출처 : https://heytech.tistory.com/434
출처 : https://dacon.io/forum/405817?page=1&dtype=tag&fType

분류모델을 평가하기 위해서는 TP, TN, FP, FN의 개념을 이해해야 합니다.
- TP(True Positive) : 실제로 Positive인 정답을 Positive라고 예측
- TN(True Negative) : 실제로 Negative인 정답을 Negative라고 예측
- FP(False Positive) : 실제론 Negative인 정답을 Positive라고 예측
- FN(False Negative) : 실제로 Positive인 정답을 Negative라고 예측
1. Example-based Evaluation
Example-based Evaluation은 test example마다 정답 label과 예측 label 간의 차이를 구하고 평균을 취하는 평가 방법입니다.
1.1. Exact-Match Ratio(EMR)
'Subset accuracy'라고도 부름
평가지표의 이름처럼 엄격하게 얼마나 모델이 test example마다 모든 label을 잘 분류했는지 측정하는 평가지표
일부 label만 정답을 맞히는 경우는 무시하고 오직 모든 label에 대해 정답을 맞힌 경우만 평가
EMR 값이 클수록 모델 성능이 우수하다고 평가
1.2. Accuracy
Exact-Match와 다르게 전체 test example별 label의 정답을 맞힌 비율의 평균
Accuracy 값이 클수록 모델 성능이 우수하다고 평가

1.3. Precision
모델이 Positive로 예측한 label의 개수 대비 실제 정답 label이 Positive인 개수 비율
Precision 값이 클수록 모델 성능이 우수하다고 평가
- Recall과 Trade-off 관계

1.4. Recall
실제 정답 label이 Positive인 개수 대비 모델이 Positive로 예측한 label의 개수 비율
Recall 값이 클수록 모델 성능이 우수하다고 평가
Precision과 Trade-off 관계
1.5. F1 Score
Precision과 Recall의 조화 평균
F1 값이 클수록 모델 성능이 우수하다고 평가
조화 평균 사용이유: 산술평균과 비교했을 때 Class imbalance의 bias 작음

1.6. Hamming Loss
test example마다 전체 라벨 중 몇 개의 라벨을 틀렸는지 계산하여 평균을 취한 값
Hamming Loss 값이 작을수록 모델 성능이 우수하다고 평가
그 외
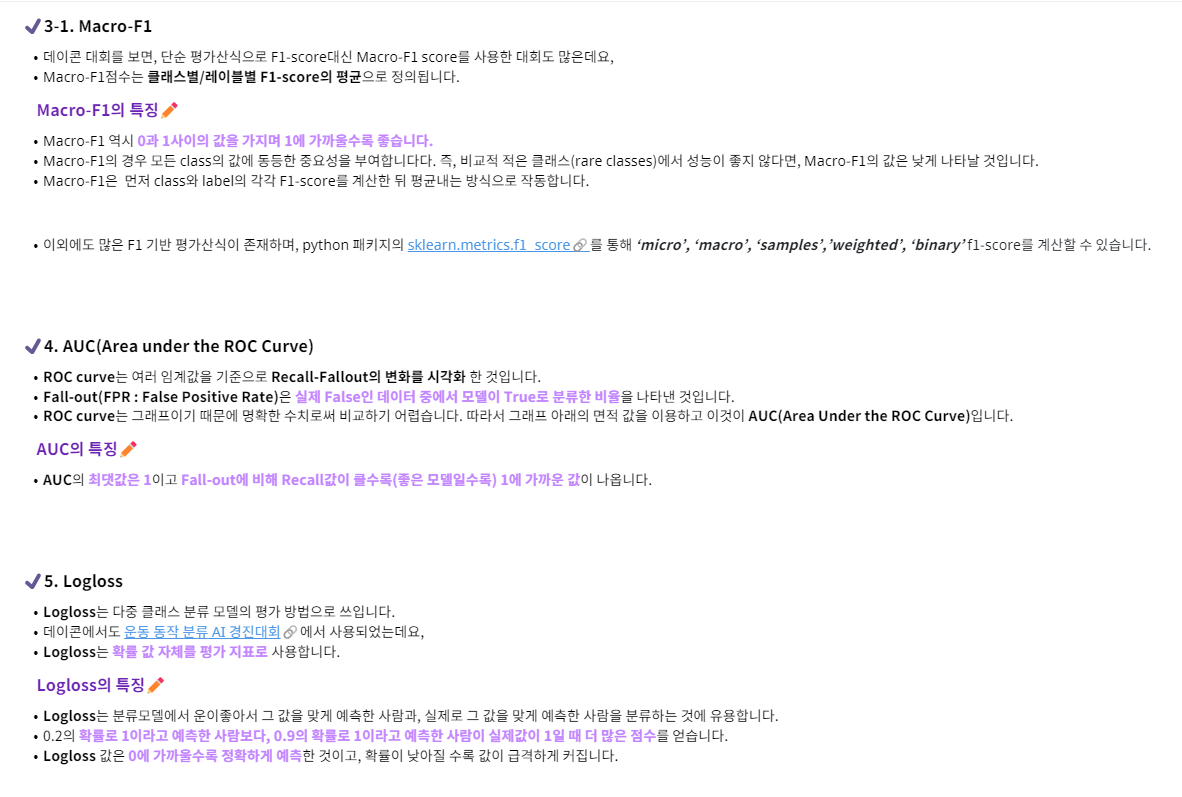
2. Label-based Evaluation
label마다 예측값과 실젯값의 차이를 계산한 후 전체 label에 대해 평균을 취하는 평가 방식
label마다 평가 지표를 계산하기 때문에 label마다 binary classification 문제이므로 기본적인 binary classification 평가 지표인 Precision, Recall, F1, ROC 등 사용 가능
평균을 구하는 방법에 따라 3가지 방법 존재
- 1) Macro-average : 모든 label의 중요도가 비슷하고, label마다 데이터 개수가 imbalance한 경우, macro-average를 사용하는 것이 효과적
- 2) Micro-average : label마다 데이터 개수가 균형적이고(balanced) label마다 평가지표를 고려할 필요가 없을 때 효과적
- 3) Weighted-average : Label마다 데이터가 imbalanced일 때 Label마다 support 하는 개수를 고려하고 싶은 경우 효과적
