- Yolo5에 대해서
https://ssong915.tistory.com/43 블로그 정리.
특징
-
이미지 전체를 한번만 보는 것
R-CNN: 이미지를 여러장으로 분할하고 CNN 모델을 이용하여 이미지를 분석했다. 따라서 이미지 한장을 보더라도 여러장의 이미지를 분석하는 것과 같았다. 하지만 YOLO는 이러한 과정없이 이미지를 한 번만 보는 특징을 가지고 있다. -
통합된 모델을 사용하는 것
기존 Object Detectin 모델은 전처리모델 + 인공신경망 을 결합하여 사용했다. 하지만 YOLO에서는 위를 통합한 모델을 사용한다. -
실시간으로 객체를 탐지할 수 있는 것
기존의 R-CNN보다 6배 빠른 성능을 보여준다
4.YOLO 아키텍처(전체 구조-백본,넥,헤드 전체를 아우르는 뼈대를 말함.)
YOLO는 자체 맞춤 아키텍쳐 사용(다크넷을 가져다가 쓴다.)
번외) YOLOv4 (2020)
YOLOv4: Optimal Speed and Accuracy of Object Detection https://arxiv.org/pdf/2004.10934v1.pdf
- YOLOv3에 비해 AP(평균속도도), FPS가 각각 10%, 12% 증가
- YOLOv3와 다른 개발자인 AlexeyBochkousky가 발표
- v3에서 다양한 딥러닝 기법(WRC, CSP ...) 등을 사용해 성능을 향상시킴
- CSPNet 기반의 backbone(CSPDarkNet53)을 설계하여 사용
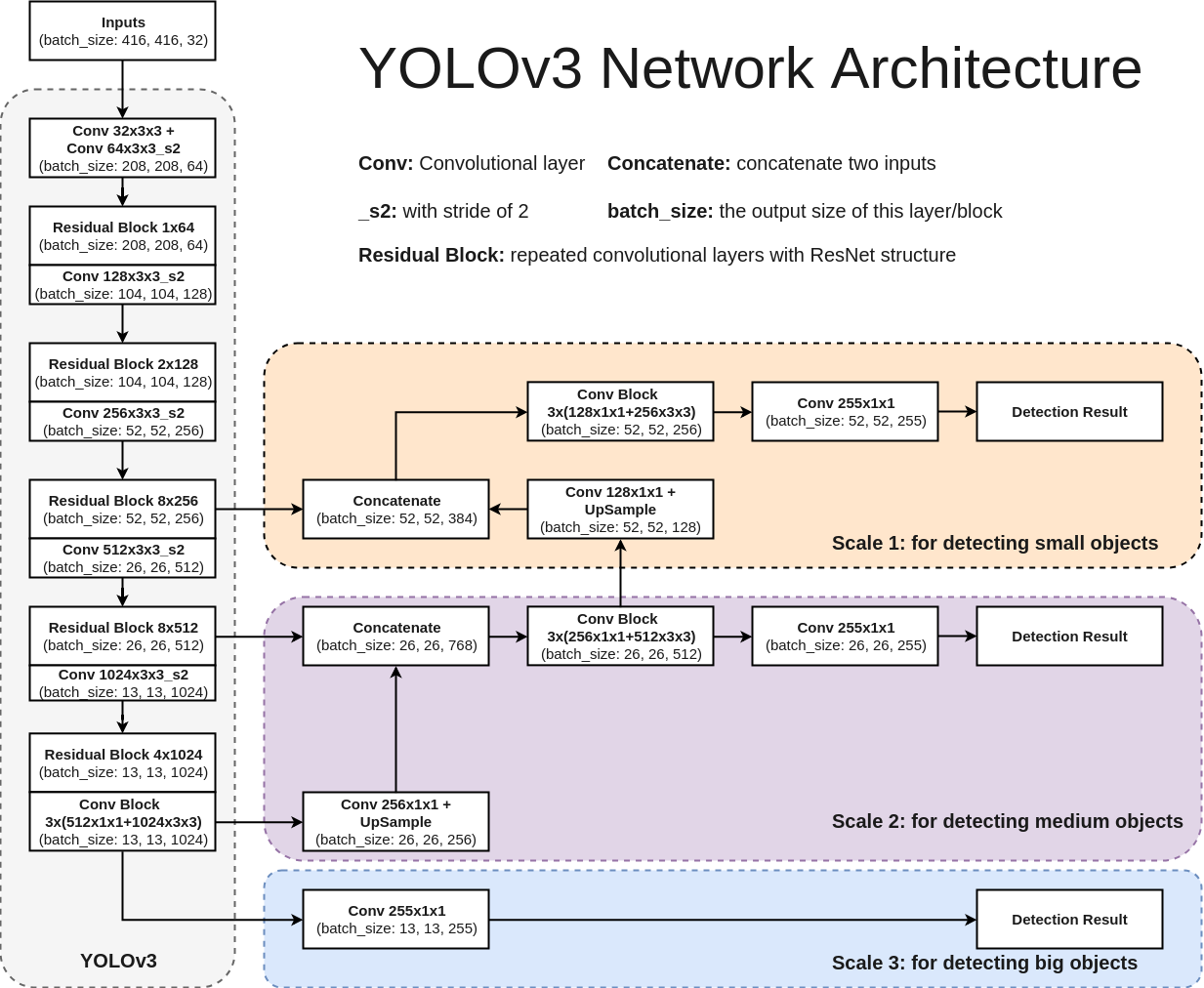
Backbone은 이미지로부터 Feature map을 추출하는 부분으로, CSP-Darknet를 사용합니다. YOLO v4의 백본과 유사합니다. YOLO v3의 Backbone은 Darknet53으로 CSP가 적용되지 않습니다. (3는 CSP를 포함하지 않는다. 4는 포함한다. 5는 종류가 4가지다.) - YOLO v5의 backbone은 종류가 4가지나 됩니다.
