

https://colab.research.google.com/drive/17jkzmhVqdvMx6tUpEVKAYFP5zokFF7UO#scrollTo=p5KlcD80hTTq
http://localhost:8888/lab/tree/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D.ipynb
머신러닝 이란,
#딥러닝에서 이어지는 내용이다.
#딥러닝이 못하는거 머신러닝이 한다.
(데이터량이 많지 않아서, 병원->희귀병.)
#중요도: 딥러닝 > 머신러닝
#4. 분류
0,x문제 답이 정해져 있음
예) 은행 대출은 받아 말아?
#5. 회귀
숫자 맞추기
예) 키가 얼마나 되는가?
#7. 군집화
모의는거
어느것이 맞는지 모르는거
답이 정해져 있지 않음.
사이킷런으로 시작하는 머신러닝
(1)
#사이킷런 임폴트 하기
import sklearn(2)
#버전 확인하기
sklearn.__version__->'1.0.2'
(3)
#리스트 찾아보기
pip list | findstr sk(4)
#key 값은 몇개? values
iris.keys()-> dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
첫번째 머신러닝 만들기 (붓꽃 품종 예측하기) p86
1. 내장 데이터셋 p87
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
- sklearn.datasets : 내의 모듈은 사이킷런에서 자체적을 제공하는 데잍 세트를 생성하는 모듈의 모임. -> 예제 데이터
- sklearn.tree : 내의 모듈운 트리 기반 ML 알고리즘을 구현한 클래스 모임입니다.
- sklearn.model_selection : 은 학습 데이터와 검증데이터, 예측 데이터로 데이터를 분리하거나 최적의 하이퍼 피라미터로 평가하기 위한 다양한 모듈의 모임.
- load_iris() : 붓꽃 데이터 세트를 생성하는 데 이용합니다.
- DecisionTreeClassifier : ML 알고리즘은 의사 결정 트리(Decision Tree) 알고리즘으로 이를 구현하기 위해 사용합니다.
- train_test_split() :데이터 세트를 학습 데이터와 테스트 데이터로 분리하는데 함수를 사용한다.
2. p88
import pandas as pd
#붓꽃 데이터 세트를 로딩합니다.
iris = load_iris()
#iris.data는 Iris 데이터 세트에서 피처(feature)만으로 된 데이터를 numpy로 가지고 있습니다.
iris_data = iris["data"]
#iris.target은 붓꽃 데이터 세트에서 레이블 (결정 값) 데이터를 numpy로 가지고 있습니다.
iris_label = iris.target
print("iris target값:", iris_label)
print("iris target명:", iris.target_names)
#붓꽃 데이터 세트를 자세히 보기 위해 DataFrame으로 변환합니다.
iris_df = pd.DataFrame(data = iris_data, columns = iris.feature_names)
iris_df['label'] = iris.target
iris_df.head(3)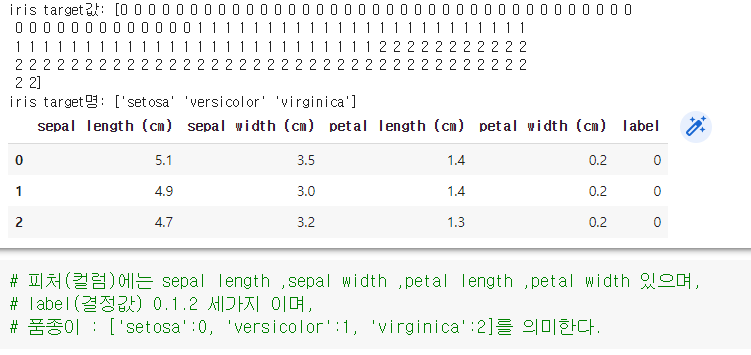
#붓꽃 데이터 세트를 로딩합니다.
iris = load_iris()
- load_iris() 함수를 이용해 불꽃 데이터 세트를 로딩한 후, 피처들과 데이터 값이 어떻게 구성돼 있는지 확인하기 위해 DataFrame으로 변환하겠다.
p89
X_train, X_test, y_train, y_test = train_test_split(iris_data,iris_label)
# DecisionTreeClassifier 객체 생성
dt_clf = DecisionTreeClassifier()
# 학습수행
dt_clf.fit(X_train, y_train) #학습한다. 적합한다. 훈련한다.
