
1. WINDOW FUNCTION 개요
기존 관계형 데이터베이스는 칼럼과 칼럼간의 연산, 비교, 연결이나 집합에 대한 집계는 쉬운 반면, 행과 행간의 관계를 정의하거나, 행과 행간을 비교, 연산하는 것을 하나의 SQL 문으로 처리 하는 것은 매우 어려운 문제였다.
PL/SQL, SQL/PL, T-SQL, PRO*C 같은 절차형 프로그램을 작성하거나, INLINE VIEW를 이용해 복잡한 SQL 문을 작성해야 하던 것을 부분적이나마 행과 행간의 관계를 쉽게 정의하기 위해 만든 함수가 바로 WINDOW FUNCTION이다. 윈도우 함수를 활용하면 복잡한 프로그램을 하나의 SQL 문장으로 쉽게 해결할 수 있다.
분석 함수(ANALYTIC FUNCTION)나 순위 함수(RANK FUNCTION)로도 알려져 있는 윈도우 함수(ANSI/ISO SQL 표준은 WINDOW FUNCTION이란 용어를 사용함)는 데이터웨어하우스에서 발전한 기능이다. SQL 사용자 입장에서는 INLINE VIEW 이후 SQL의 중요한 기능이 추가되었다고 할 수 있으며, 많은 프로그램이나 튜닝 팁을 대체할 수 있을 것이다.
복잡하거나 자원을 많이 사용하는 튜닝 기법들을 대체할 수 있는 DBMS의 새로운 기능은 튜닝 관점에서도 최적화된 방법이므로 적극적으로 활용할 필요가 있다. 같은 결과가 나오는 변형된 튜닝 문장보다는 DBMS 벤더에서 최적화된 자원을 사용하도록 만들어진 새로운 기능을 사용하는 것이 일반적으로 더욱 효과가 좋기 때문이다.
WINDOW 함수는 기존에 사용하던 집계 함수도 있고, 새로이 WINDOW 함수 전용으로 만들어진 기능도 있다. 그리고 WINDOW 함수는 다른 함수와는 달리 중첩(NEST)해서 사용하지는 못하지만, 서브쿼리에서는 사용할 수 있다.
WINDOW FUNCTION 종류
WINDOW FUNCTION의 종류는 크게 다섯 개의 그룹으로 분류할 수 있는데 벤더별로 지원하는 함수에는 차이가 있다.
첫 번째, 그룹 내 순위(RANK) 관련 함수는 RANK, DENSE_RANK, ROW_NUMBER 함수가 있다. ANSI/ISO SQL 표준과 Oracle, SQL Server 등 대부분의 DBMS에서 지원하고 있다.
두 번째, 그룹 내 집계(AGGREGATE) 관련 함수는 일반적으로 많이 사용하는 SUM, MAX, MIN, AVG, COUNT 함수가 있다. ANSI/ISO SQL 표준과 Oracle, SQL Server 등 대부분의 DBMS에서 지원하고 있는데, SQL Server의 경우 집계 함수는 뒤에서 설명할 OVER 절 내의 ORDER BY 구문을 지원하지 않는다.
세 번째, 그룹 내 행 순ㄴ서 관련 함수는 FIRST_VALUE, LAST_VALUE, LAG, LEAD 함수가 있다. Oracle에서만 지원되는 함수이기는 하지만, FIRST_VALUE, LAST_VALLUE 함수는 MAX, MIN 함수와 ㅂ비슷한 결과ㅏ를 얻을 수 있고, LAG, LEAD 함수는 DW에서 유용하게 사용되는 기능이다.
네 번째, 그룹 내 비율 관련 함수는 CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT 함수가 있다. CUME_DIST, PERCENT_RANK 함수는 ANSI/ISO SQL 표준과 Oracle DBMS에서 지원하고 있으며, NTILE 함수는 ANSI/ISO SQL 표준에는 없지만,, Oracle, SQL Server에서 지원하고 있다. 마지막으로 RATIO_TO_REPORT 함수는 Oracle에서만 지원된다.
다선 번째, 선형 분석을 포함한 통계 분석 관련 함수가 있다.
아래는 Oracle의 통계 관련 함수를 참조로 표시한 것이다.
