캐글 컴페티션에 참가해보기 전에 연습으로 titanic 데이터 셋을 이용하여 생존자를 분류하는 컴패티션에 조인했다!!
최근 결정트리 기반 모델들을 다시 공부하고 있던터라
트리 기반 모델을 사용해서!!!! 상위 10%내에 들겠다!!!!라는 목표로 시작했다.
(피피티로 정리해서 올려뒀는데....여기에 올릴진 모르겠다,,)
!!!!
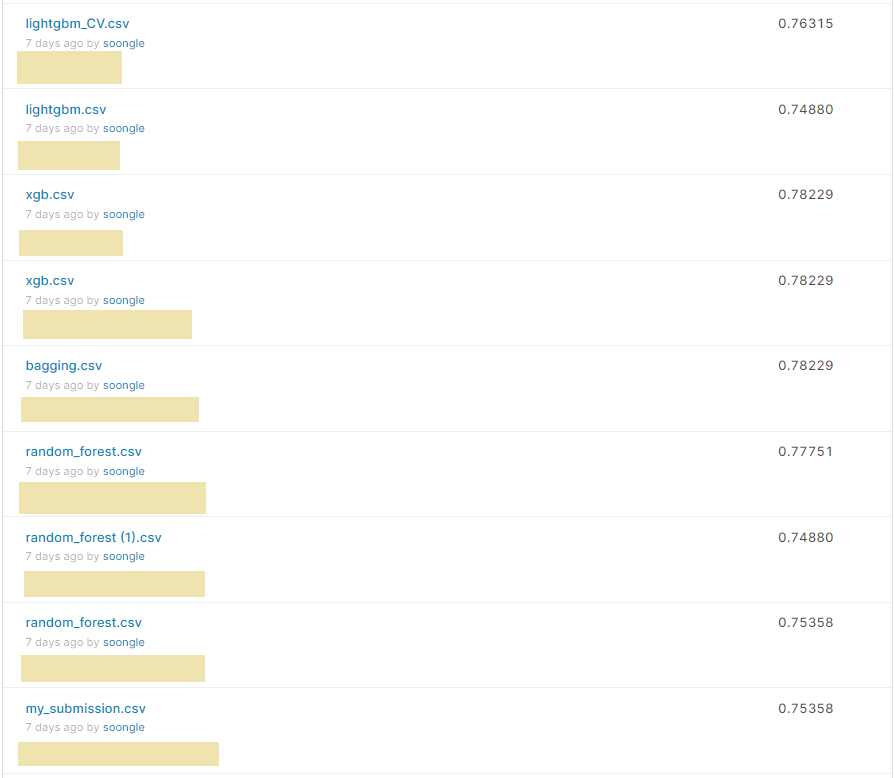
괜찮은데?₍ᐢɞ̴̶̷.̮ɞ̴̶̷ᐢ₎
여러 모델들을 사용해보는게 목적이라 기대는 안했는데
꽤 높은 점수가 나왔다 ~!
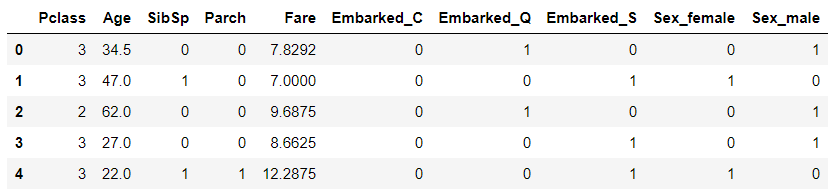
속성도 간단간단
트리 기반 모델만 사용해서 스케일링도 안하고 훈련했다.
Age 예측 후, 트레인!
트레인 셋 Age 컬럼에 결측치가 177개나 있어서
전체 평균으로 채우기도하고
이름을 이용하여 Mrs, Ms등으로 카테고리화 한 후, 카테고리 별 평균으로도 채워보았으나 성능이 만족할 만큼 오르지 않은게 아쉬웠다.
