크롤링(crawling)
크롤링(crawling) 혹은 스크레이핑(scraping)은
웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다.
크롤링하는 소프트웨어는 크롤러(crawler)라고 부른다.
서버 검색이 막혔을때
- user agent 검색(구글링)
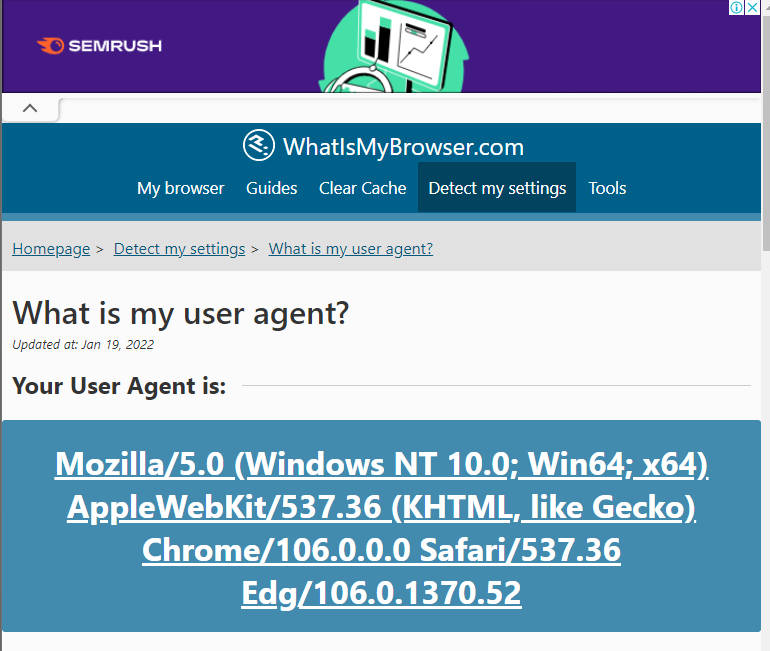
- header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.52"}
##단, requests를 import시 header을 저장 안해도 가능했다.!!->(이유모름)
3. html = requests.get(url, headers=header).text
* request / requests : url 입력시
< 정리 > 클롤링 라이브러리의 차이.
request = .urlopen(url)
requests = get(url).text
* request / requests : 주소 입력시
from urllib import request는
url="https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%ED%94%84%EB%9E%91%EC%8A%A4"(프랑스라는 뜻)
import requests는
words = '프랑스'
url=f"https://search.daum.net/search?w=news&nil_search=btn&DA=NTB&enc=utf8&cluster=y&cluster_page=1&q={words}"
python BeautifulSoup
파이썬 BeautifulSoup은 HTML 문서를 분석 할 수 있는 라이브러리 입니다.
이를 이용하여 HTML 태그에 쉽게 접근 하고 데이터를 추출할 수 있습니다.
BeautifulSoup은 find(), select()등 여러가지 있는데,
하나만 제대로 알고 있어도 데이터를 추출하는 큰 어려움이 없습니다.
* find / select : 차이점
find
- find:한개만 (첫번째 녀석만)
- find_all: 다 찾는다. (보통 10개)
select
- select_one: 한 녀석만
- select: 다 찾는다.
크롤링 핵심 코드 패턴
- 파싱을 할 수 있는 parser는 여러가지가 있으나, 가장 대표적으로 쓰는 parser는 "html.parser" 임
- soup.find() 함수로 원하는 타켓을 지정할 수 있음(단, 1개만 선택됨)
- 변수.get_text() 함수로 추출한 부분의 text를 가져올 수 있음
- 다양한 속성을 통해서 원하는 타겟을 더 세밀하게 추출할 수 있음
- data = soup.find("p", class_ = "클래스명")
- data = soup.find("p", "클래스명")
- data = soup.find("p", attrs = {"속성명":"속성값"})
- data = soup.find(id="id명")
select


참조&출처:
- https://yrohh.tistory.com/20
- https://velog.io/@jewon119/01.Python-%EA%B8%B0%EC%B4%88-%ED%81%AC%EB%A1%A4%EB%A7%81-%EA%B8%B0%EC%88%A0%EC%9D%98-%EC%9D%B4%ED%95%B4
- https://velog.io/@jisu0807/TIL-requests%EC%99%80-BeutifulSoup-%EB%9D%BC%EC%9D%B4%EB%B8%8C%EB%9F%AC%EB%A6%AC-%EC%82%AC%EC%9A%A9
- https://www.fun-coding.org/crawl_basic2.html

새싹 빅테이터 개발자