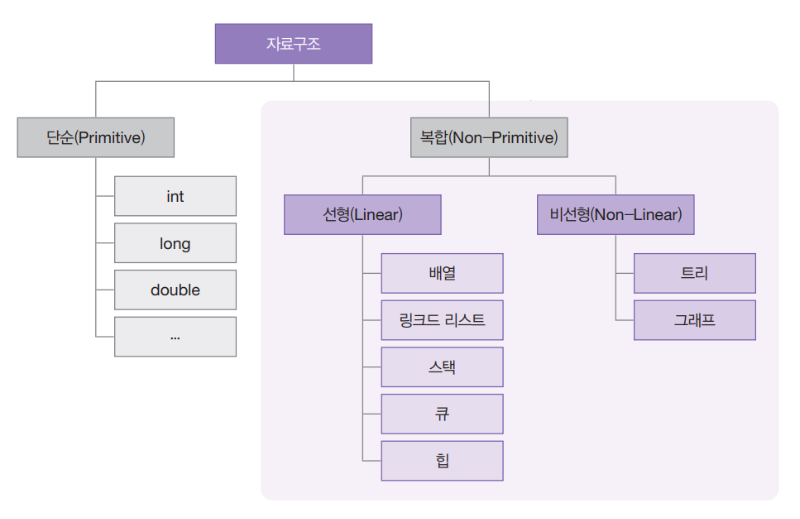
프로그램은 자료구조(어떤 데이터)와 알고리즘(어떻게 구현)으로 되어있다.
자료구조는 데이터가 어떤 구조로 저장되고 어떻게 사용되는지를 나타낸다.
그 중 가장 단순한 자료구조는 변수이다.
그러면 이제 또 다른 자료 구조에 대해 더 파헤쳐보자.
목차
- 배열
- 연결리스트
- 스택
- 큐
- 해시 테이블
- 그래프
- 트리
1. 배열 (Array)
배열은 프로그래밍에서 가장 기본적인 데이터 구조이다. 배열은 인덱스(Index)와 인덱스에 해당하는 요소(Element)로 구성된다.
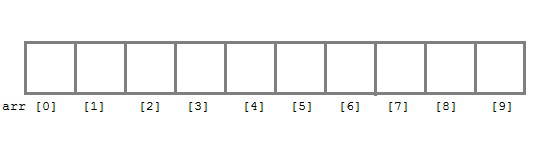
다시 말해, 배열을 선언했다면 운영체제는 메모리에서 숫자가 들어갈 수 있는 빈 공간을 찾아서 순서대로 값들을 할당해줍니다. 할당하지 않은 부분은 쓰레기 값이 저장된다.
특징
-
길이가 고정되어 생성된다.
(정적 메모리 할당) -
운영체제는 배열의 시작 주소만 기억한다.
즉, 인덱스를 통해서 각 요소에 직접 접근할 수 있는 특징이 있다. (ex arr[3])
(= Random Access를 지원한다.)
3.배열은 논리적 순서와 물리적 순서가 일치한다. 인접한 메모리 위치에 연이어 저장된다.
-
배열은 읽기/쓰기 등 참조에서 좋은 성능을 보여준다.
(읽기/쓰기와 같은 참조에는 O(1)의 성능을 가진다.) -
배열은 읽기/쓰기에 비해 추가/삭제는 성능이 떨어진다.
시간 복잡도
-
검색 (Search) : 요소마다 인덱스를 부여했기 때문에, 특정 요소를 접근하는 시간 복잡도는 O(1)이다. 하지만, 인덱스를 모르는 특정 값을 찾기 위해서는 배열의 모든 요소들을 살펴봐야 하기 때문에 O(n)의 시간 복잡도를 갖는다.
-
추가/삭제 (Insert/Delete) : 삽입이나 삭제를 하기 위해서는 길이가 고정되어 있기 때문에 차례대로 한 칸씩 밀어야 하는 과정이 필요하고 그 과정에서 O(n)의 시간 복잡도가 생긴다.
2. 연결리스트 (Linked List)
배열의 추가/삭제 연산에 대한 비효율성을 극복하고자 등장한 데이터 구조이다.
데이터들을 메모리 공간에 분산 할당하고 이 데이터들을 서로 연결해준다.
