
기본 구조
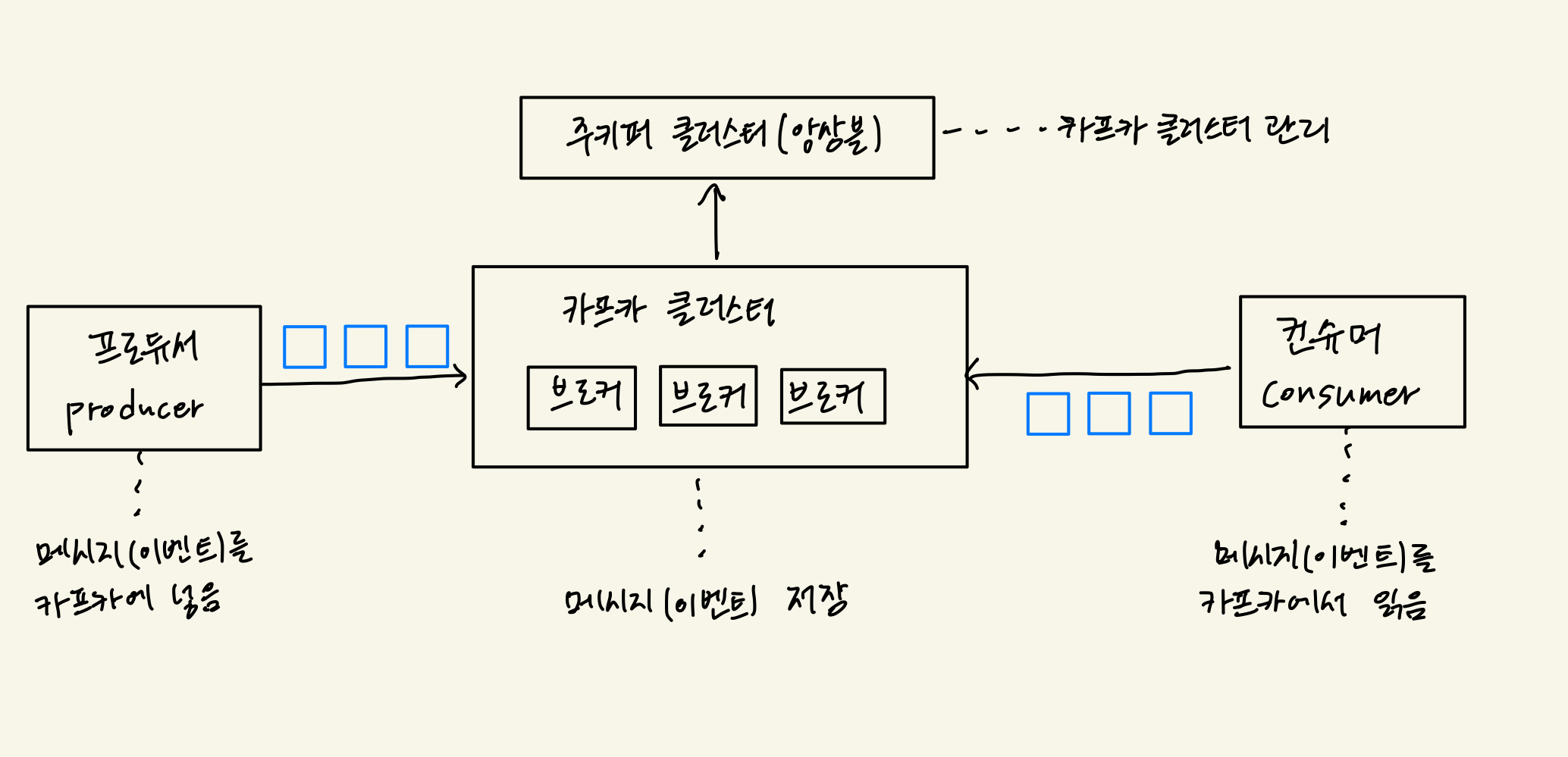
카프카 브로커
카프카 브로커는 카프카 클라이언트와 데이터를 주고받기 위해 사용하는 주체이자, 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션이다.
