설문조사에서 각 질문별 응답 비율을 확인하기 위해 반복문으로 질문마다 만족도 항목의 합계를 데이터프레임으로 병합함
- 매우 그렇다 - 1
- 그렇다 - 2
- 약간 그렇다 - 3
- 보통이다 - 4
- 약간 아니다 - 5
- 아니다 - 6
- 전혀 아니다 - 7
각 컬럼이 설문조사의 질문명이며, 만족도 조사와 관련된 컬럼의 순서는 [15:42] 컬럼에 해당
설문조사 데이터프레임에서 만족도에 대한 응답 (1부터 7사이의 수)를 index로, 질문명을 컬럼명으로 하여 concat을 적용하였다.
사전작업 및 확인
display(qa,qb,pd.concat([qa,qb],axis = 1).sort_index()) 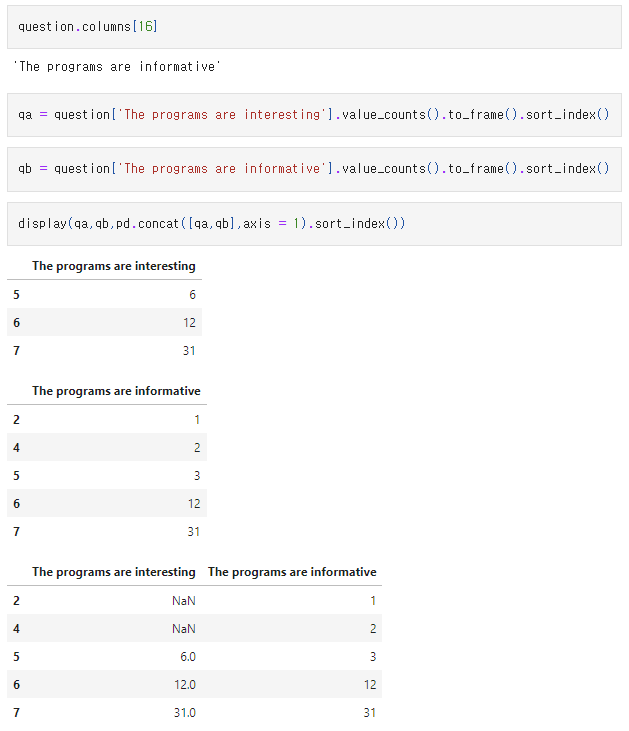
만족도 조사 항목 질문명을 리스트로 저장
col_nm = [question.columns[i] for i in range(15,42)]DataFrame concat
list comprehension을 통해 컬럼명 리스트 내에 해당하는 질문들의 만족도 응답 항목들을 데이터 프레임 생성 및 병합
merged_df = pd.concat([question[nm].value_counts().to_frame().sort_index() for nm in col_nm],axis = 1).sort_index()
merged_df.shape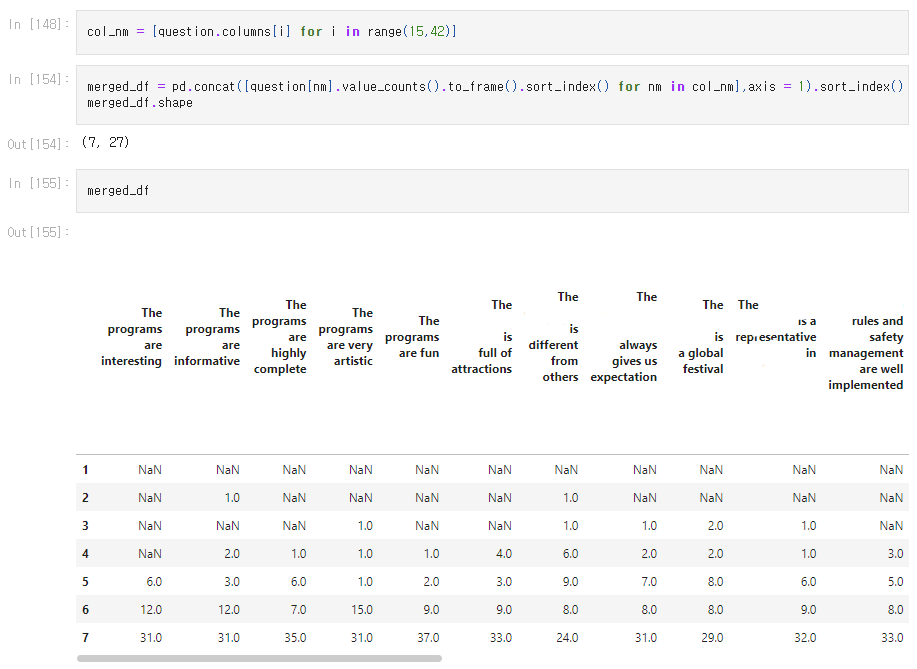
fillna().astype()
null값을 채우고 소수점 제거를 위해 int형 변환
merged_df.fillna(0).astype(int)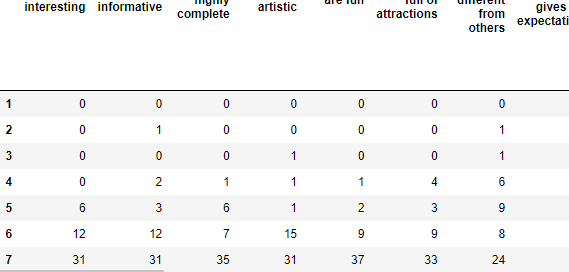
seaborn countplot
seaborn 의 countplot을 이용해 질문별 항목 count 시각화
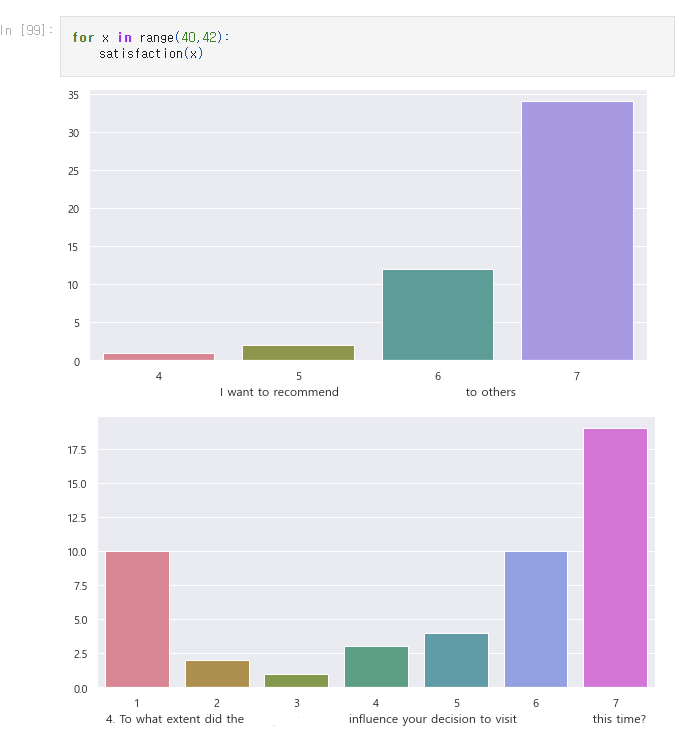
def satisfaction(x):
col_nm = question.columns[x]
plt.figure(figsize=(10,5))
sns.countplot(data = question, x= col_nm,palette='husl')
plt.ylabel('')
plt.show()
# 40 ~ 41번 문항에 대한 countplot
for x in range(40,42):
satisfaction(x)