그래서 Survived, Age를 제외하고 Age를 예측하는 모델을 학습시켜, 결측값을 채운 후, 다시 트레인해보기로 하였다!
def processing(df):
df=pd.get_dummies(df, columns = ['Sex'])
df['Title'] = df.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
df['Title'] = df['Title'].replace(['Lady', 'Countess','Capt', 'Col',
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
df['Title'] = df['Title'].replace('Mlle', 'Miss')
df['Title'] = df['Title'].replace('Ms', 'Miss')
df['Title'] = df['Title'].replace('Mme', 'Mrs')
df = df.drop(['Cabin', 'Ticket', 'Name', 'Embarked', 'PassengerId'], axis = 1)
df.Fare = df.Fare.fillna(df.Fare.mean())
if 'Survived' in df.columns:
df = df.drop(['Survived'], axis = 1)
df=pd.get_dummies(df, columns = ['Title'])
df['FamilySize'] = df['SibSp'] + df['Parch'] + 1
df['IsAlone'] = 0
df.loc[df['FamilySize'] == 1, 'IsAlone'] = 1
df = df.drop(['FamilySize', 'SibSp'], axis = 1)
return df나중엔 데이터 프로세싱을 그냥 메소드로 만들어버렸다.
-
Embarked는 Age와 연관없는 속성같아서 드롭
(실제로 포함해서 트레인 했을 때 특성 중요도가 낮았다.) -
Name은 필요한 부분만 추출해서 카테고리화
-
Cabin은 사용하기 까다로워서 드롭!(숫자로 호실을 분석해서 사용하는 코드도 있었다ㅇ0ㅇ..)
-
Ticket도 Cabin과 같은 이유로 드롭
-
Fare는 결측치가 하나라 mean으로 채웠다
-
SibSp와 Parch를 이용해서 FamilySize 속성을 만들었다!
그리고 FamilySize를 이용하여 isAlone속성을 만들었다.
###랜덤 포레스트 기준
#FamilySize 제거 전
#훈련 세트 정확도 : 0.596
#테스트 세트 정확도 : 0.457
#SibSp, Parch 제거 전
#훈련 세트 정확도 : 0.603
#테스트 세트 정확도 : 0.476
#FamilySize, isAlone 사용
#훈련 세트 정확도 : 0.582
#테스트 세트 정확도 : 0.484- FamilySize, isAlone은 사용하고 SibSp, Parch는 제거했다.
(특성 중요도에서 큰 역할을 하지못하고 있는 속성을 제거하는게 나은지 두는게 나은지는 아직 정확하게 모르겠다. 여러 시도중...)
모델별 정확도
- 결정 트리 Decision Tree
훈련 세트 정확도 : 0.461
테스트 세트 정확도 : 0.442- 랜덤 포레스트 Random Forest
훈련 세트 정확도 : 0.483
테스트 세트 정확도 : 0.465- 그래디언트 부스팅 Gradient Goosting
훈련 세트 정확도 : 0.567
테스트 세트 정확도 : 0.482- 배깅 Bagging
훈련 세트 정확도 : 0.749
테스트 세트 정확도 : 0.374- XGBoost
훈련 세트 정확도 : 0.61
테스트 세트 정확도 : 0.4 결정 트리와 랜덤 포레스트의 정확도가 비슷했다..
배깅은 결정 트리를 분류기로 학습시켰는데 랜덤 포레스트랑 차이가 컸다...
XGBoost는 추천을 받아 사용해봤는데 데이터를 수정하고 매개변수를 계속 바꿔봐도 쭉 과적합이었다.
이 뒤부터는 랜덤 포래스트와 그래디언트 부스팅 모델만 사용하였다!
그래디언트 부스팅 모델을 사용하여 Age값을 채운 후, 다시 생존자 분류 트레인을 해보기 전!!!!!
선형 모델 : 연속형 데이터 구간 분할
선형 모델에서 연속형 데이터를 사용할 때 구간을 나눠 학습하는 것을 알게 되어 적용해보고싶었다!
그래서 linearRegression모델을 생성하고 Fare 속성에 구간분할을 적용해보았다.
- 구간 분할 전
훈련 세트 정확도 : 0.439
테스트 세트 정확도 : 0.343데이터가 한쪽으로 편향되어있어서 분할 전에 정규화를 해주었다.