- 데이터를 안전하게 보관하고 처리하기 위해 3대 이상의 브로커 서버를 1개의 클러스터로 묶어서 운영한다.
- 클러스터로 묶인 브로커들은 프로듀서가 보낸 데이터를 안전하게 분산 저장하고 복제하는 역할을 수행한다.
프로듀서
카프카에서 데이터의 시작점은 프로듀서이다. 카프카에 필요한 데이터를 선언하고 브로커의 특정 토픽의 파티션에 전송한다.
- 프로듀서는 데이터를 전송할 때 리더 파티션을 가지고 있는 카프카 브로커와 직접 통신한다.
- 데이터를 직렬화하여 카프카 브로커로 보내기 때문에 Java에서 선언 가능한 모든 형태를 브로커로 전송할 수 있다.
public class SimpleProducer {
private final static Logger logger = Loggerfactory.getLogger(SimpleProducer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "my-kafka:9092";
pubilc static void main(String[] args) {
Properties configs = new Properties();
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
String messageValue = "testMessage";
ProducerRecode<String, String> recode = new ProducerRecode<>(TOPIC_NAME, messageValue);
producer.send(record);
logger.info("{}", record);
producer.flush();
producer.close();
}
}컨슈머
프로듀서가 전송한 데이터는 카프카 브로커에 적재된다. 컨슈머는 적재된 데이터를 사용하기 위해 브로커로부터 데이터를 가져와서 필요한 처리를 한다.
public class SimpleConsumer {
private final static Logger logger = Loggerfactory.getLogger(SimpleConsumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "my-kafka:9092";
private final static String GROUP_ID = "test-group";
pubilc static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true) {
