Do it! BERT와 GPT로 배우는 자연어처리
:트랜스포머 핵식 원리와 허깅페이스 패키지 활용법
1-1 딥러닝 기반 자연어 처리 모델 p12
기계의 자연어 처리
: 문장을 형태소(토큰화), 백터화 한다.
- 입력 -> 모델(함수) -> 출력(확률)
:자연어 처리 모델으 자연어를 입력받아서 해당 입력이 특정 범주일 확률을 반환하는 확률 함수이다.
딥러닝
: 데이터 패턴을 스스로 익히는 인공지능의 한 갈래입니다. 여기서 딥이란 많은 은닉층을 사용한다는 의미입니다.
- 딥러닝 가운데서도 BERT와 GPT이 딥러닝 기반 자연어 처리 모델이라고 합니다.
1-2 트랜스퍼 러닝(전이 학습) p17
트랜스퍼 러닝
: 특정 테스크르르 학습한 모델을 다른 태스크 수행에 재사용하는 기법을 가리킵니다.
- BERT와 GPT도 트랜스퍼 러닝이 적용되었습니다.
업스트림 태스크
- 다음 단어 맞히기
- 빈칸 채우기
다운스트림 태스크
: 본질은 분류입니다. 학습방식은 모두 파인튜닝 입니다.
- 파인튜닝 : 프리트레인을 마친 모델을 다운스트림 태스크에 맞게 업데이트를하는 기법닙니다.
- 문서분류 : 분류의 범주
- 자연어 추론 : 두 문장 사이의 관계가 참, 거짓
- 개체명 인식 : 단어별로 기관명, 인명, 지명 속하는지
- 질의응답 : 각 단어가 정답의 시작일 확률, 끝일 확률 구하기
- 문장생성 -> GPT 에서 사용 : 어휘 전체의 확률값
1-3 학습 파이프라인 소개
- 각종 설정값 정하기
- 데이터 내려받기
- 프리트레인을 마친 모델 준비하기
- 토큰나이저 준비하기
- 데이터 로더 준비하기
- 태스크 정의하기
- 모델 학습하기
이 책에서 진행하는 모든 실습은 ratsnlp라는 오픈소스 패키지를 사용합니다.
https://github.com/ratsgo/ratsnlp
1. 각종 설정값 정하기
:모델을 만들려면 가장 먼저 각종 설정값을 정해야 한다.
- 어떤 프리트레인 모델을 사용할건지
- 학습에 사용할 데이터는 무엇인지
- 학습 결과는 어디에 저장할지
- 하이퍼파라미터 역시 미리 정해둬야 한다.
하이퍼파라미터: 모델 구조와 학습 등에 직접 관계된 설정값을 가리킵니다.(러닝 레이트, 베치 크기)
2. 데이터 내려받기
다운로드 툴킷 코포라 오픈소스 파이썬 패키지 사용합니다.
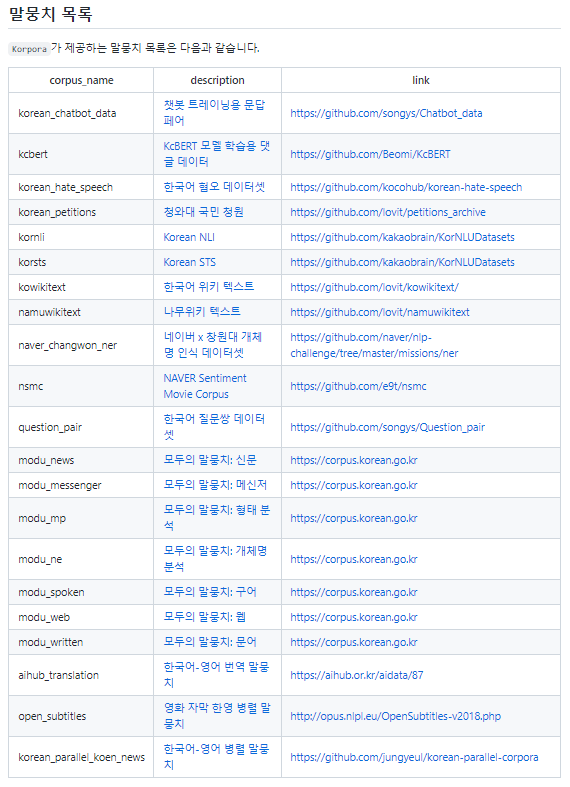
https://github.com/ko-nlp/korpora