# 학습이 완료된 DecisionTreeClassifier 객체에서 테스트 데이터 세트로 예측 수행.
y_pred = dt_clf.predict(X_test)
# 예측 성능 평가하기
from sklearn.metrics import accuracy_score
print("예측 정확도: {0:.4f}".format(accuracy_score(y_test,y_pred)))-> 예측도 0.9737 나옴.
X_train, X_test, y_train, y_test = train_test_split(iris_data,iris_label)
- 학습용 데이터와 테스트용 데이터를 분리해 보겠다.
- 사이킷런은 train_test_split() API를 제공한다.학습 데이터와 테스트 데이터를 쉽게 분리할 수 있다.
- iris_data 피처 데이터 세트
- iris_label 레이블 데이터 세트
- X_train, 학습용 피처 데이터 세트
- X_test, 테스트용 피처 데이터 세트
- y_train, 학습용 레이블 데이터 세트
- y_test 테스트 레이블 데이터 세트
# DecisionTreeClassifier 객체 생성
dt_clf = DecisionTreeClassifier()
- DecisionTreeClassifier : 사이킷런의 의사 결정 트리 클래스 생성합니다.
- fit() : 메서드에 학습용 데이터 속성과 결정값 데이터를 입력해 호출하면 학습을 수행한다.
# 학습이 완료된 DecisionTreeClassifier 객체에서 테스트 데이터 세트로 예측 수행.
y_pred = dt_clf.predict(X_test)
- 예측은 반드시 학습 데이터가 아닌 다른 데이터를 이용해야하며, 보통 테스트 데이터를 이용한다.
- predict() 메서드에 테스트용 피처 데이터 세트를 입력해 호출하면 학습된 모델 기반에서 테스트 데이터 세트에 대한 예측값을 반환하게 됩니다.
# 예측 성능 평가하기
from sklearn.metrics import accuracy_score
print("예측 정확도: {0:.4f}".format(accuracy_score(y_test,y_pred)))
- 정확도는 예측결과가 실제 레이블값과 얼마나 정확하게 맞는지 평가하는 지표이다.
- accuracy_score() : 정확도 측정 함수. 첫번째 파라미터로 실제 레이블 , 두번째 예측 렝블 세트 입력하면 됨.
< 프로세스 정리>
1. 데이터 세트 분리 : 데이커를 학습 데이터와 테스트 데이터로 분리합니다.
2. 모델 학습 : 학습 데이터를 기반으로 ML알고리즘을 적용해 모델을 학습시킵니다.
3. 예측 수행 : 학습된 ML모델을 이용해 테스트 데이터의 분류 (즉, 붓꽃 종류 )를 예측합니다.
4. 평가 : 이렇게 예측된 결과 값과 테스트 데이터의 실제 결괏값을 비교해 ML 모델 성능을 평가합니다.

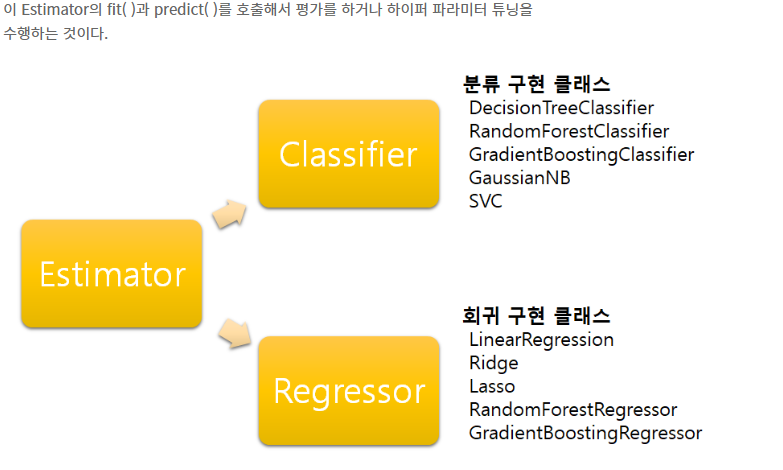
Estimator 이해 및 fit(), predict() 메서드 p91
- ML 모델 학습 fit()
- 학습된 모델의 예측을 위해 predict()
- 지도학습의 분류(Classification), 회귀(Regression)의 다양한 알고리즘을 구현한 모든 사이킷런 클래스는 fit()과 predict()만을 이용해 간단하게 학습과 예측 결과를 반환한다.
