
🌱 환경준비
✏️ 라이브러리 로딩
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import * # 검증 라이브러리 전부 불러오기
from sklearn.preprocessing import StandardScaler, MinMaxScaler # 표준화, 정규화 불러오기
import tensorflow as tf #텐서플로우 불러오기
from keras.models import Sequential # 모델 불러오기
from keras.layers import Dense # 레이어 불러오기
from keras.backend import clear_session # 초기화 불러오기
from tensorflow.keras.optimizers import Adam # compile 방법 불러오기✏️ 그래프 함수
def dl_history_plot(history):
plt.figure(figsize=(10,6))
plt.plot(history['loss'], label='train_err')
plt.plot(history['val_loss'], label='val_err')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.grid()
plt.show()함수 dl_history_plot(history) 선언으로 재사용 가능
✏️ 데이터 로딩
path = "https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic.3.csv" # 데이터 링크
data = pd.read_csv(path) # 파일 읽어오기
data.drop(['Age_scale1', 'AgeGroup', 'SibSp','Parch' ], axis = 1, inplace = True) # 특정 열 지우기
data.head()| index | Survived | Pclass | Sex | Age | Fare | Embarked | Family |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 7.25 | S | 2 |
| 1 | 1 | 1 | female | 38.0 | 71.2833 | C | 2 |
| 2 | 1 | 3 | female | 26.0 | 7.925 | S | 1 |
| 3 | 1 | 1 | female | 35.0 | 53.1 | S | 2 |
| 4 | 0 | 3 | male | 35.0 | 8.05 | S | 1 |
Age_scale1', 'AgeGroup', 'SibSp','Parch' 열이 삭제된 데이터프레임을 확인할 수 있다.
🌱 데이터 준비
✏️ 데이터 분할: x, y 나누기
target = 'Survived' # 계산하고자하는 데이터 변수 선언
features = ['Sex', 'Age', 'Fare'] # 독립변수 리스트 선언
x = data.loc[:, features] # 독립변수만 담은 x
y = data.loc[:, target] # 종속변수(target)만 담은 y독립변수와 종속변수 분리
✏️ 가변수화
x = pd.get_dummies(x, columns = ['Sex'], drop_first = True)
x.head()pandas.get_dummies(가변수화할 데이터 이름, columns= , drop_firsrt=) 함수 사용으로 특정 열 가변수화 적용
x.head() 로 확인
| index | Age | Fare | Sex_male |
|---|---|---|---|
| 0 | 22.0 | 7.25 | 1 |
| 1 | 38.0 | 71.2833 | 0 |
| 2 | 26.0 | 7.925 | 0 |
| 3 | 35.0 | 53.1 | 0 |
| 4 | 35.0 | 8.05 | 1 |
📌 가변수화는 학습을 위해 문자 데이터를 숫자형으로 변환하는 것.
때문에 학습에 사용할 x 데이터를 가변수화해야 함.
✏️ 데이터 분할2-학습 데이터와 검증 데이터
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.3, random_state = 2022)train_test_split() 함수로 학습 데이터와 검증 데이터를 분리함.
이때 random_state=2022 경우, 같은 결과를 확인하기 위함으로 실제 데이터 분석 시에는 사용빈도가 낮음.
✏️ Scaling
scaler = MinMaxScaler() # MinMaxScaler() 함수 변수 선언
x_train = scaler.fit_transform(x_train)
x_val = scaler.transform(x_val)📌 scaler.fit_transform(x_train) 학습 데이터 x인 경우 범위를 맞춰주기 위해 정규화 함수 MinMaxScaler() 함수를 사용.
단 학습 데이터에 scaling이 필요한 것.
x_train 에만 fit_transform() 으로 scaling 적용 및 학습.
x_val 검증 데이터의 경우 적용만 함.