ConsumerRecodes<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecode<String, String> recode : records) {
logger.info("{}", recode);
}
}
}
}토픽과 파티션
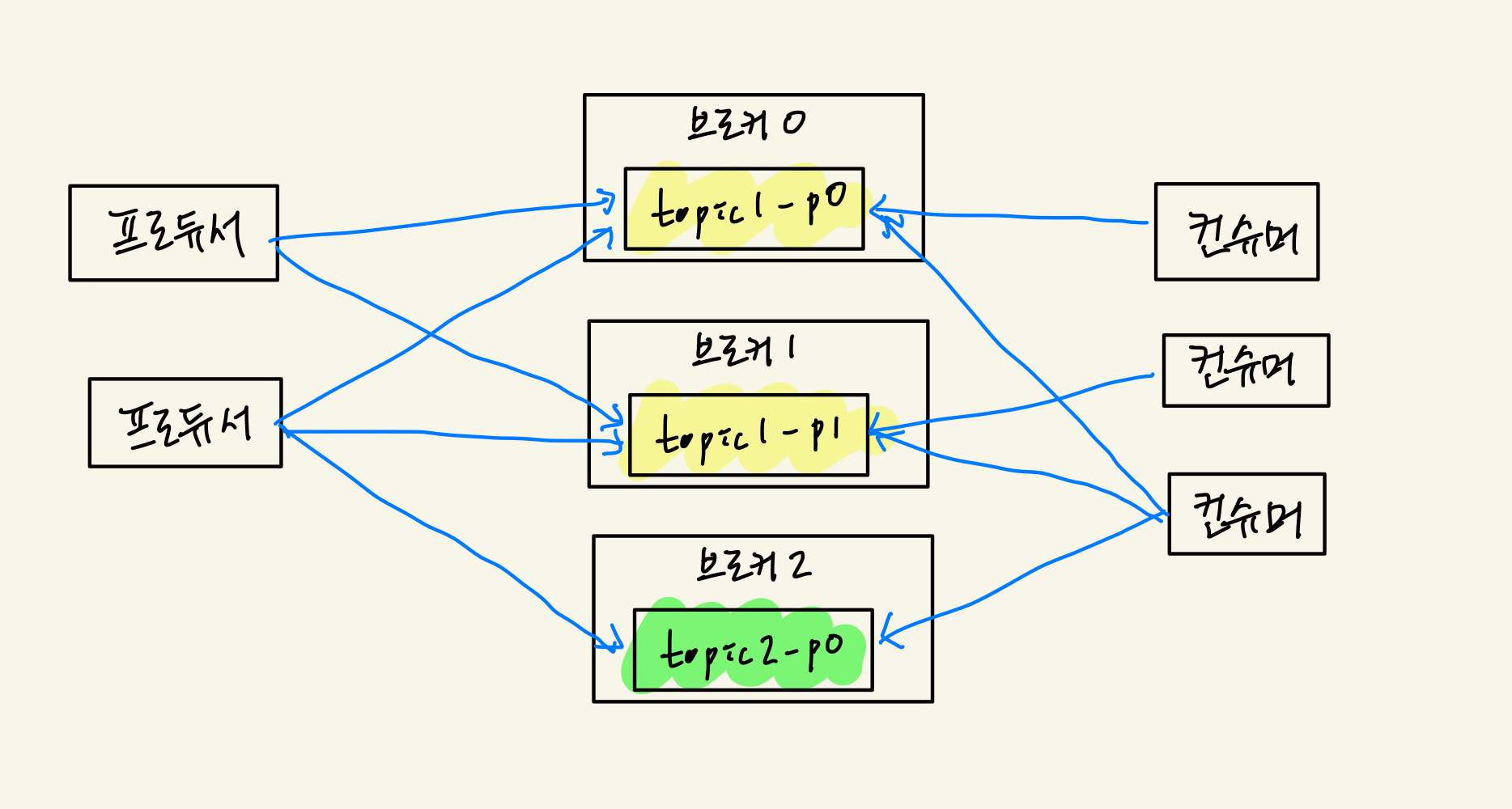
- 토픽은 메시지를 구분하는 단위: 파일시스템의 폴더와 유사함
- 한 개의 토픽은 한 개 이상의 파티션으로 구성됨
- 파티션은 메시지를 저장하는 물리적인 파일
파티션과 오프셋, 메시지 순서
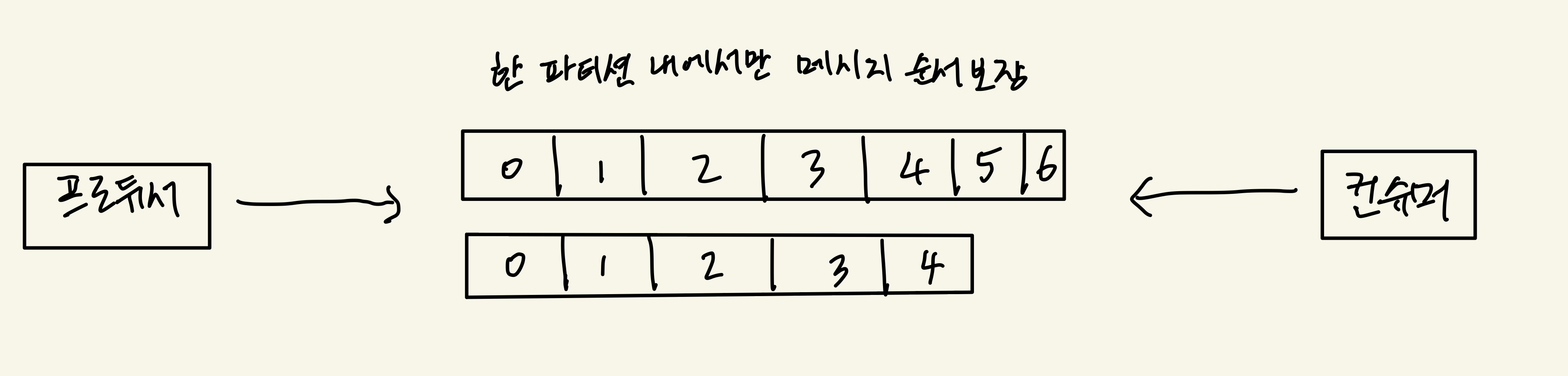
- 파티션은 추가만 가능한(append-only) 파일
- 각 메시지 저장 위치를 offset이라 함
- 프로듀서가 넣은 메시지는 파티션의 맨 뒤에 추가
- 컨슈머는 오프셋 기준으로 메시지를 순서대로 읽음
- 메시지는 삭제되지 않음(설정에 따라 일정 시간이 지난 뒤 삭제)
여러 파티션과 프로듀서
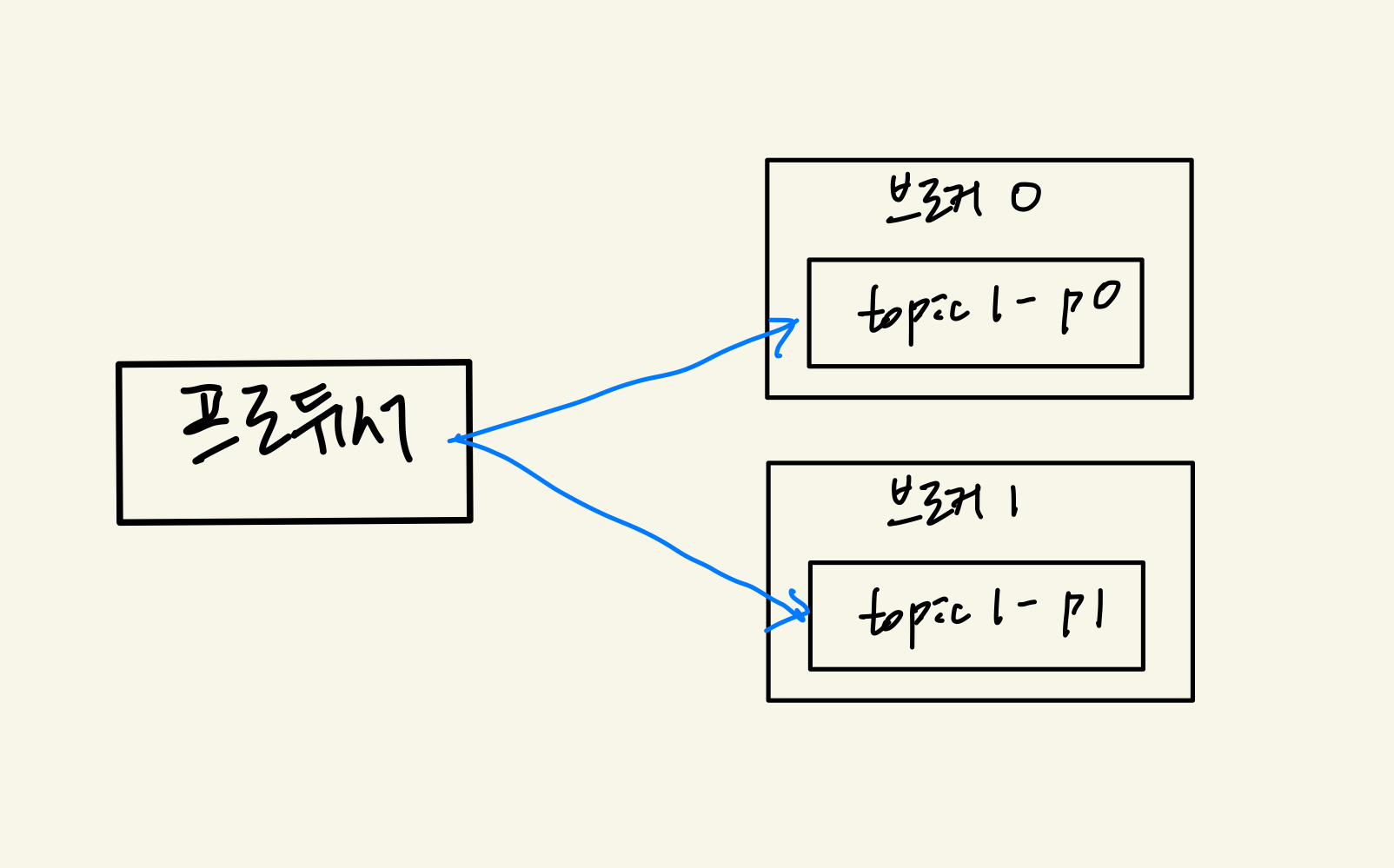
프로듀서는 라운드로빈 또는 키로 파티션을 선택한다.
