
토픽 파티션은 그룹 단위로 할당
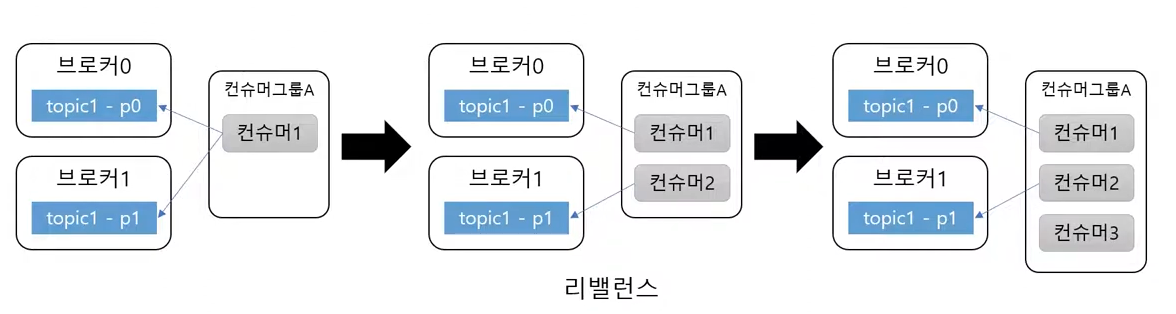
- 컨슈머 그룹 단위로 파티션을 할당한다.
- 파티션 그룹보다 컨슈머 그룹이 많아지면 유휴상태의 컨슈머가 많아지게 된다.
- 컨슈머 그룹이 파티션 그룹보다 많아지면 안된다.
- 만약 처리량이 떨어져 파티션을 늘려야 한다면 컨슈머 또한 늘려야 한다.
커밋과 오프셋
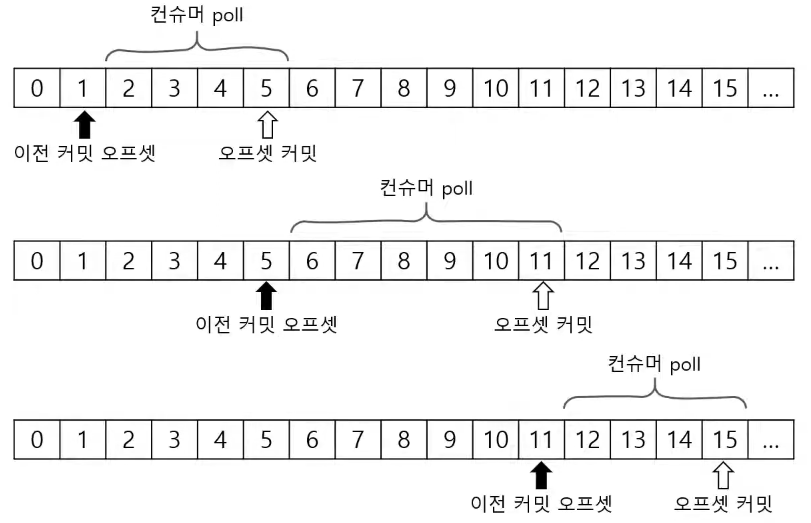
컨슈머는 커밋 과정을 반복한다. 카프카 브로커로부터 데이터를 어디까지 가져갔는지 커밋을 통해 기록하는 것이다.
비명시적 오프셋 커밋
오프셋 커밋은 컨슈머 애플리케이션에서 명시적, 비명시적으로 수행할 수 있다.
기본 옵션은 poll() 메서드가 수행될 때 일정 간격마다 오프셋을 커밋하도록 enable.auto.commit=true로 설정되어 있다. 이를 비명시 오프셋 커밋이라 한다.
장단점은 다음과 같다.
poll()메서드를 호출할 때 커밋을 수행하므로 코드상에서 따로 커밋 관련 코드를 작성할 필요가 없다.poll()메서드 호출 뒤 리밸런싱 또는 컨슈머 강제종료 발생 시 컨슈머가 처리하는 데이터가 중복 또는 유실될 수 있는 가능성이 있다.