분류 알고리즘을 구현한 클래스를 Classifier, 회귀 알고리즘을 구현한 클래스를 Regressor로 지칭합니다.
Classifier와 Regressor를 합쳐서 Estimator 클래스라 부릅니다.
p92

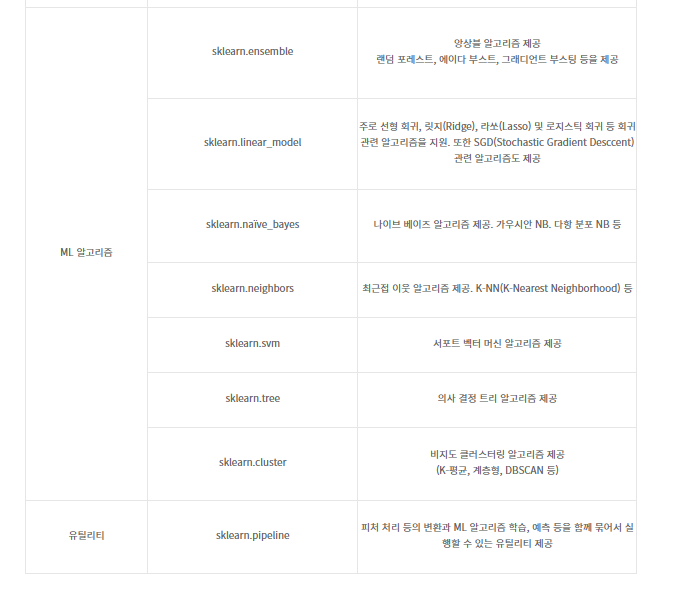
내장된 예제 데이터 세트 p94
- fetch 계열의 명령은 최초 사용시 인터넷에서 내려받아 홈 디렉터리 아래의 scikit_learn_data라는 서브 디렉터리에 저장한 후 추후 불러들이는 데이터다.
fetch_convtype() : 회귀 분석용 토지 조사 자료
fetch_20newsgroups() : 뉴스 그룹 텍스트 자료
fetch_olivetti_faces() : 얼굴 이미지 자료
fetch_lfw_people() : 얼굴 이미지 자료
fetch_lfw_pairs() : 얼굴 이미지 자료
fetch_rcv1() : 로이터 뉴스 말뭉치
fetch_mldata() : ML 웹사이트에서 다운로드

< data, target 확인 >
#data, target 타입, 확인
from sklearn.datasets import load_iris
iris = load_iris()
type(iris)-> sklearn.utils.Bunch
- Bunch 클래스는 파이썬 딕셔너리 자료형과 유사하다.
- 데이터 세트에 내장돼 있는 대부분의 데이터 세트는 딕셔너리 형태 값을 반환한다.
< 키 값 확인 >
iris.keys()= 'data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'data는 피처의 데이터 세트를 가리킵니다. (ndarray)
target은 분류 시 레이블 값, 회귀일 떄는 숫자 결과값 데이터 세트입니다.(ndarray)
target_names는 개별 레이블의 이름을 나타냅니다.(ndarray,list)
feature_names는 피처의 이름을 나타냅니다.(ndarray,list)
DESCR은 데이터 세트에 대한 설명과 각 피처의 설명을 나타냅니다.(string)
출처:
https://hun931018.tistory.com/29 ->사이킷럿의 주요 모듈
https://hun931018.tistory.com/27?category=1092992 -> sklearn 기초 - 붓꽃 품종 예측하기
출처: https://asthtls.tistory.com/1178?category=904088 [포장빵의 IT:티스토리]