-
Korpora: Korean Corpora Archives
최근 자연어 처리에 관심이 높아지면서 정부와 기업은 물론 뜻있는 개인에 이르기까지 데이터를 무료로 공개하는 추세입니다. 하지만 데이터가 곳곳에 산재해 있다보니 품질 좋은 말뭉치임에도 그 존재조차 잘 알려지지 않은 경우가 많습니다. 파일 포맷과 저장 형식 등이 각기 달라 사용이 쉽지 않습니다. 개별 사용자들은 다운로드나 전처리 코드를 그때그때 개발해서 써야 하는 수고로움이 있습니다.Korpora는 이 같은 불편함을 조금이나마 덜어드리기 위해 개발한 오픈소스 파이썬 패키지입니다. Korpora는 말뭉치라는 뜻의 영어 단어 corpus의 복수형인 corpora에서 착안해 이름 지었습니다. Korpora는 Korean Corpora의 준말입니다. Korpora가 마중물이 되어 한국어 데이터셋이 더 많이 공개되고 이를 통해 한국어 자연어 처리 수준이 한 단계 업그레이드되기를 희망합니다.
3. 프리트레인을 마친 모델 준비하기
대규모 말뭉치를 활용한 프리트레인에는 많은 리소스가 필요합니다.
미국 자연어 처리 기업 허깅페이스에서 만든 트랜스포머라는 오픈소스 파이썬 패키지를 주목해야 합니다.
https://github.com/huggingface/transformers
- 이 책에서는 BERT, GPT 같은 트랜스포머 계열 모델로 실습을 한다.
4. 토크나이저 준비하기
자연어 처리 모델의 입력은 대개 토큰입니다. 여기서 토큰은 문장보다 작은 단위입니다.
- 토크나이저 :토큰화를 수행하는 프로그램
5.데이터 로더 준비하기
파이토치에서 데이터 로더 라는게 포함돼 있다.
-
데이터 로더 : 데이터를 배치단위로 모델에 밀어 넣어주는 역활을 합니다. 전체 데이터 가운데 일부 인스턴스를 뽑아 배치를 구성합니다.
-
컬레이트 : 배치 모양 등을 정비해 최종 입력으로 만들어 주는 과정 (차이썬 리스트 -> 파이토치 텐서로 변환)
6. 태스크 정의하기
이 책에서는 모델 학습을 할 때 파이토치 라이트닝이라는 라이브러리를 사용합니다.
- 파이토치 라이트닝 : 딥러닝 모델을 학습할 때 반복적인 내용을 대신 수행해줘 사용자가 모델 구축에만 신경쓸 수 있도록 돕는 라이브러리입니다.
이 책에서는 파이토치 라이트닝이 제공하는 lightning 모듈을 상속받아 task를 정의합니다.
task에는 앞서 준비한 모델과 최적화 방법, 학습과정 등이 정의돼 있습니다.