명시적 오프셋 커밋
명시적으로 오프셋을 커밋하려면 poll() 메서드 호출 이후 반환받은 데이터의 처리가 완료되고 commitSync() 메서드를 호출하면 된다. 이 메서드는 poll() 메서드를 통해 반환된 레코드의 가장 마지막 오프셋을 기준으로 커밋을 수행한다.
commitSync() 메서드는 브로커에 커밋 요청을 하고 커밋이 정상적으로 처리되었는지 응답하기까지 기다리는데 이는 컨슈머의 처리량에 영향을 끼친다. 데이터 처리 시간에 비해 커밋 요청 및 응답에 시간이 오래 걸린다면 동일 시간당 데이터 처리량이 줄어들기 때문이다.
이를 해결하기 위해 commitAsync() 메서드를 통해 커밋 요청을 전성하고 응답이 오기 전까지 데이터 처리를 수행하곤 한다. 하지만, 이러한 비동기 커밋은 커밋 요청이 실패했을 경우 현재 처리 중인 데이터의 순서를 보장하지 않으며 데이터의 중복 처리가 발생할 수 있다.
커밋된 오프셋이 없는 경우
- 처음 접근이거나 커밋한 오프셋이 없는 경우
auto.offset.reset설정 사용earliest: 맨 처음 오프셋 사용latest: 가장 마지막 오프셋 사용 (default)none: 컨슈머 그룹에 대한 이전 커밋이 없으면 Exception 발생
컨슈머 설정
조회에 영향을 주는 주요 설정
fetch.min.bytes: 조회시 브로커가 전송할 최소 데이터 크기- default: 1
- 이 값이 크면 대기 시간은 늘지만 처리량이 증가
fetch.max.wait.ms: 데이터가 최소 크기가 될 때까지 기다리는 시간- default: 500
- 브로커가 리턴할 때까지 대기하는 시간으로
poll()메서드의 대기 시간과 다름
max.partition.fetch.bytes: 파티션 당 서버가 리턴할 수 있는 최대 크기.- default: 1048567(1MB)
자동 커밋/수동 커밋
enable.auto.committrue: 일정 주기로 컨슈머가 읽은 오프셋을 커밋 (default)false: 수동으로 커밋 실행
auto.commit.interval.ms: 자동 커밋 주기- default: 5000 (5초)
poll(),close()메서드 호출 시 자동 커밋 실행
재처리와 순서
- 동일 메시지 조회 가능성
- 일시적 커밋 실패, 리밸런스 등에 의해 발생
- 컨슈머는 멱등성을 고려해야 한다.
- ex) 조회수 1 증가 → 좋아요 1 증가 → 조회 수 1 증가
- 단순 처리 하면 조회수는 2가 아닌 4가 될 수 있다.
- 데이터 특성에 따라 타임스탬프, 일련 번호 등을 활용한다.
세션 타임아웃, 하트비트, 최대 poll 간격
컨슈머는 하트비트를 전송해서 연결을 유지한다. 브로커는 일정 시간 컨슈머로부터 하트비트가 없으면 컨슈머를 그룹에서 빼고 리밸런스를 진행한다.
관련 설정은 다음과 같다.
session.timeout.ms: 세션 타임 아웃 시간 (defalut 10초)heartbeat.interval.ms: 하트비트 전송 주기 (default 3초)session.timeout.ms의 1/3 이하 추천
max.poll.interval.ms는 poll() 메서드의 최대 호출 간격을 설정한다. 이 시간이 지나도록 poll() 하지 않으면 컨슈머를 그룹에서 빼고 리밸런스를 진행한다.
주의사항
KafkaConsumer는 쓰레드에 안전하지 않다. 여러 쓰레드에서 동시에 사용하면 안된다. 단, wakeup() 메서드는 예외이다.
References
- kafka 조금 아는 척하기 3
- 아파치 카프카 애플리케이션 프로그래밍 with 자바