🌱 Logistic Regression vs DL
✏️ Logistic Regression
from sklearn.linear_model import LogisticRegression # Logistic Regression 모델 불러오기
model1 = LogisticRegression() # 모델 선언
model1.fit(x_train, y_train) # 모델 학습
print(list(x)) # 독립변수 확인
model1.coef_, model1.intercept_ # 각 독립변수 가중치(회귀계수)와 절편(intercept) 확인 ['Age', 'Fare', 'Sex_male'] (array([[-0.77410527, 2.37435574, -2.2852748 ]]), array([1.07844411]))
pred1 = model1.predict(x_val)x_val 검정 데이터 model1로 예측
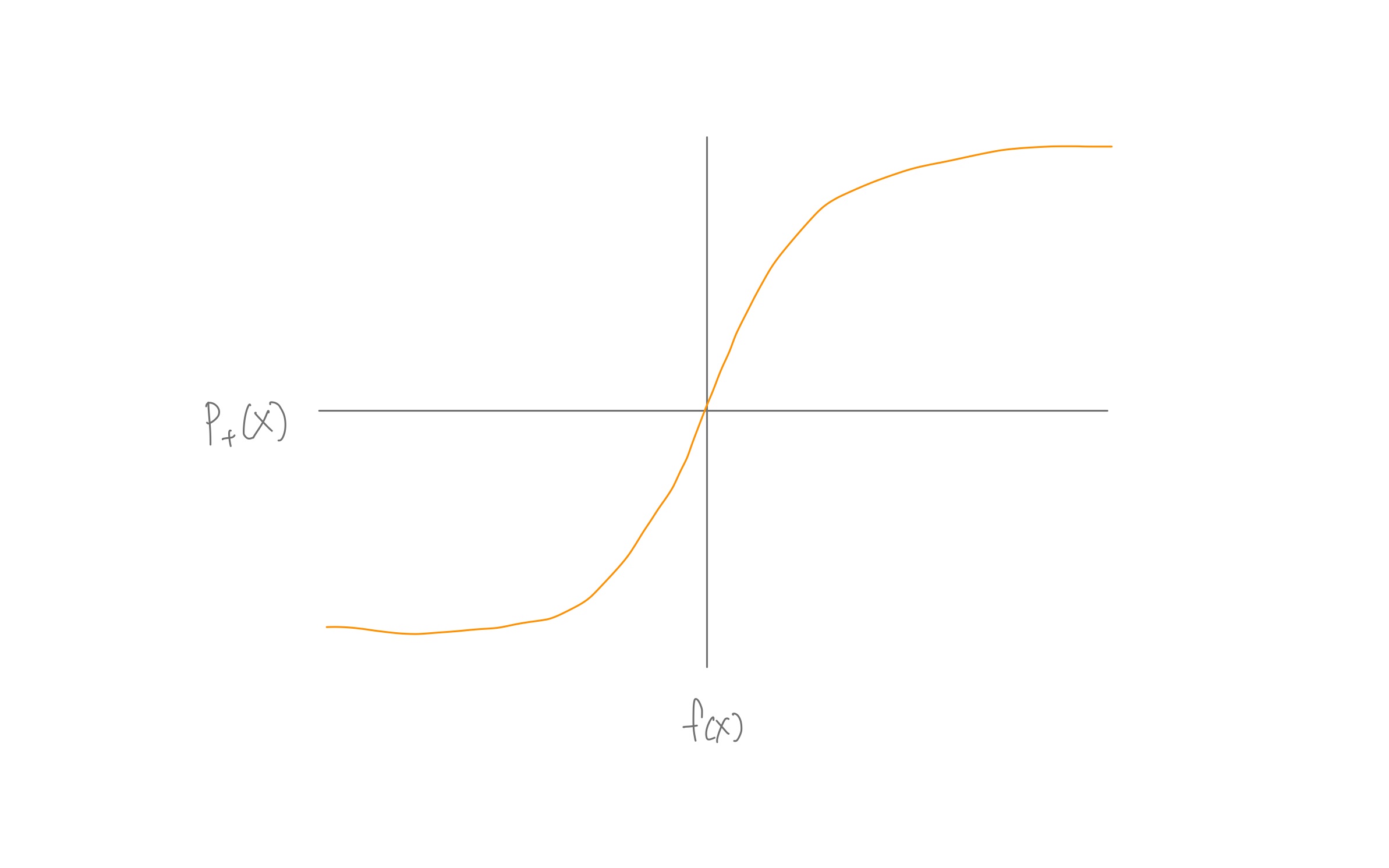
Rogistic Regression
Input 값(Age, Fare, Sex)에 가중치가 부여되어 결과 계산
➪ 결과는 0과 1로 분류
✏️ Deep Learning
모델 설계
nfeatures = x_train.shape[1] #num of columns
nfeatures3
nfeatures 변수 선언으로 x_train 열 값을 담음.