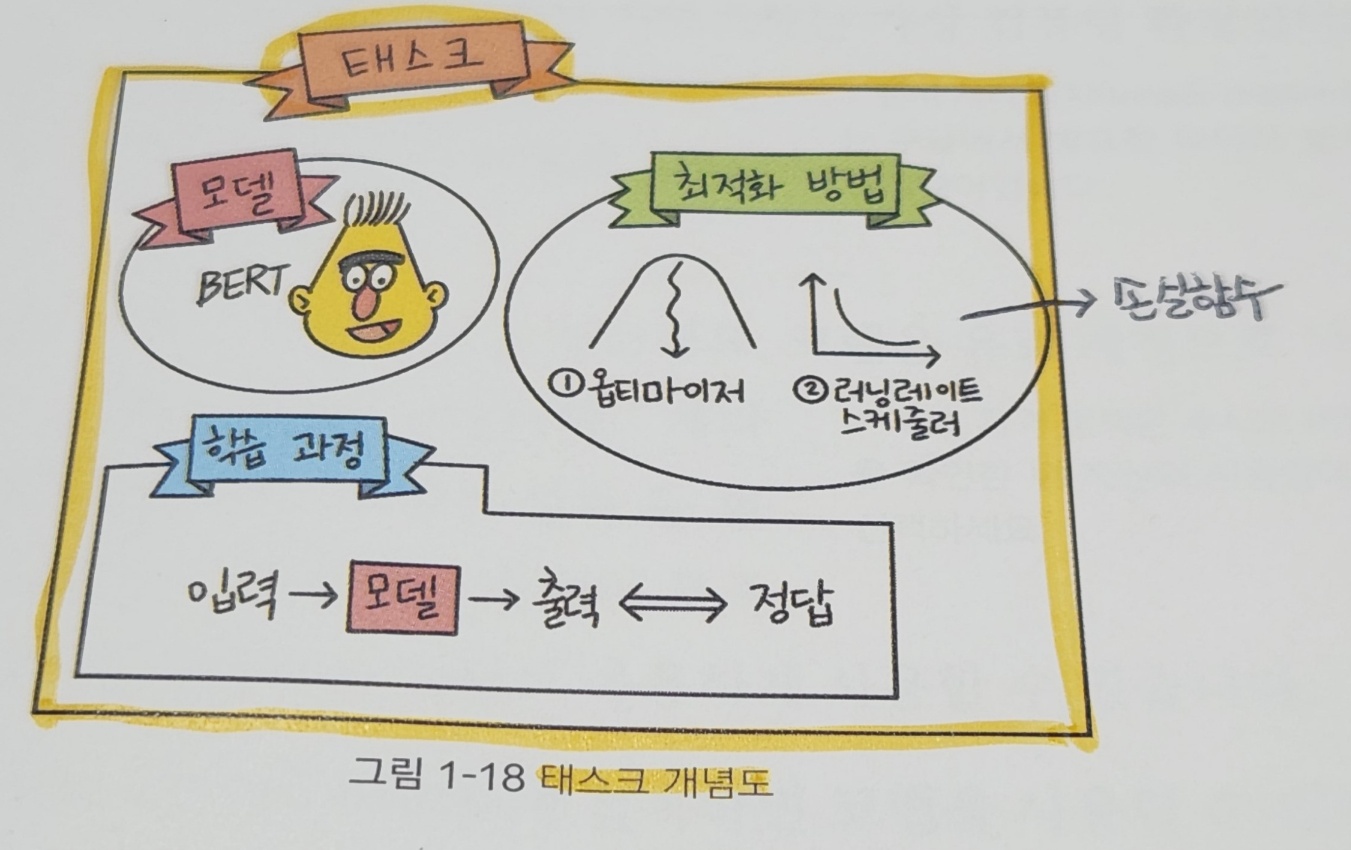
- 최적화 : 특정 조건에서 어떤 값이 최대나 최소가 되도록 하는 과정을 가리킵니다.
7. 모델 학습하기
트레이너 : 파이토치 라이트닝에서 제공하는 객체로 실제 학습을 수행합니다. (하드웨어 설정, 학습기록로깅, 체크포인트 저장 등 )
2-3 어휘 집합 구축하기 p52
BPE 기반 토크나이저 만들기 (실습)
# (1)의존성 패키지 설치
!pip install ratsnlp
# (2)구글 드라이브 연결
from google.colab import drive
drive.mount('/gdrive', force_remount=True)
# (3)NSMC 다운로드
from Korpora import Korpora
nsmc = Korpora.load("nsmc", force_download=True)
> [out put] Korpora 는 다른 분들이 연구 목적으로 공유해주신 말뭉치들을
손쉽게 다운로드, 사용할 수 있는 기능만을 제공합니다.
말뭉치들을 공유해 주신 분들에게 감사드리며, 각 말뭉치 별 설명과 라이센스를 공유 드립니다.
