모델 훈련하기 p64
model.fit(train_images,train_labels,epochs=5,batch_size=128)
preds = model.predict(test_images)
(2-2) 층. p62
신경망의 핵심 구성요소는 층입니다. 층은 데이터를 위한 필터로 생각할 수 있습니다.
어떤 데이터가 들어가면 더 유용한 형태로 출력됩니다. 조금 더 구체적으로 층은 주어진 문제에 더 의미 있는 표현을 입력된 데이터로부터 추출합니다. 대부분의 딥러닝은 간단한 층을 연결하여 구성되어 있고, 점진적으로 데이터를 정제하는 형태를 띠고 있습니다. 딥러닝 모델은 데이터 정제 필터 층이 연속되어 있는 데이터 프로세싱을 위한 여과기와 같습니다. 이 예에서는 조밀하게 연결된 (완전 연결된) 신경망 층인 Dense층 2개가 연속되어 있습니다. 두번째 층(마지막 층)은 10개의 확률 점수가 들어있는 배열을 반환하는 소프트맥스 분류 층입니다. 각 점수는 현재 숫자 이미지가 10개의 숫자 클래스 중 하나에 속할 확률입니다.
※신경망이 훈련 준비를 마치기 위해서 컴파일 단계에 포함된 세가지가 더 필요합니다.※
- 옴티마이저: 성능을 향상시키기 위해 입력된 데이터를 기반으로 모델을 업데이트 하는 메커니즘입니다.
- 손실 함수: 훈련 데이터에서 모델이 성능을 측정하는 방법으로 모델이 옳은 방향으로 학습될 수 있도록 도와줍니다.
- 훈련과 테스트 과정을 모니터일할 지표: 여기에서는 정확도 (정확히 분류된 이미지의 비율) 만 고려하겠습니다.
(4) evaluate
model.evaluate(test_images, test_labels)
model.fit(train_images,train_labels,epochs=5,batch_size=128)
# 2-7) 새로운 데이터 모델 평가하기 p65
loss,acc=model.evaluate(test_images,test_labels)
print(f'손실은{loss} 이고 정확도는 {acc}입니다.')
출처:
https://all-record.tistory.com/151
https://colab.research.google.com/drive/1oCD4jjXsLPnfX19JchWUXznEXTm27CzV?hl=ko#scrollTo=HHVg1wMST67p

새싹 빅테이터 개발자