** 오전 2시간(9:00~15:00) 쪽지 시험 보았다. -> (크롤링, 머신러닝 ,데이터분석, 데이터 수집과 전처리, 모델링 성능 평가,탐색적 데이터 분석)
** 오후 2시간 (15:00~17:00) 오라클 처음부터 복습 했다.
[ 데이터 분석 6문제 ]
1, 한국어 형태소분석을 할 때, 자연어 단어를 숫자벡터로 바꾸어 주는 단어임베딩 알고리즘은
무엇입니까?
이 알고리즘을 이용하면 단어간의 거리를 기반으로 뎃셈뺄셈과 같은 연산, 단어유사도 측정을 할
수 있다
-> 인코딩
- 위의 알고리즘과 달리, 단어의 순서를 무시하고 단어의 출현빈도를 나타내도록 한 주머니(Bag)
에 모두 담는 단어임베딩 방식은 무엇입니까
-> BOW
- 자연어처리 분야에서 Corpus (복수형은 corpora)는 우리말로 무엇이라고 합니까
-> 말뭉치
- 한국어 형태소 분석 라이브러리는 KoNLPy가 있고 형태소 분석기는 여러종류가 있다.
한국어형태소 분석기를 3개만 써 봅시다.
-> 트위터,한나눔,꼬고마
- 단어의 N-gram의 종류에는 무엇이 있는지 3가지만 써 주세요.
->
- 다음 코드에서 명사, 조사와 같은 품사를 분류하도록 밑줄 부분에 들어갈 코드를 쓰세요.
from konlpy.tag import Okt
okt = Okt( )
malist = _____ . _____ ("아버지 가방에 들어가신다", norm= True, stem= True)
print(malist)->
[ 데이터 수집과 전처리 ]
- from selenium import webdriver 한 후
selenium을 통해서 "www.naver.com"에 접속하시오
->
from selenium import webdriver
from urllib import request
url="https://www.naver.com/"
request.urlopen(url).read()- 네이버의 검색 창에 selenium을 입력하고 검색한 화면까지 이동합니다.
다음 코드의 마지막 괄호안 ( ------ )에 들어갈 인자를 넣어 주세요.
search_window = driver.find_element_by_css_selector("#query")
search_window.clear()
search_window.send_keys("selenium")
search_window.send_keys( ------ )
-> (Keys.ENTER)
3, 다음은 문제에서 사용할 코드이다.
from bs4 import BeautifulSoup
html = """
<!DOCTYPE html>
<body>
<h1>ABC</h1>
<div id="hangle">가나다</div>
<ul>
<li class="one">1번</li>
<li class="two">2번</li>
</ul>
</body>
</html>ㄴ
"""
soup = BeautifulSoup(html, 'lxml'여기에 다음 3가지를 출력하도록 합니다. 각각 한 라인씩 총 3개라인.
1) 'ABC'를 출력하는 코드를 작성하시오.
2) id 선택자를 사용하여 '가나다'를 출력하는 코드를 작성하시오.
3) class 선택자를 이용하여 '2번'을 출력하는 코드를 작성하시오
->
title= soup.select('body>h1')
title.text
->
title=soup.findall(id = "hangle")
title.text
->
title=soup.find_all(class = "two")
title.text
[ 머신러닝 알고리즘 ]
- 머신러닝 알고리즘 중에서
분류, 회귀, 군집에 맞는 알고리즘을 각각 1개씩 써 봅시다.
->
로지스틱, 랜덤포레트, k-mean
랜덤포레스트, 라쏘 ,K-평균
- 분류, 회귀, 군집에 맞는 평가방법을 각각 1가지 이상씩 써 봅시다.
-> 정확도, rmse,elbow
- 사이킷런에서 Estimator란 무엇입니까?
-> Classifier와 Regressor를 합쳐서 Estimator 클래스라 부릅니다.
- 분류 알고리즘 중에서 가장 각광받는 부스팅 모델로서 병렬처리가 가능한 두가지 모델은?
-> 병렬처리- lightGBM, XGBoost
- 의사결정나무(Decision Tree)에서 36개의 피쳐를 가진 데이터셋이 있다.
의사결정나무의 앙상블인 랜덤포레스트 모델을 fitting 할 때, 랜덤하게 택하는 변수의 개수는 몇
개인가?
-> 6
- 의사결정나무에서 가지치기(pruning)을 하는 이유는?
-> 과적합을 피하기 위해
- 고유벡터와 고유값을 이용하여 여러 피처로 구성된 높은 차원에서 소수의 낮은 차원으로 차원
축소를 하는 대표적인 알고리즘은?
-> PCA
- 아래 밑줄 친 세곳에 들어갈 코드를 각각 쓰세요.
(라이브러리 import 부분은 생략하였음)
dataset = load_breast_cancer()
ftr = dataset.data
target = dataset.target