# 메모리 정리
clear_session()
# Sequential 타입 모델 선언
model = Sequential([Dense(1, input_shape = (nfeatures,), activation= 'sigmoid')])
# 모델요약
model.summary()
📌 clear_session() 으로 메모리 정리를 안해주면 학습 결과가 부정확해짐.
이후 코드를 수정하거나 변경사항이 있어 다시 실행할 경우, clear_session() 부터 다시 실행해주어야 함
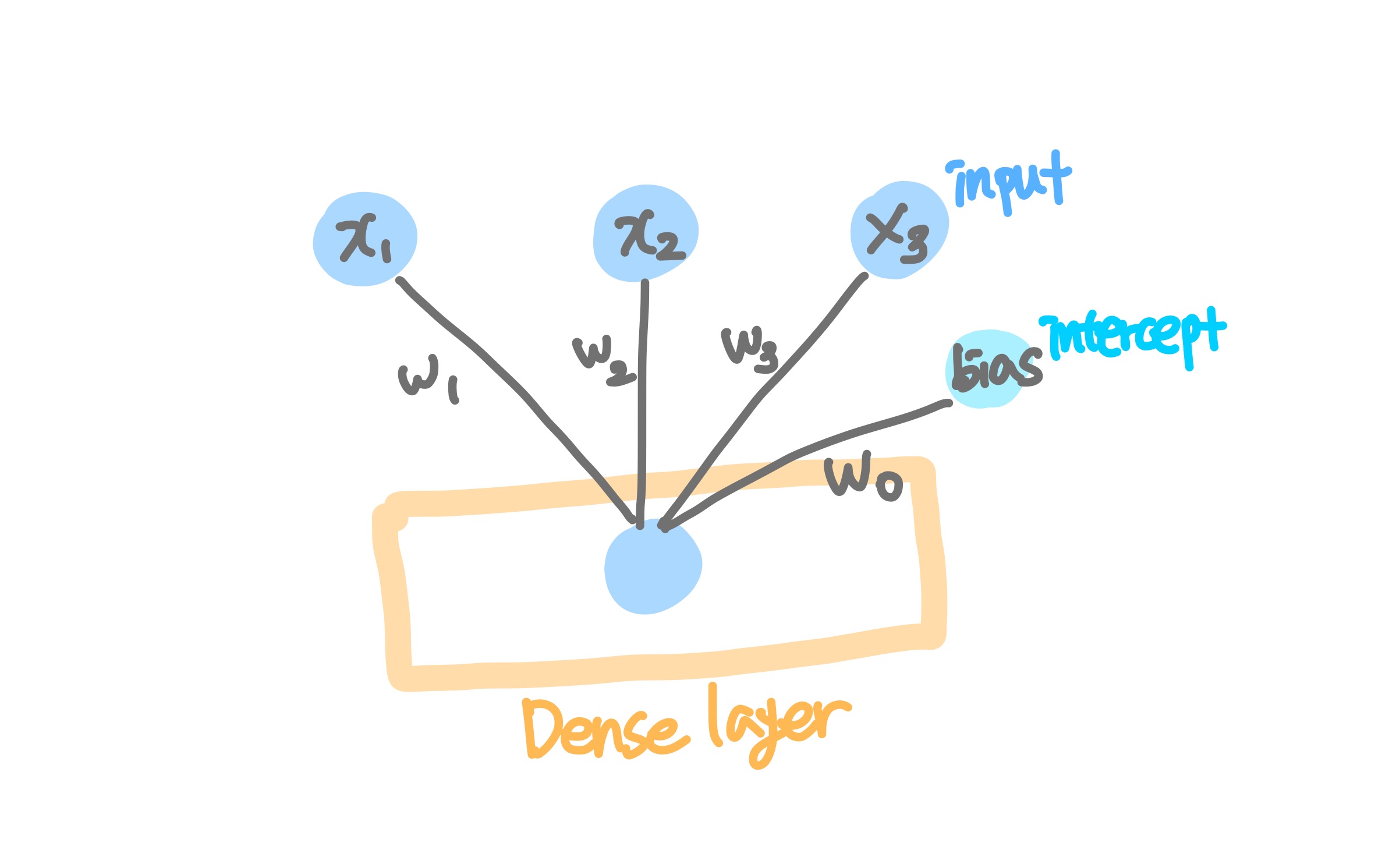
Sequential() 타입 모델을 선언하고 리스트에 layer 작성.
