[논문 리뷰]AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
Deep Learning
목록 보기
2/2
stable-diffusion 모델에 한국어 input 을 넣기 위한 방법으로 CLIP encoder를 AltCLIP으로 대체.
갑자기 든 생각.. 데이터를 한국어로 번역한거를 넣어야하지않나..! 그럼 더 정확해질듯..??!
해당 논문을 요약하자면 CLIP 모델의 언어 범위를 늘려서 다양한 언어로도 CLIP 이 똑같은 기능을 작동하도록 하자!
본 논문에서는 두가지 모델을 제안.
- AltCLIP(중국어와 영어)
- AltCLIP-m9(한국어 포함 9개 언어)
- 여기에 사용된 dataset: 1K multi-lingual MSCOCO2014 caption test dataset (XTD10)
- Italian, Spanish, Korean, Russian, Polish, Turkish, Chinese Simplified
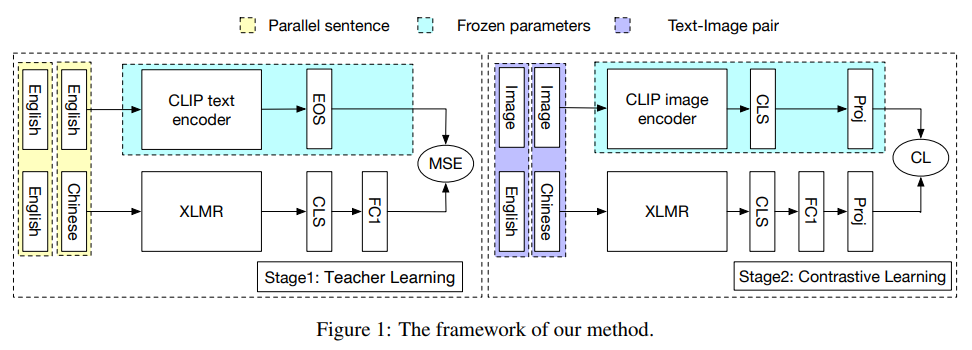
위의 그림처럼 학습시킴. 두 단계로 진행(기존 논문에서는 그냥 teacher learning 방식으로 text 끼리만 embedding 을 비교해가지고 성능이 좋지 않아서 이번에 text-image 쌍도 학습하는 방식도 활용해서 성능을 더 높이고자 한 것임)
- Teacher Learning(knowledge distillation)
- 데이터 및 사용 모델
- 병렬 text 코퍼스 활용()
- teacher model: CLIP text encoder
- student model: multilingual(multilingual language model) 로 사전학습된 XLM-R 모델
- 학습 방식
- 병렬 데이터가 주어지면, (한국어를 예시로 들자면, teacher language가 영어, student language가 한국어)
- ([TOS] token의 embedding) → teacher sentence encoder →
- ([CLS] token의 embedding) → student sentence encoder→
- 이 두 embedding의 간격을 최소화 하기 위한 MSE(Mean Squared Error)로 두 embedding의 간격을 줄여나가는 것임.
- 결과
- 두 언어의 능력을 모두 가질 수 있게 된다. 즉 student model 이 teacher model의 능력을 가지게 되는 것임.
- 두 언어에 대하여 text-image 의 alignment 를 알 수 있게 된다.
- 주의! teacher encoder는 training 할 때만 사용됨! 그니까 inference할 때는 teacher model 사용하면 안된다. 당연하지! (왜냐하면, inference할 때 teacher model 즉 영영어만 사용하는 모델을 대체하고자 student model을 학습시키는 거니까)→ inference할 때는 student encoder가 text encoder로서 사용된다. 다 학습시킨 거니까.
- 우리의 diffusion을 fine tuning 하는 단계에서는 어떻게 사용해야할까? → diffusion의 input에 student learning이 완료된 AltCLIP을 넣어주는 것. 또한 이것을 넣어주었을 때 diffusion 모델 자체도 altdiffusion으로 바꿔주어야 한다. 왜냐면 우리는 다른 데이터로 diffusion모델을 fine tuning 하는 것이다. altdiffusion은 altCLIP을 활용하여 diffusion을 학습했고 학습이 완료된 모델이다. 본 모델에 직접 데이터를 한국어input으로 넣게 되면 당연히 원하는 결과가 나온다. 그러나 우리의 task는 이 모델에 추가적으로 이모지 데이터를 학습시키는 것이기 때문에 한국어 및 이모지를 넣어 학습을 하게 되는데 이 과정에서 한국어를 넣기 때문에 CLIP encoder가 아닌 altCLIP을 넣어야 한다.
- 데이터 및 사용 모델
- Contrastive Loss(CL)
- 데이터 및 사용 모델
- multilingual text-image pairs(LAION, Wudao MM…)
- ViT(image encoder)
- student text encoder(앞선 학습으로부터 도출된 encoder)
- 학습 방법
- 위의 teacher learning과 동일하고 loss만 다름 loss가 contrastive loss임, 이미지 encoder의 output과 text encoder의 output간의 loss를 구함.
- training 할 때 image encoder를 고정, 그리고 text encoder만 업데이트. 왜냐하면 우리가 원하는 output은 student encoder가 좀 더 정확한 output을 갖도록 하는 것이니까 student encoder를 더 학습시키는 것이 필요하기 때문에
- 데이터 및 사용 모델

ML_engineer