- 제일 작고 가벼운 yolo v5-s부터 m, l, x 까지 포함해서 총 4가지 버전이 있습니다
- Head는 추출된 Feature map을 바탕으로 물체의 위치를 찾는 부분입니다. 흔히 말하는 Anchor Box(Default Box)를 처음에 설정하고 이를 이용하여 최종적인 Bounding Box를 생성합니다.
- YOLO v3와 동일하게 3가지의 scale에서 바운딩 박스를 생성합니다.
(8 pixel 정보를 가진 작은 물체, 16 pixel 정보를 가진 중간 물체, 32 pixel 정보를 가진 큰 물체를 인식 가능) 또한 각 스케일에서 3개의 앵커 박스를 사용합니다. 그러므로 총 9개의 앵커 박스가 있습니다.
번외) YOLOv5 (2020)
- Darknet이 아닌 PyTorch 구현이기 때문에, 이전 버전들과 다르다고 할 수 있음
구조
-
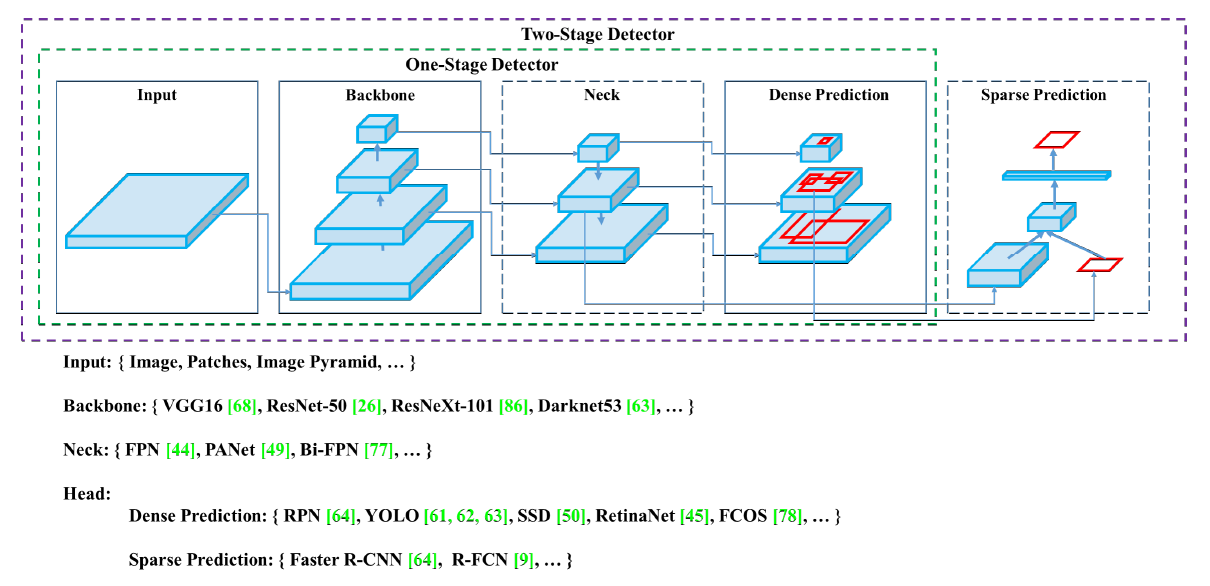
백본(Backbone)은 입력이미지를 feature map으로 변형(추출-CSP-Darknet)시켜주는 부분이다.
-
헤드(Head)는 Backbone에서 추출한 feature map의 location(물체 위치 찾음, 앵커박스 처음설정) 작업을 해주는 부분으로, predict classes 와 bounding boxes 작업이 수행된다. 헤드는 크게 Dense Prediction(밀집)과 Sparse Prediction(희소)으로 나누어진다.
-
넥(Neck) 은 Backbone 과 Head를 연결하는 부분으로, feature map을 정제하고 재구성한다.
-
Sparse Prediction(희소)을 사용하는 Two-Stage Detector: Predict Classes 와 Bounding Box Regression 분리 ex) R-CNN, R-FCN
-
Dense Prediction(밀집) 을 사용하는 One-Stage Detector: Predict Classes 와 Bounding Box Regression 통합 ex) ✔️YOLO, SSD -> 한번에 처리되어 속도 빨라짐.