이것은 노드라는 것을 만들어서 수행한다. 노드의 구조는 데이터르 담는 변수 하나와 다음 노드를 가리키는 변수 하나를 말한다.
(각 요소는 다음 노드 연결에 대한 정보를 담은 포인터 또는 주소와 함께 노드에 저장된다.)
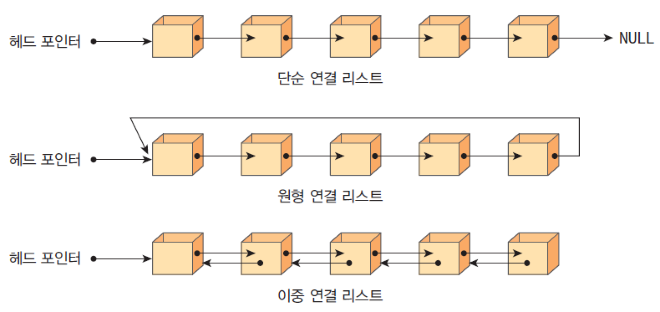
필요한 노드를 만들어 연결하는데 이런 구조를 연결 리스트라고 한다.
연결 리스트의 종류로는 단일 연결 리스트, 이중 연결 리스트, 원형 연결 리스트 등의 종류가 있다.
특징
-
새로운 요소가 추가될 때 런타임에 메모리를 할당한다.
(동적 메모리 할당) -
요소에 접근할 때 순차적으로 접근해야 하는 특징이 있다.
(= Sequential Access를 지원한다.) -
인덱스나 위치와 같은 물리적 배치를 사용하지 않고 참조 시스템(다음 노드 연결에 대한 포인터 또는 주소)을 사용한다.
시간 복잡도
- 검색 (Search) : 처음부터 순차적으로 접근해야 하기 때문에 O(n)의 시간 복잡도를 갖는다.
- 추가/삭제 (Insert/Delete) : 동적인 메모리 크기를 갖기 때문에, 새로운 요소를 추가하거나 삭제할 경우에 해당되는 부분만 변경하면 되기 때문에 O(1)의 시간 복잡도를 갖는다.
연결리스트와 배열의 차이점
- 연결리스트에서의 데이터 참조는 O(n)의 성능을 가진다. 배열은 O(1)의 성능을 가져서 더 좋음.
- 데이터의 접근의 경우 Array는 Random Access를 그리고 Linked List는 Sequential Access를 지원한다. 따라서, 특정 요소에 접근하는 경우 Array는 직접 접근할 수 있어 효율적이고, Linked List는 처음부터 순차적으로 접근해야 해서 비효율적이다.
- 데이터의 추가/삭제 Array의 경우 크기가 고정되어 있어서, 추가 및 삭제를 위해서는 다른 요소들의 주소도 전부 변경해야 하기 때문에 비효율적인데, Linked List의 경우 추가 및 삭제 시 해당되는 요소의 메모리 주소만 변경하면 되기 때문에 보다 효율적이다.
- 메모리 할당에서도 차이가 나는데 Array는 선언 시 요소들을 인접한 메모리 위치에 연이어 저장하고 크기가 고정되어 있는 정적 메모리 할당, Linked List의 경우 새로운 요소가 추가되면 메모리를 할당하고 그 정보를 저장하는 동적 메모리 할당.
성능? 메모리?
성능을 생각하면 배열이고, 메모리 절약을 위해서는 연결리스트를 선택하면 된다.
3. 스택 (Stack)
순서가 보존되는 선형 자료구조의 일종으로, LIFO(Last In First Out) 메커니즘을 갖고 있다.
(쌓인 접시라고 생각하면 좋다. 맨 아래 접시를 꺼내려면 위의 접시들을 꺼내야 한다.)
특징
- 데이터를 받는 순서대로 정렬한다.
2.LIFO, 마지막으로 입력된 것을 순차적으로 가져오는 방법을 갖고 있는 것이 특징이다.
3.동적 메모리
스택의 ADT(추상 자료형)
- push 데이터 삽입
- pop 데이터 제거
- peek 데이터 참조
- isEmpty 비었는지 체크
시간 복잡도
- 검색 (Search) : 처음부터 순차적으로 접근해야 하기 때문에 O(n)의 시간 복잡도를 갖는다.