1개 layer로 Output layer.
Dense(노드 개수, input_shape = (독립변수 개수,), activation='sigmoid')
compile + 학습
model.compile(optimizer=Adam(lr=0.01), loss='binary_crossentropy')
history = model.fit(x_train, y_train,
epochs = 60,
validation_split=0.2).historycompile
모델 compile() 하는데 Adam 함수로 하고,
lr(learning_rate)=0.01 ➪ 학습 단위 0.01로 함.
loss='binary_crossentropy' ➪ 오차는 binary_crossentropy로 계산.
📌 분류 클래스가 2개일 경우 loss는 binary_crossentropy 사용
학습
history 변수 선언으로 학습내용 기록 담기
model.fit() 학습해라 x_train, y_train 으로
epochs 는 학습 반복 횟수 ➪ 60번 공부해
validation_split 비교 데이터 0.2 만큼.
.history 기록 나타내기
Deep Learning
activationloss function
2-Class 경우binary_croessentropy
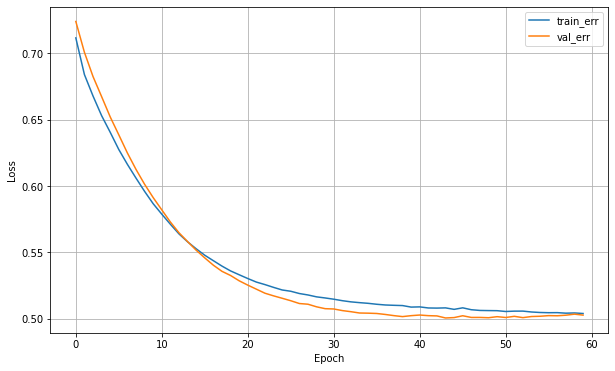
✏️ 학습 결과
그래프
예측
pred = model.predict(x_val)
pred 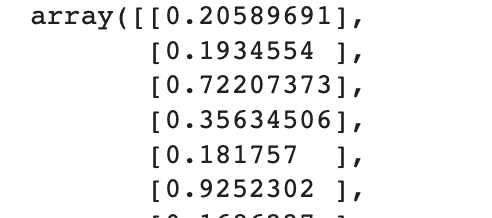