해당 말뭉치에 대해 자세히 알고 싶으신 분은 아래의 description 을 참고,
해당 말뭉치를 연구/상용의 목적으로 이용하실 때에는 아래의 라이센스를 참고해 주시기 바랍니다.
# Description
Author : e9t@github
Repository : https://github.com/e9t/nsmc
References : www.lucypark.kr/docs/2015-pyconkr/#39
Naver sentiment movie corpus v1.0
This is a movie review dataset in the Korean language.
Reviews were scraped from Naver Movies.
The dataset construction is based on the method noted in
[Large movie review dataset][^1] from Maas et al., 2011.
[^1]: http://ai.stanford.edu/~amaas/data/sentiment/
# License
CC0 1.0 Universal (CC0 1.0) Public Domain Dedication
Details in https://creativecommons.org/publicdomain/zero/1.0/
[nsmc] download ratings_train.txt: 14.6MB [00:00, 92.0MB/s]
[nsmc] download ratings_test.txt: 4.90MB [00:00, 38.1MB/s]
# 말뭉치 전처리
import os
def write_lines(path, lines):
with open(path, 'w', encoding='utf-8') as f:
for line in lines:
f.write(f'{line}\n')
write_lines("/content/train.txt", nsmc.train.get_all_texts())
write_lines("/content/test.txt", nsmc.test.get_all_texts())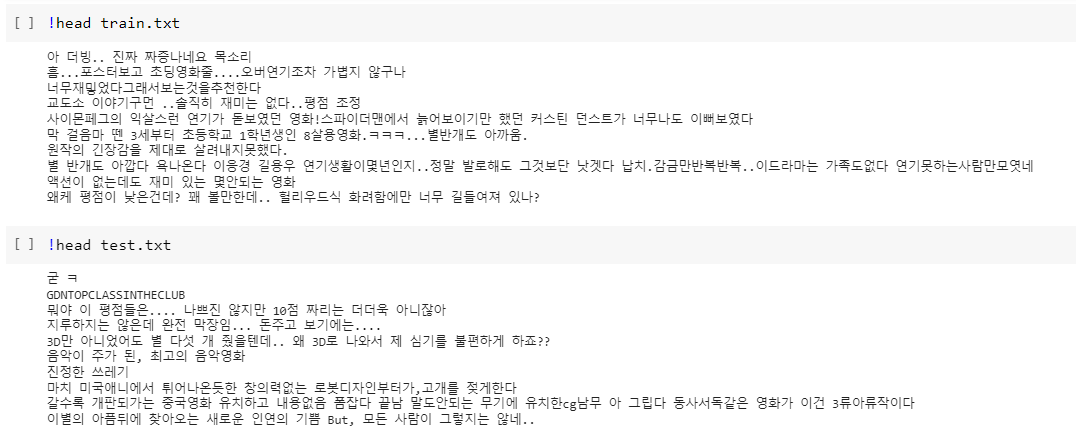
# 디렉터리 만들기
import os
os.makedirs("/gdrive/My Drive/nlpbook/bbpe", exist_ok=True)
# 바이트 수준 BPE 어휘 집합 구축축
from tokenizers import ByteLevelBPETokenizer
bytebpe_tokenizer = ByteLevelBPETokenizer()
bytebpe_tokenizer.train(
files=["/content/train.txt","/content/test.txt"],
vocab_size=10000,
special_tokens=["[PAD]"]
)
bytebpe_tokenizer.save_model("/gdrive/My Drive/nlpbook/bbpe")
# 확인
!cat /gdrive/My\ Drive/nlpbook/bbpe/vocab.json
!head /gdrive/My\ Drive/nlpbook/bbpe/merges.txt <본 내용과 도움이 되는 블로그 >
출처 :
https://velog.io/@binmuxiz/1.-%EB%94%A5%EB%9F%AC%EB%8B%9D-%EA%B8%B0%EB%B0%98-%EC%9E%90%EC%97%B0%EC%96%B4-%EC%B2%98%EB%A6%AC-%EB%AA%A8%EB%8D%B8
https://velog.io/@binmuxiz/%ED%8A%B8%EB%9E%9C%EC%8A%A4%ED%8D%BC-%EB%9F%AC%EB%8B%9D