X_train, X_test, y_train, y_test= _____(1)_____ (ftr, target, test_size=0.2, random_state=156 )
lgbm_wrapper = LGBMClassifier(n_estimators=400)
evals = [(X_test, y_test)]
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)
preds = lgbm_wrapper._____(2)_____ (X_test)
pred_proba = lgbm_wrapper._____(3)_____ (X_test)[:, 1] # 예측의 확률을 리턴->(1) train_test_split
->(2)predict
->(3)predict_proba
[ 모델링 성능평가 및 개선]
문제1 .다음 설명에 맞는 용어를 순서대로 쓰세요
1) 머신러닝 모델의 타당성을 검증하는 방법 중의 하나로 특정 데이터를 훈련 전용 데이터 와 테스트 전용 데이터로 분할한 뒤 훈련 데이터를 활용해 학습하고, 테스트 데이터로 테스트해서 학습의 타당성을 검증하는 방법
-> 교차검증(cross validation)
2) 어떤 매개변수가 적절한지 자동으로 조사하는 방법으로 각 매개 변수를 적당한 범위 내부에서 변경하면서 가장 성능이 좋을 때 값을 찾는 방법
-> 그리드 서치 (Grid search)
3) 데이터를 k 개로 분할해 분할된 각 데이터를 테스트 전용데이터 나머지를 훈련 전용 데이터로 사용해 분류 정밀도를 구한 뒤 구한 k개의 분류 정밀도의 평균을 구해 최종적인 분류 정밀도를 구하는 방법
-> k-fold
문제2 . 최솟값은 0, 최댓값은 1로 바꾸는 최소최대 정규화는 MinMaxScaler가 있습니다. 이를 직접 람다함수로 만들어 주세요
-> lambda x:(x-x.min())/(x.max()-x.min())
문제 3.
TP: 1 FP: 2 FN: 3 TN: 4 일 때
Accuracy, Precision, Sensitivity, Recall, Specificity, FPR, TPR을 순서대로 '분수형태'로 써주세요.
->Accuracy:
->Precision:
->Sensitivity:
->Recall:
->Specificity:
->FPR:
->TPR:
문제4 .
import pandas as pd
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
from sklearn import datasets
을 하여 필요한 라이브러리를 로딩한 후
wine = datasets.load_wine() 을 실행하여 wine 데이터셋을 가져옵니다.
이후 svm을 모델로 사용하여 정확도(accuracy) 를 구하는 코드들 순서대로 작성해 주세요.
(코드 길이는 약 10라인 가량이며 실행후 정확도는 약 60%정도 나옵니다
->
wine_data = wine["data"]
wine_label = wine.target
#print("wine target값:", wine_label)
#print("wine target명:", wine.target_names)
wine_df = pd.DataFrame(data = wine_data, columns = wine.feature_names)
wine_df['label'] = wine.target
X_train, X_test, y_train, y_test = train_test_split(wine_data,wine_label)
from sklearn.tree import svm
# svm객체 생성
clf_sv = svm()
# 학습수행
clf_sv.fit(X_train, y_train) #학습한다. 적합한다. 훈련한다.
# 학습이 완료된 DecisionTreeClassifier 객체에서 테스트 데이터 세트로 예측 수행.
y_pred = clf_sv.predict(X_test)
# 예측 성능 평가하기
from sklearn.metrics import accuracy_score
print("예측 정확도: {0:.4f}".format(accuracy_score(y_test,y_pred)))[파이썬 라이브러리 활용]
- 판다스에서 1차원, 2차원 자료를 부르는 이름을 각각 무엇이라 하는가?
-> 시리즈,데이터 프라임
- 다음 코딩의 출력 결과로 옳은 것은?
number=[1,2,3]
nums=pd.Series(numbers)
print(nums)
->
01
12
23
dtype : int64
- 다음과 같은 데이터프라임을 만들기 위한 코드로 알맞는 것은?
___ 나이/성별/학교
철수 15/남/남중
영희 17/여/여중
-> pd.DataFrame([[15,남,남중],[17,여,여중]],index=['철수','영희'], columns=['나이','성별','학교'])
- 다음과 같은 객체의 이름은 df라 하자.
___ 나이/성별/학교
철수 15/남/남중
영희 17/여/여중
나이만 남기려 한다. 답은?
-> df.drop([‘성별’,'학교'],axis=1,inplacs=True)