예측 결과를 보면 0과 1 사이 확률값으로 나타남.
activation = 'sigmoid' 로 주었기 때문에 결과가 0과 1 사이 확률값으로 나오는 것.
pred = np.where(pred >= .5, 1, 0)cut off value
데이터를 0.5 기준으로 0과 1로 만든다.
np.where(pred >= 0.5, 1, 0)
➪ pred 값이 0.5 보다 크면 1로, 그렇지 않으면 0으로 해.
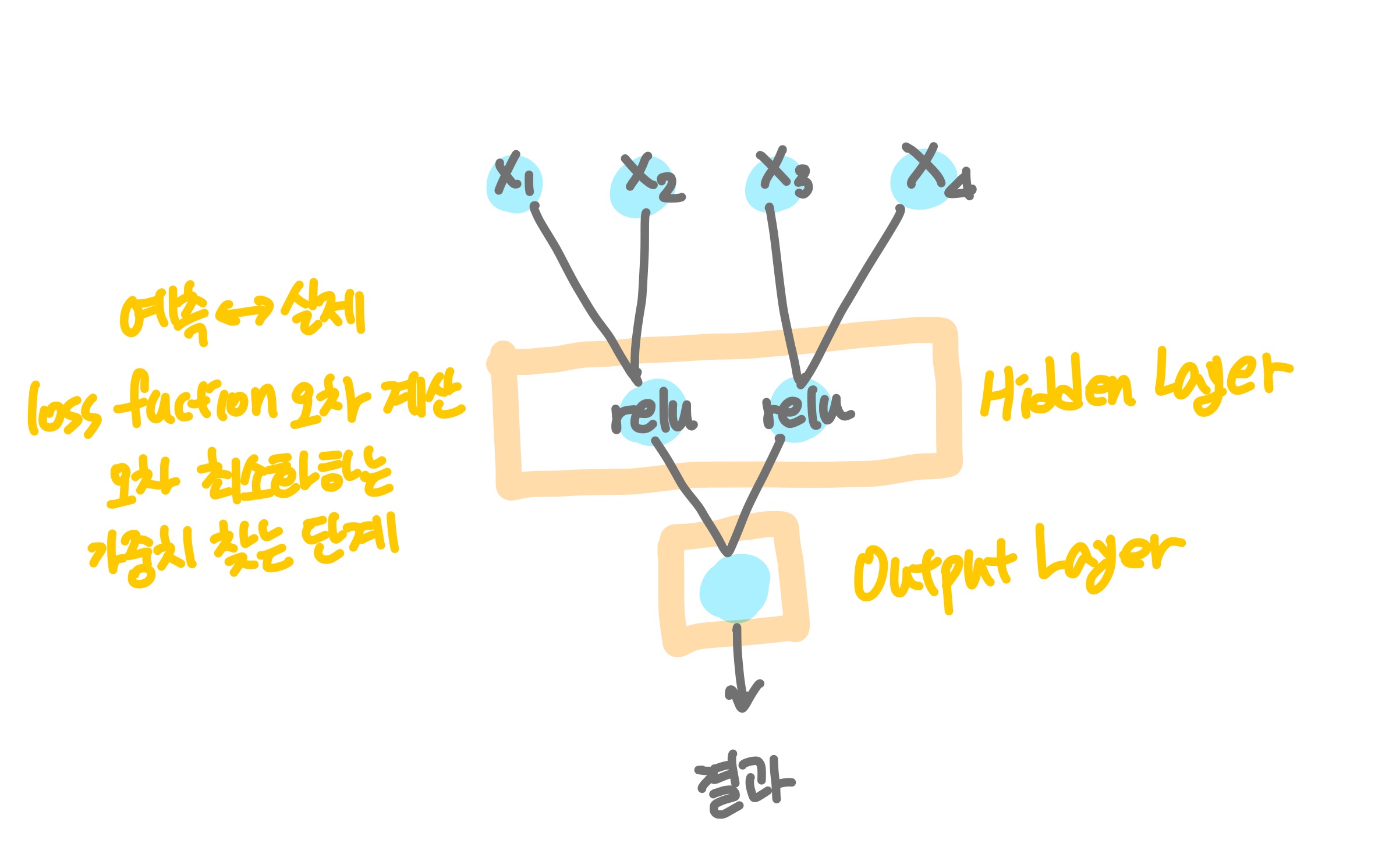
✏️ Hidden Layer
# 메모리 정리
clear_session()
# Sequential 타입 모델 선언
model = Sequential([Dense(16, input_shape=(nfeatures,), activation='relu'),
Dense(1, activation='sigmoid')])
# 모델요약
model.summary()[Dense(16, input_shape=(nfeatures,), activation='relu')
이렇게 Output layer 전에 Hidden Layer를 추가할 수 있음.
이를 통해 모델 성능을 향상시킬 수도 있음.
📌 Hidden Layer를 추가한다고 해서 반드시 모델 성능이 향상되는 것은 아님.
Hidden Layer
예측값과 실제 값을 비교하여 오차를 최소하하는 가중치는 찾음.
이때 오차 계산 방법은loss=''작성한 함수를 사용함.
Hidden Layer 에서 activation 함수는 보통relu가 많이 사용됨.
