from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)우선 DNN-(1)에서 했던 전처리는 해 놓고 시작하자.
이제 이 모델에 층을 추가해서 더 좋은 모델을 만들어 볼 것이다.
입력층과 출력층 사이에 있는 층을 은닉층이라 부른다.
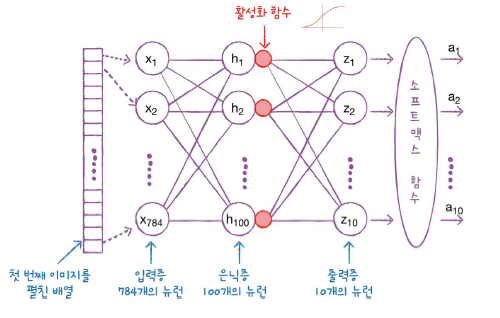
Q. 왜 활성화 함수를 은닉층에 추가하나요?
A. 은닉층에서 계속 선형적인 산술 계산만 하면 수행 역할이 없는 거나 마찬가지다. 선형 계산을 적당히 비선형적으로 비틀어 주어야 층을 쌓을 수 있다. 마치
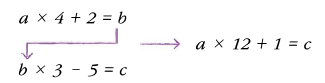
이렇게 되면 b는 그냥 사라지는 거나 마찬가지지만,
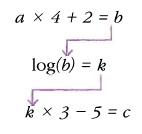
이렇게 하면 b가 역할을 할 수 있도록 해 주는 것처럼!
은닉층에 들어가는 활성화 함수는 비교적 자유롭다. 그러면 제일 만만한 sigmoid를 은닉층의 활성화 함수로 넣어 보자.
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')Q. 은닉층(dense1)의 노드 갯수는 왜 100개인가요?
A. 그냥그냥그냥. 출력층의 노드 갯수보다만 많으면 된다!
dense2는 출력 층이기 때문에 노드 갯수가 10이다.
그럼 이제 이 층들을 모델에 추가해 보자.
model = keras.Sequential([dense1, dense2])model.summary()이 코드를 치면, 모델에 대한 정보가 나온다.
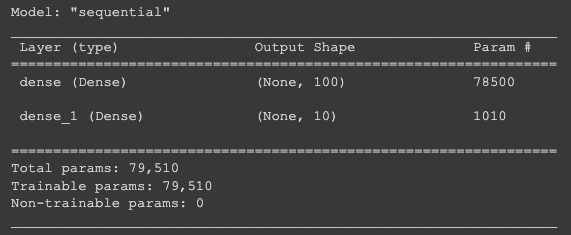
우왕! 내가 추가한 은닉층이 보인다!
첫 번째 Dense:
저 None은 샘플 갯수가 아직 정의되어 있지 않기 때문에 그렇다. 이건 fit()의 batch_size=에서 숫자를 넣어줄 수 있는데, 그러면 데이터를 한 번에 사용하지 않고 잘게 나누어 여러 번에 걸쳐 경사 하강법 단계를 수행한다. 즉, 미니배치 경사 하강법을 사용한다! 그러나 어떤 배치 크기에도 유연하게 대응할 수 있도록 None으로 둔다.
이렇게 신경망 층에 입력되거나 출력되는 배열의 첫 번째 차원을 배치 차원이라고 부른다.
배치 차원 : None
두 번째 100은 그냥 은닉층의 뉴런 개수를 100으로 뒀기 때문에 100개의 출력이 나온 것이다. 입력층에 있었던 784개의 특성이 100개로 압축되었다.
모델 파라미터 개수는 입력 픽셀 784X100개 조합에 대한 가중치 + 뉴런(출력층 노드)의 갯수이다.
즉, 784X100 + 100 = 78500
두 번째 Dense도 마찬가지다.
배치 차원은 None, 100개의 입력층, 10개의 출력층. 그러므로 파라미터 개수는
100X10 + 10 = 1010
층을 추가하는 다른 방법
앞에서는 dense 클래스의 객체를 만들어 Sequential에 전달을 했는데, 어차피 이 객체를 따로 쓸 일은 없기 때문에 보통 Sequential 클래스의 생성자 안에서 바로 Dense클래스의 객체를 만드는 경우가 많다.