- 추가/삭제 (Insert/Delete) : 가장 위에 데이터를 추가하거나 삭제하기 때문에 O(1)의 시간 복잡도를 갖는다.
다시 정리
-
스택이란
- 데이터를 집어넣을 수 있는 선형 자료형이다.
- • 나중에 집어넣은 데이터가 먼저 나옵니다.
- 이 특징을 줄여서 LIFO(Last In First Out)라고 부릅니다.
-
스택의 구조
-
스택의 연산
ADT Stack 데이터 : 0개 이상의 원소를 가진 유한의 순서 리스트 연산 : S ∈ Stack; E ∈ Element; - create(S) ::= 스택 생성 연산 - isEmpty(S) ::= 스택 S가 비어있는지 검사하는 연산 - isFull(S) ::= 스택 S가 가득 찼는지 검사하는 연산 - push(S, E) ::= 스택의 맨 위에 요소 E를 추가하는 연산 - pop(S) ::= 스택의 맨 위에 있는 요소를 삭제하는 연산 - peek(S) ::= 요소를 스택에서 삭제하지 않고 보기만 하는 연산 END Stack
-
관련 용어
- 언더플로우(Underflow) : 스택이 비어 자료를 꺼낼 수 없는 상태
- 오버플로우(Overflow) : 스택이 가득 차 자료를 더 이상 입력할 수 없는 상태
-
스택의 구현
- 앞선 과정에서 어떻게 구현할 수 있는가에 대해서 고민해 보았다. 이번에는 그를 바탕으로 C언어에서 구현해 보겠다. 스택의 크기는 5로 설정하고 A, B, C, D, E 문자를 입력 후 출력하는 과정을 수행하도록 지정하였다.
#include <stdio.h>#define StackSize 5 char stack[StackSize]; int top = -1; // 스택이 비었는지 검사하는 함수 int isEmpty() { return(top == -1 ? 1 : 0); } // 스택이 찼는지 검사하는 함수 int isFull() { return(top == (StackSize - 1) ? 1 : 0); } // 스택에 원소를 넣는 함수 void push(char item) { if(isFull() == 1) { printf("스택이 모두 찼습니다.\n"); } else { stack[++top] = item; } } // 스택에서 원소를 제거하는 함수 char pop() { if (isEmpty() == 1) { printf("스택이 비었습니다.\n"); } else { printf("%c\n",stack[top]); return stack[top--]; } } int main () { push('A'); push('B'); push('C'); push('D'); push('E'); printf("isFull : %d\n", isFull()); pop(); pop(); pop(); pop(); pop(); printf("isEmpty : %d", isEmpty()); }
- 앞선 과정에서 어떻게 구현할 수 있는가에 대해서 고민해 보았다. 이번에는 그를 바탕으로 C언어에서 구현해 보겠다. 스택의 크기는 5로 설정하고 A, B, C, D, E 문자를 입력 후 출력하는 과정을 수행하도록 지정하였다.
-
스택은 어디에 쓰여?
- 최근 항목 조회
- 웹사이트 뒤로 가기
- 실행 취소 (undo)
- 재귀 알고리즘
-
자바스크립트 스택 구현
export default class Stack {
constructor() {
*// item들을 받을 배열 생성*
this.items = [];
}
push(item) {
this.items.push(item);
}
pop() {
return this.items.pop();
}
peek() {
if (this.items.length === 0) {
return null;
}
*// items 배열의 마지막 item만 가져와준다. pop()과 다르게 배열에서 아이템이 빠지는 것이 아닌 유지된 채로 마지막 값만 받아와줌*
return this.items[this.items.length - 1];
}
getSize() {
return this.items.length;
}
isEmpty() {
return this.getSize() === 0;
}
}| Big-O (시간복잡도) | 삽입 | 삭제 | 접근 | n번째 접근 | 검색 |
|---|---|---|---|---|---|
| 스택 (Stack) | O(1) | O(1) | O(1) | O(n) | O(n) |
4. 큐
(흔히 우리가 맛집 줄서기, 은행 순서 기다리기를 생각해보면 좋다.)