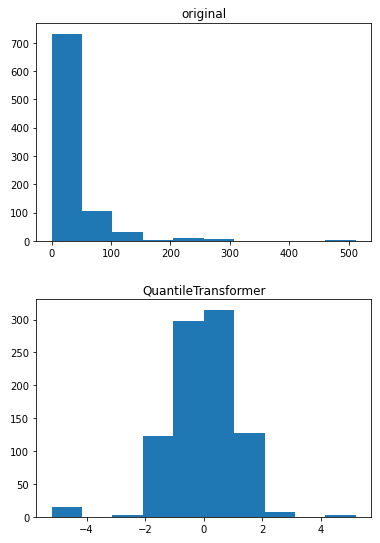
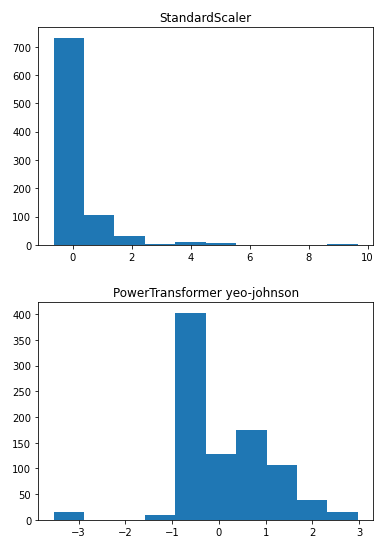
QuantileTransformer를 이용하였다!
총 5구간으로 나눠 원-핫 엔코딩으로 생성!
분류 후, 트레인!
훈련 세트 정확도 : 0.441
테스트 세트 정확도 : 0.331₍ᐢɞ̴̶̷.̮ɞ̴̶̷ᐢ₎?
🤨?
절편말고 기울기도 함께 학습시켜줬다.
훈련 세트 정확도 : 0.442
테스트 세트 정확도 : 0.329🤨?🤨?🤨?🤨?🤨?
다른 데이터셋으로 다시 도전해봐야겠다...
(원본 특성을 곱해보는 것도 있는데 잘 안된다..되면 추가!)
결측값없는 Age 속성으로 다시 트레인!
새로운 속성 추가!
노트북을 이것저것 보다가 아무런 연관없어 보이는 속성을 연산하여 사용하는 것을 보고... 나도 해보고 싶어졌다!!
가설 1. Age와 FamilySize는 연관이 있을 것이다!!
가설 1-1. Age * FamilySize 속성을 추가하면 성능이 향상될 것이다.
가설 1-2. Age / FamilySize 속성을 추가하면 성능이 향상될 것이다.
가설 1-2. FamilySize / Age 속성을 추가하면 성능이 향상될 것이다.
가설 2. FamilySize / Fare 는 자산과 관련있어 성능이 향상될 것이다!
가설 3. Age와 Fare는 !!..
.
.
.
이것저것 시도해보다
남은건
!!!
FamilySize / Age 속성을 추가했다!!!!!
시각화 결과...내 맘에 들었다...
실제론 FamilySize / Age 가 아닌 FamilySize / Age_categoty 를 추가하였다.
- 결정 트리
#추가 전
#훈련 세트 정확도 : 0.817
#테스트 세트 정확도 : 0.782
#훈련 세트 정확도 : 0.838
#테스트 세트 정확도 : 0.838- 랜덤 포레스트
#훈련 세트 정확도 : 0.847
#테스트 세트 정확도 : 0.816
#훈련 세트 정확도 : 0.851
#테스트 세트 정확도 : 0.821- 그래디언트 부스팅
#훈련 세트 정확도 : 0.928
#테스트 세트 정확도 : 0.838
#훈련 세트 정확도 : 0.940
#테스트 세트 정확도 : 0.844ㅇ0ㅇ!!!!!!!!
아라이킷
그 뒤로 Age * Fare, FamilySize/Fare를 해보았지만 정확도가 별 차이 없거나 낮아졌다.
결론!

현재 상위 13%가 됐다! 우하하
이제 시작이지만..시작부터 기분이 좋다 !