-> 1
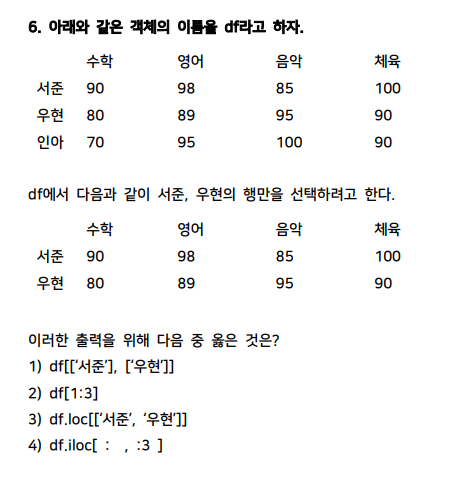
-> 3

-> 4

-> mean_age

-> pd.read_csv(), df.to_csv()

-> df.describe()
[탐색적 데이터 분석]
타이타닉 데이터를
titanic = pd.read_csv('datasets/titanic/titanic.csv')
로 저장로 저장하였습니다.
1번. titanic 'Age'칼럼의 평균값을 'impute_value' 라는 객체에 저장하고 'Age'의 결측치를 대체하려고 할때 아래 빈칸에 들어갈 코드는?
impute_value = titanic['Age'].mean()
titanic['Age'] = titanic ['Age'].______(impute_value)-> fillna
2.'Sex'칼럼은 데이터타입이 object 인 상태인데, 이것을 'category'형으로 바꾸어 주세요.
-> titanic['Sex'] = titanic['Sex'].astype('category')
3번. 'Sex'칼럼의 'male', 'female'을 여자는 1 남자는 0으로 표현하도록 int형태로
각각 'IsFemale'이라는 새로운 칼럼에 저장하는 코드를 작성하세요.
-> titanic['IsFemale'] = np.where(titanic['sex'] == male, '0', '1')
- tips = sns.load_dataset("tips")를 하여 tips에 대한 데이터셋을 로딩하였다.
day와 smoker에 대하여 그룹을 만들고 그룹별로 size와 tip의 최댓값을 구해 주세요.
-> tips.groupby(['day','smoker'])[['tip','size']].agg()
5 위와 같은 조건에서 size는 평균값을, tip은 최댓값을 적용하여 구해 주세요.
->
6번 from datetime import datetime 를 사용하여 datetime 모듈을 로딩하고
1) 현재 시간을 구한다., (datetime 겍체)
2) 현재시간을 년, 월, 일의 문자열로 나타낸 후 (문자열 객체)
3) 위 문자열을 다시 datetime 객체로 변환시켜주세요. (datetime 겍체)
->(1) date.today()
->(2)today.isoformat()
->(3) date.fromisoformat()