- 같은 키를 갖는 메시지는 같은 파티션에 저장함
- 같은 키는 순서 유지
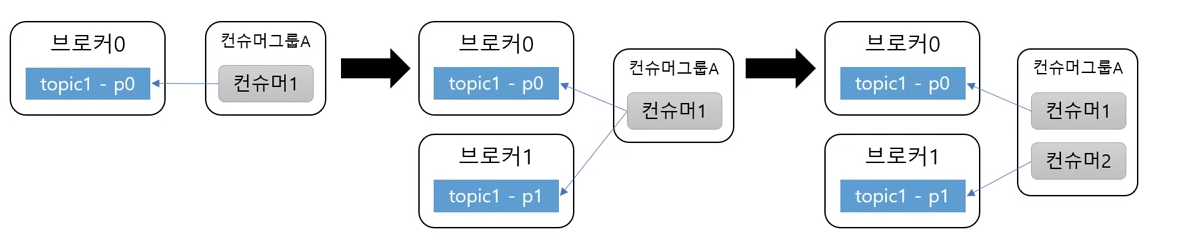
여러 파티션과 컨슈머
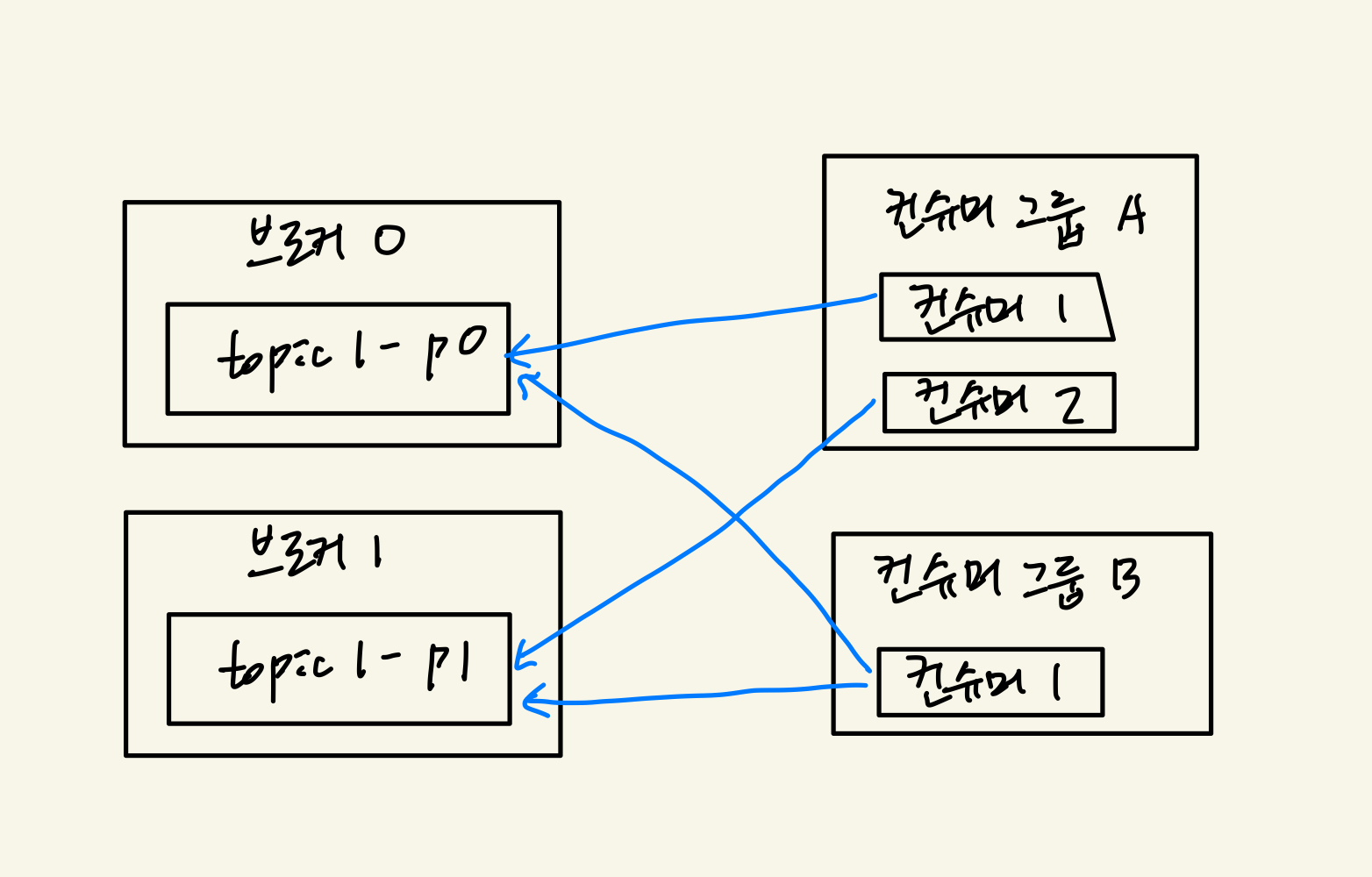
- 컨슈머는 컨슈머 그룹에 속함
- 한 개 파티션은 컨슈머 그룹의 한 개 컨슈머만 연결 가능
- 컨슈머 그룹에 속한 컨슈머들은 한 파티션을 공유할 수 없다.
- 한 컨슈머 그룹 기준으로 파티션의 메시지는 순서대로 처리함.
카프카와 성능
- 파티션 파일은 OS 페이지 캐시 사용
- 파티션에 대한 파일 I/O를 메모리에서 처리
- 서버에서 페이지 캐시를 카프카만 사용해야 성능에 유리
