DATA | MODEL | LOSS | Optimization
Loss
- Regression Task: MSE (Mean Squared Error)
- Classification Task: CE (Cross Entropy)
- Probabilistic Task: MLE (Maximum Likelihood Estimation)
Activation Functions
뭐가 가장 좋을지는 모름
- ReLU
- Sigmoid
- ...
Optimization
Generalization
how well the learned model will behave on unseen data
Generalization gap = Training error - test error
Under-/over-fitting
Cross-validation
k-fold validation
Bias and Variance
Bagging vs. Boosting
Bagging (Bootstrapping aggregating)
- crassifiers를 random subset에 각각 학습시킨 후 aggregating한다: 앙상블 Boosting
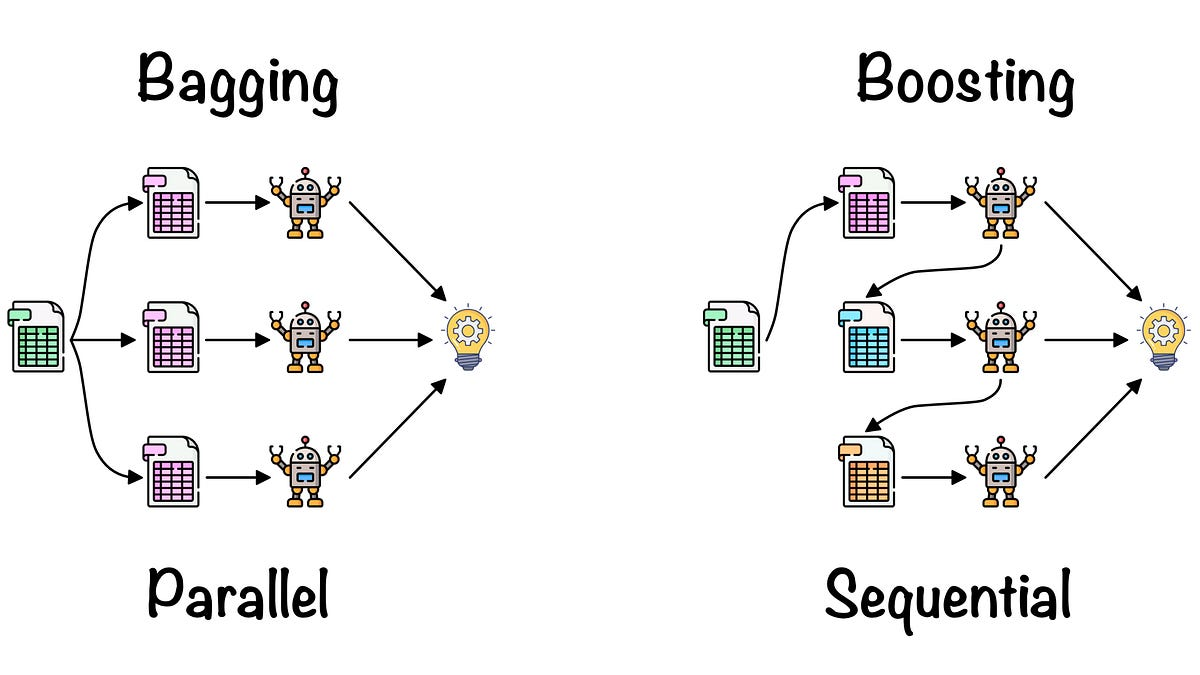
Source: https://towardsdatascience.com/ensemble-learning-bagging-boosting-3098079e5422
Gradient Descent Methods
- stochastic gradient descent
- mini-batch gradient descent
- batch gradient descent
배치사이즈는 작은 것이 더 좋다
큰거: Flat minimum -> good generalization
작은거: Sharp minimum
Stochastic gradient descent
좋은데 lr 설정 어려움
Momentum
관성을 주자: 이전 step에서 업데이트 방향을 고려
Nesterov Accelerate
다음 step의 업데이트 방향을 고려
Adagrad
Adadelta
lr이 없음. 많이 활용되지 않음.
RMSprop
Adam
Adaptive Moment Estimation (Adam) leverages both past gradients and squared gradients
Regularization
학습을 방해해서 text dataset에 잘 되도록 하는 것들
Early stopping
Parameter norm penalty
It adds smoothness to the function space.
부드러운 함수로 만들면 잘된다..?
Data augmentation
데이터셋이 적을 때에는 traditional ML이 더 잘품.
데이터셋을 늘리기 위해 데이터를 조작(이미지를 예를들면 회전시키기)해서 데이터셋을 늘리는 것.
Noise robustness
데이터에 노이즈 집어넣는것. 근데 왜 도움이 되는지 증명 안됐고, 실험적으로만 증명됨.
Label smoothing
두 라벨을 섞음... 고양이 개가 섞인(Mixup, Cutout, CutMix) 사진. 성능이 많이 놀라간다고 함.
Dropout
뉴런의 일부 웨이트를 0으로 switch하는...
Batch normalization
internal covariance shift. 뉴럴 네트워크내 레이어가....
각각의 레이어를 독립적으로 mean and variance를 계산해서 정규화한다...
파라미터 값을 특정값으로 정규화 하는 것으로 보임.
실험적으로 성능이 올라감.
이 개념을 해석하기 보다는 실험적으로 증명되어 잘 사용됨.