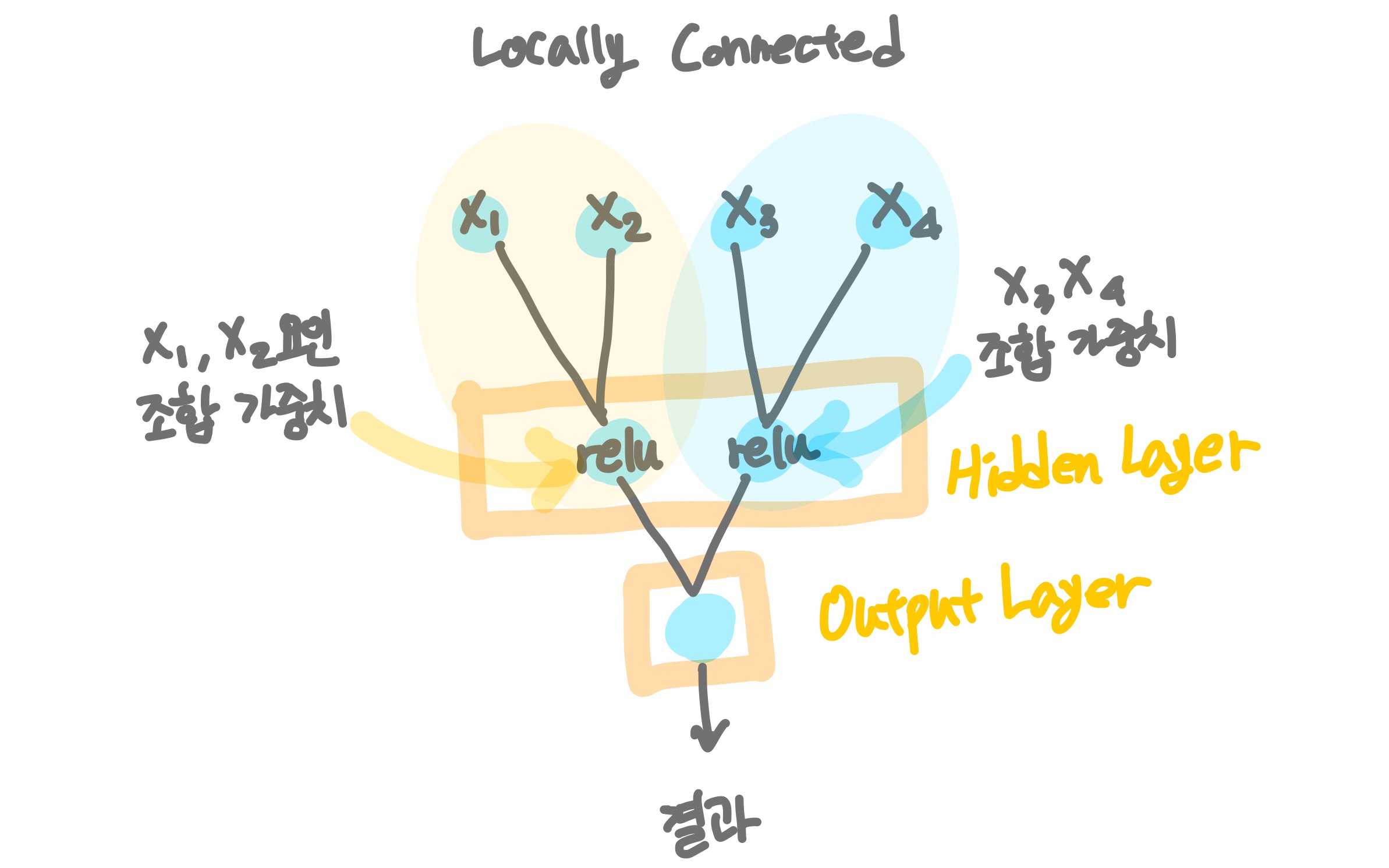
Input 데이터 전체를 연결할 수도 있고, 부분 데이터를 연결할 수도 있음.