- Zero Copy
- 디스크 버퍼에서 네트워크 버퍼로 직접 데이터 복사
- 컨슈머 추적을 위해 브로커가 하는 일이 비교적 단순함
- 메시지 필터, 메시지 재전송과 같은 일은 브로커가 하지 않음
- 프로듀서, 컨슈머가 직접 해야 한다.
- 브로커는 컨슈머와 파티션 간 매핑 관리
- 메시지 필터, 메시지 재전송과 같은 일은 브로커가 하지 않음
- 묶어서 보내기, 묶어서 받기 (batch)
- 프로듀서: 일정 크기만큼 메시지를 모아서 전송 가능
- 컨슈머: 최소 크기만큼 메시지를 모아서 조회 가능
- 낱개 처리보다 처리량 증가
- 처리량 증대(확장)가 쉽다
- 1개 장비의 용량 한계 → 브로커 추가, 파티션 추가
- 컨슈머가 느림 → 컨슈머 추가 (+ 파티션 추가)
리플리카 - 복제
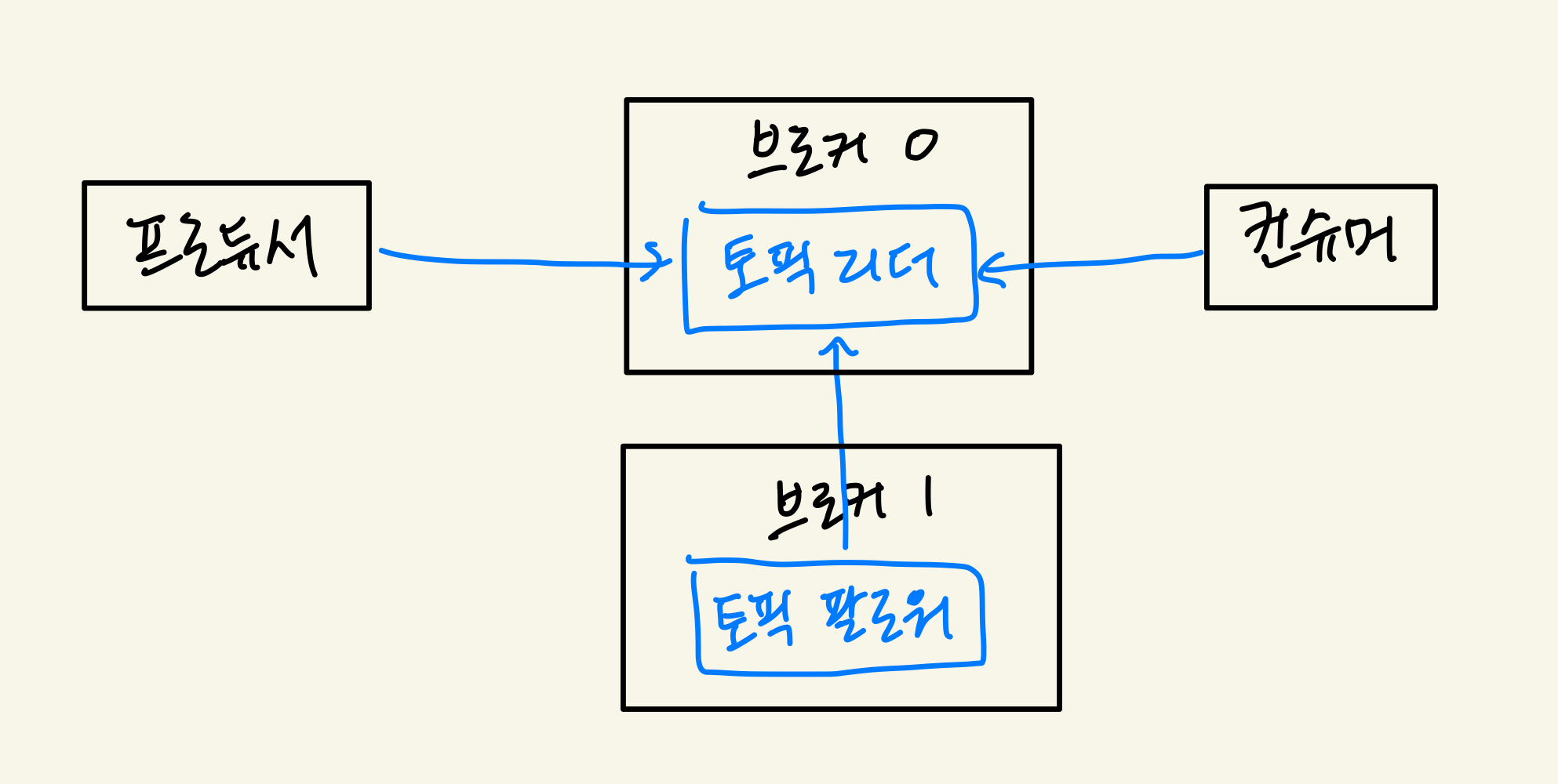
- 리플리카: 파티션의 복제본
- replication factor 만큼 파티션의 복제본이 각 브로커에 생김
- 리더와 팔로워로 구성
- 프로듀서와 컨슈머는 리더를 통해서만 메시지 처리
- 팔로워는 리더로부터 복제
- 장애 대응
- 리더가 속한 브로커 장애시 다른 팔로워가 리더가 됨
References
- kafka 조금 아는 척하기 1
- 아파치 카프카 애플리케이션 프로그래밍 with 자바

블로그 이전 → https://ramos-log.tistory.com/