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')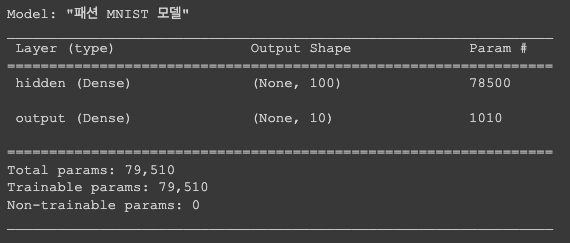
이번에는 이름까지 지정해 줬다.
그런데 층을 깊게 쌓으면 저런 코드는 좀 보기 어렵다. 그래서
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))요렇게 만들어 준다. 이것도 결과는 같다.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)다시 compile을 해 주고, 모델을 돌려 보자!
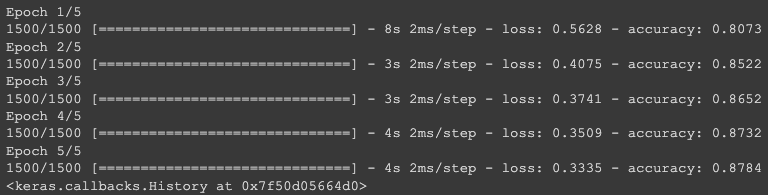
아까는 0.85 정도였는데, 층을 깊게 쌓으니 정확도가 올랐다!!
활성화 함수
렐루 함수
시그모이드 함수는 많이 쓰이지만, 사실 기울기 소실 문제를 겪게 된다.
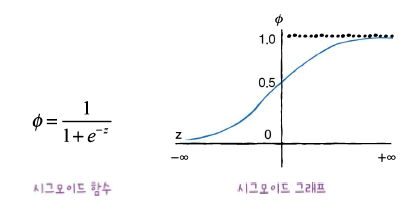
왜냐면 시그모이드는 갈수록 누워 있기 때문에, 기울기가 소실되고 층이 많은 신경망일수록 그 효과가 누적되어 학습이 더 어렵다. 그래서 나온 대안이
렐루 함수
인 것이다!
렐루는 입력이 양수일 경우 활성화 함수가 없는 것처럼 입력을 통과시키고 음수일 경우엔 0을 만들어버린다.
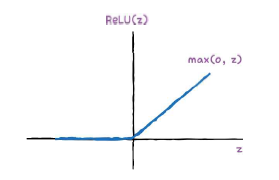
요롷게.
max(0,z) 이렇게 쓸 수 있는데, z가 0보다 크면 z, 아니면 0을 출력한다는 뜻이다.
렐루는 특히 이미지 처리에서 좋은 성능을 낸다고 한다.
이걸 적용해보기 전에,
DNN-(2)에서 reshape을 해서 배치 차원을 빼고 나머지 입력 차원을 전부 일렬로 펼쳤는데, 사실 keras에서는 flatten 클래스를 제공한다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))입력 차원에 이렇게 함수를 적용해 주면, 일렬로 펼쳐진다! 얘는 편의상 층이라고 하긴 하지만, 사실 층은 아니다. 아무 학습도 하지 않기 때문에. 이 flatten 층을 추가하면
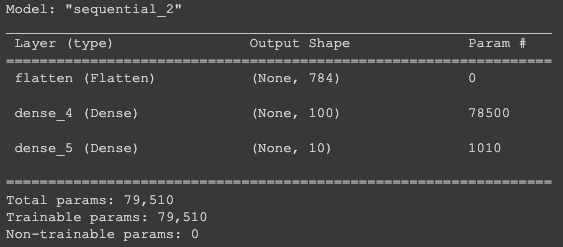
다음과 같이 입력층의 차원을 알 수 있어서 더 좋다.
그럼, 모델을 돌려 보자!
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)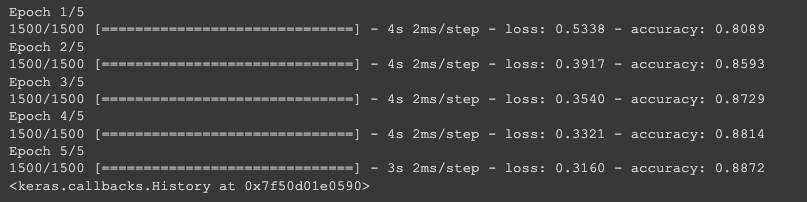
시그모이드를 사용했을 때보다 성능이 조금 더 좋아졌다. !!
model.evaluate(val_scaled, val_target)검증 세트에서도 0.871749997138977 의 정확도가 나온다.