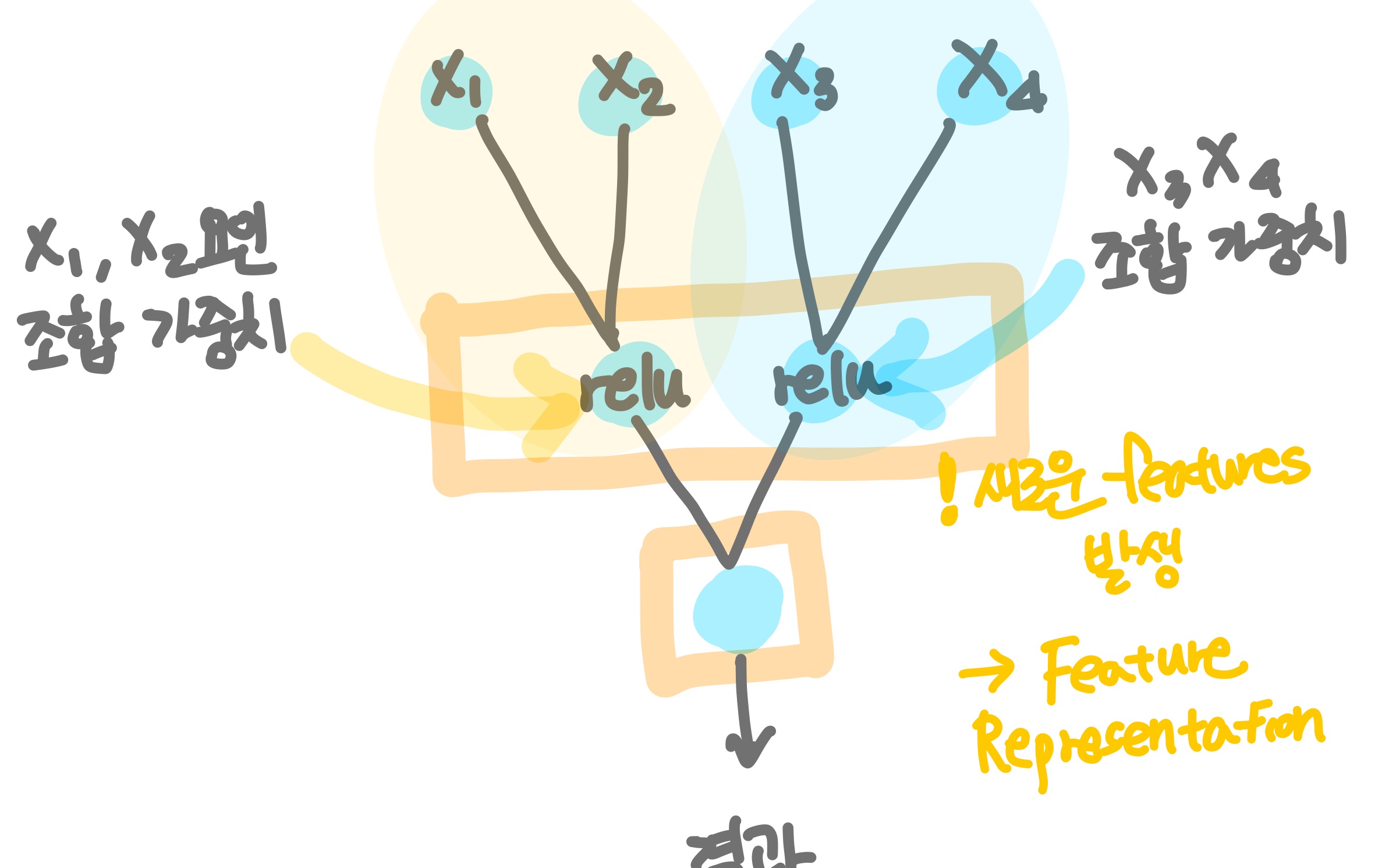
부분 Input을 연결할 경우 각 조합 데이터들의 새로운 가중치가 발생됨. (x1, x2로 이루어진 팀의 기여도(?) vs x3, x4로 이루어진 팀의 기여도)
개개인의 기여도(x1, x2, x3, x4) 뿐만 아니라 팀 조합 기여도가 계산될 수 있음
이를 Feature Representation 라고 함.
새로운 features가 발생되는 것을 말함.
이를 통해 오차를 줄여 성능을 향상시킬 수도 있음.
💐 느낌점
확실히 정리하면서 조금 더 흐름과 개념이 잘 잡히는 기분이다.
마크다운 문법을 몰라 식 표현이 쉽지 않았는데 찾아서 기록하다보니 추가로 배우는 느낌이다. 그냥 코드를 따라 결과를 확인했을 때 무의식적으로 기록하던 코드들의 의미를 제대로 이해할 수 있었다.
처음엔 단편적으로 activation 에는 relu, sigmoid 함수를 쓴다는 정도만 이해를 했으나 Hidden Layer에서 가중치 도출을 위해 사용되는 함수 라고 역할을 이해할 수 있었다.
또한 Optimizer Adam 경우 모델이 머신러닝하는 방법 역할을 복습할 수 있었다.
그림을 그려서 정리하니 머리 속으로 정리가 잘되는 기분이다.
아직 함수 식은 어렵지만 차근차근 이해해봐야겠다.
