PyTorch에서 레이어별로 GPU 연산시간 측정하는 방법입니다.
본 글은 Torch Profiler를 사용하지 않고, time 모듈과 register_forward_pre_hook, register_forward_hook 함수를 사용합니다.
코드
import torch
import time
# 전역변수를 초기화 합니다.
star_time = None
execution_time = []
model = YourModel # 사용할 Torch 모델을 정의하세요.
def StartTime(self, input):
"""시간 측정을 시작하는 함수입니다"""
global start_time
torch.cuda.synchronize()
start_time = time.time()
def StoreTime(self, input, output):
"""시간을 측정하는 함수입니다"""
global start_time, exec_time
torch.cuda.synchronize()
exec_time.append(time.time()-start_time)
for module in model.modules():
"""
모델의 모든 레이어마다 pre_hook, hook을 걸어줍니다.
register_forward_pre_hook에 의해서 각 레이어의
forward가 호출되기 전에 StartTime 함수가 먼저 호출됩니다.
각 레이어의 forward 함수가 끝날 때 마다 StoreTime 함수가
호출됩니다.
"""
module.register_forward_pre_hook(StartTime)
module.register_forward_hook(StoreTime)
output = model(input)
for module, t in zip(model.modules(), exec_time):
print(module," : ", t) #각 레이어별 측정된 시간을 출력합니다.
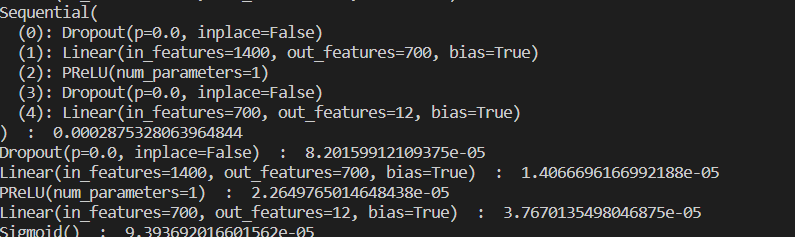
이러한 코드를 실행했을 때 아래와 같은 결과 화면을 볼 수 있습니다.
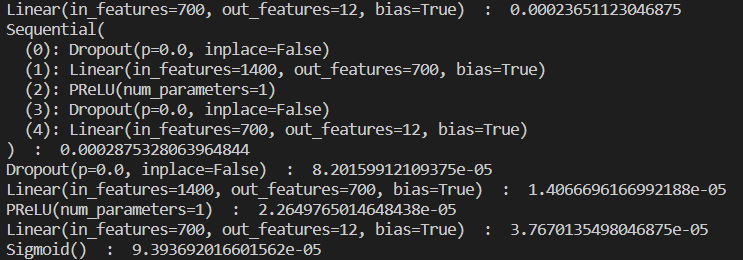
주의할 점은 이 방식의 시간측정에도 Torch Profiler 만큼은 아니지만 프로파일링 오버헤드가 포함됩니다. 따라서 소숫점 이하의 정밀한 프로파일링 결과를 요구하는 task에는 더 정확한 측정 방식이 요구됩니다.

A.I. Developer / Engineer / Researcher