옵티마이저
신경망의 하이퍼파라미터에는
추가할 은닉층의 개수, 은닉층의 뉴런 개수, 활성화함수, 층의 종류, 배치 사이즈 매개변수, 에포크
등이 있다.
그런데 여기에 이어서, compile()에 들어가는 경사 하강법 알고리즘에도 종류가 있다. 이걸 옵티마이저라고 부른다.
말하자면 어떻게 global minima, 즉 최소점(오차가 가장 적은 지점)을 찾을 것이냐 하는 문제다.
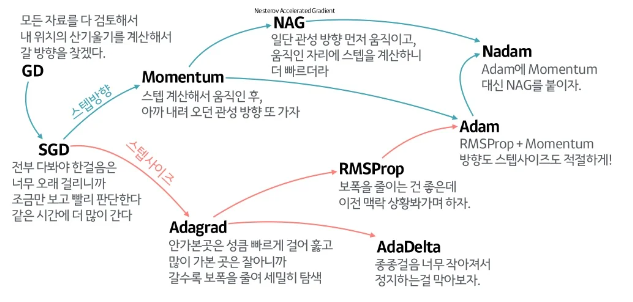
옵티마이저의 종류에는 여러가지가 있는데, 케라스는 RMSProp이 디폴트다. 그러나 sgd를 한 번 적용해 보자.
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')원래 loss, metrics변수만 있던 compile에 옵티마이저 변수를 추가해 준 것이다. 이 코드는
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')이것과 완벽하게 동일하다.
단 밑의 코드에서는 SGD()안에서 learning_rate로 학습률(얼마나 큰 보폭으로 찾는가)를 조정해줄 수 있다.
sgd = keras.optimizers.SGD(learning_rate=0.1)이런 식으로.
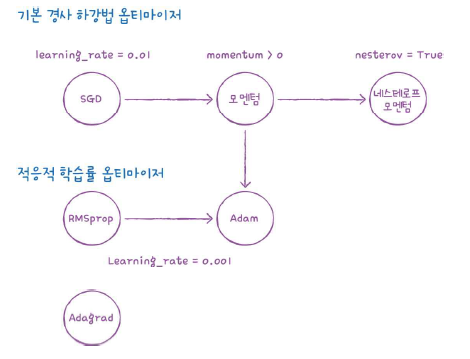
기본 경사 하강법 옵티마이저는 SGD 클래스에서 제공한다.
모멘텀 매개변수의 기본값은 0인데, 이를 0보다 큰 값으로 지정하면 이전의 그레디언트를 가속도처럼 사용하는 모멘텀 최적화를 사용하게 된다. 보통 0.9 이상으로 지정한다.
그리고 SGD 클래스의 nesterov를 True로 바꿔주면, 네스테로프 모멘텀 최적화(=네스테로프 가속 경사)를 사용하게 되는데, 이건 모멘텀 최적화를 2번 반복해서 구현하는 것이다.
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)모델이 최적점에 가까이 갈수록 학습률을 낮출 수 있다(더 세세하게 지점을 찾을 수 있다). 이런 학습률을 적응적 학습률 이라고 하는데, 이런 방식은 학습률 매개변수 튜닝 수고를 덜어준다.
바로 이런 효자 옵티마이저들이 Adagrad와 RMSProp이다.
adagrad = keras.optimizers.Adagrad()
model.compile(optimizer=adagrad, loss='sparse_categorical_crossentropy', metrics='accuracy')rmsprop = keras.optimizers.RMSprop()
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy', metrics='accuracy')보통 Adam을 쓰면 좋다.
그럼, 다시 학습을 시켜 보자!!!
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(val_scaled, val_target)검증 세트는 0.8730000257492065 정도로 미세하게 RMSProp보다 낫긴 하다.
출처 : 혼자 공부하는 머신러닝 딥러닝 책
+)
https://www.slideshare.net/yongho/ss-79607172?from_action=save