절차
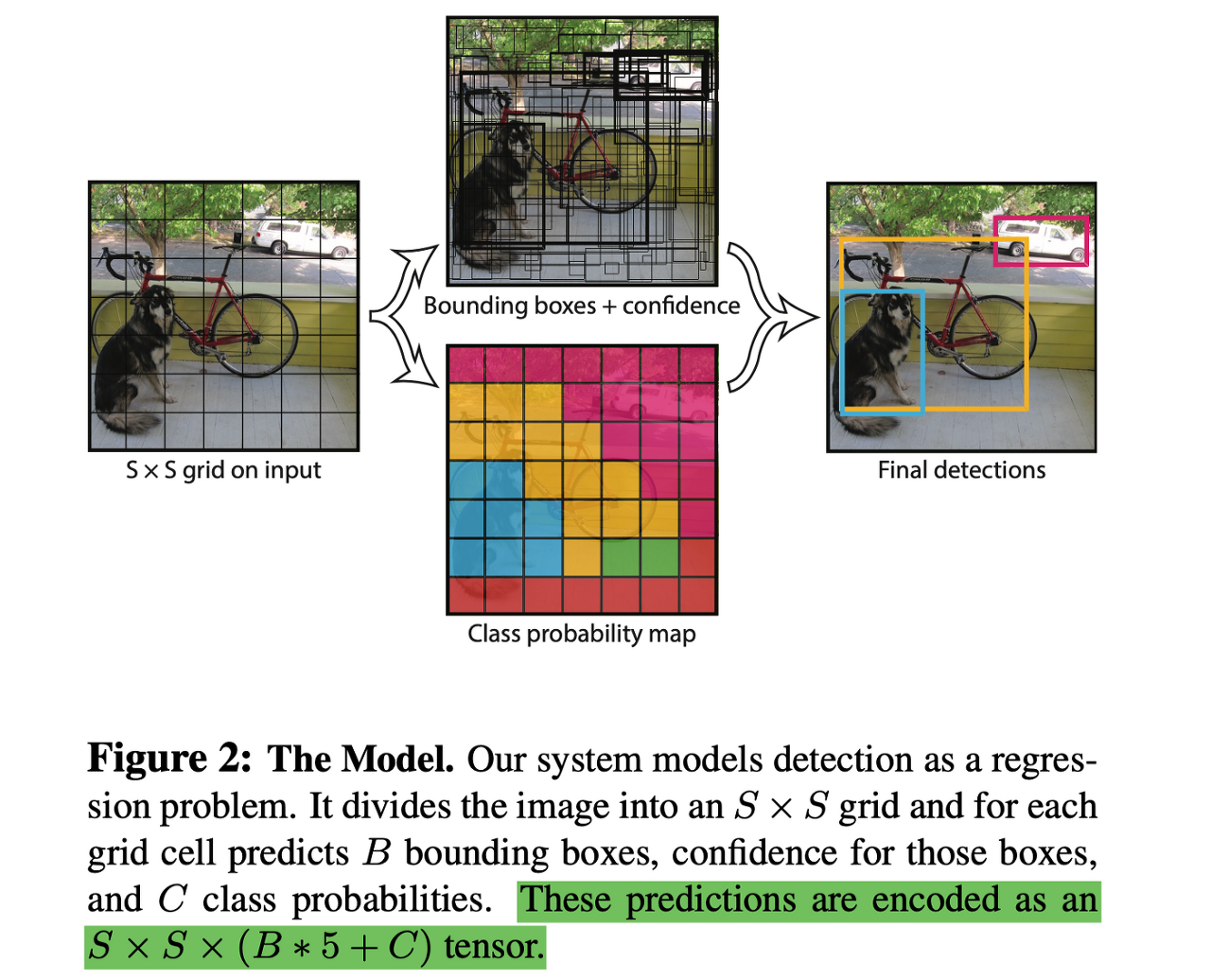
- 그리드로 분할된다.
- 확률적인 맵과 Anchor Box와 신뢰도로 나누어서 동시에 진핸된다.
- Anchor Box가 Bounding boxes들이 되면서 최종적 Detection, AP를 비교한다.
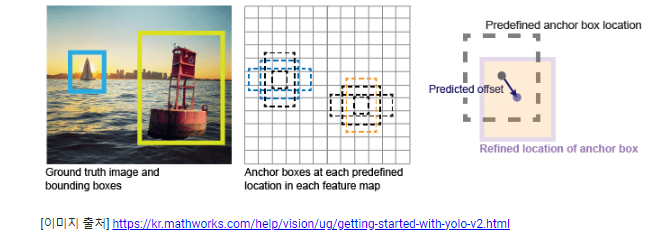
번외) 앵커 박스(Anchor Box)
- YOLOv2에서 도입
- 뜻은 사전 정의된 상자(prior box)
- 객체에 가장 근접한 앵커 박스를 맞추고 신경망을 사용해 앵커 박스의 크기를 조정하는 과정때문에 tx,ty,tw,th 이 필요