CORR, COVARPOP, COVAR_SAMP, STDDEV, STDDEV_POP, STDDEV_SAMP, VARIANCE, VAR_POP, VAR_SAMP, REGR(LINEAR REGRESSION), REGR_SLOPE, REGR_INTERCEPT, REGR_COUNT, REGR_R2, REGR_AVGX, REGR_AVGY, REGR_SXX, REGR_SYY, REGR_SXY
WINDOW FUNCTION SYNTAX
WINDOW 함수에는 OVER 문구가 키워드로 필수 포함된다.
SELECT WINDOW_FUNCTIOON (ARGUMENTS) OVER
( [PARTITION BY COLUMN] [ORDER BY] [WINDOWING] )
FROM TABLE_NAME;WINDOW_FUNCTION
기존에 사용하던 함수도 있고, 새롭게 WINDOW 함수용으로 추가된 함수도 있다.
ARGUMENTS
함수에 따라 0 ~ N개의 인수가 지정될 수 있다.
PARTITION BY
전체 집합을 기준에 의해 소그룹으로 나눌 수 있다.
ORDER BY
어떤 항목에 대해 순위를 지정할 지 ORDER BY 절을 기술한다.
WINDOWING
WINDOWING 절은 함수의 대상이 되는 행 기준의 범위를 강력하게 지정할 수 있다. ROWS는 물리적인 결과 행의 수를, RANGE는 논리적인 값에 의한 범위를 나타내는데, 둘 중 하나를 선택해서 사용할 수 있다. 다만, WINDOWING 절은 SQL Server에서는 지원하지 않는다.
BETWEEN 사용 타입
ROWS | RANGE BETWEEN
UNBOUNDED PRECEDING | CURRENT ROW | VALUE_EXPR PRECEDING/FOLLOWING
AND
UNBOUNDED FOLLOWING | CURRENT ROW | VALUE_EXPR PRECEDING/FOLLOWING
BETWEEN 미사용 타입
ROWS | RANGE
UNBOUNDED PRECEDING | CURRENT ROW | VALUE_EXPR PRECEDING가. RANK 함수
RANK 함수는 ORDER BY를 포함한 QUERY 문에서 특정 항목(칼럼)에 대한 순위를 구하는 함수이다. 이때 특정 범위(PARTITION) 내에서 순위를 구할 수도 있고 전체 데이터에 대한 순위를 구할 수도 있다. 또한 동일한 값에 대해서는 동일한 순위를 부여하게 된다.
-- 사원 데이터에서 급여가 높은 순서와 JOB 별로 급여가 높은 순서를 같이 출력한다.
SELECT
JOB,
ENAME,
SAL,
RANK()
OVER (ORDER BY SAL DESC) ALL_RANK,
RANK()
OVER (
PARTITION BY JOB
ORDER BY SAL DESC) JOB_RANK
FROM EMP;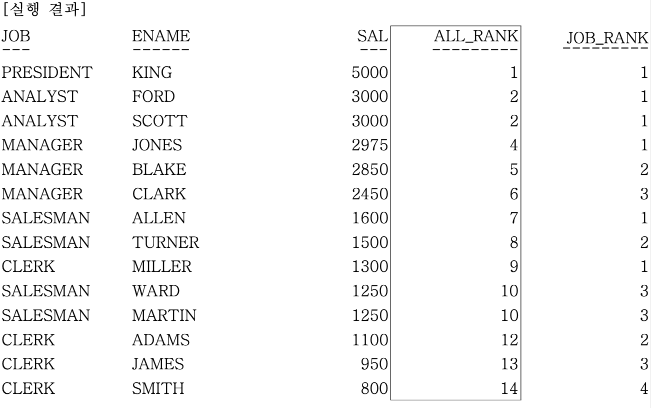
업무 구분이 없는 ALL_RANK 칼럼에서 FORD와 SCOTT, WARD와 MARTIN은 동일한 SALARY이므로 같은 순위를 부여한다. 그리고 업무를 PARTITION으로 구분한 JOB_RANK의 경우 같은 업무 내 범위에서만 순위를 부여한다.
하나의 SQL 문장에 ORDER BY SAL DESC 조건과 PARTITION BY JOB 조건이 충돌이 났기 때문에 JOB 별로는 정렬이 되지 않고, ORDER BY SAL DESC 조건으로 정렬이 되었다.
-- 전체 SALARY 순위를 구하는 ALL_RANK 칼럼은 제외하고,
-- 업무별로 SALARY 순서를 구하는 JOB_RANK만 알아보도록 한다.
SELECT
JOB,
ENAME,
SAL,
RANK()
OVER (
PARTITION BYJOB
ORDER BY SAL DESC) JOB_RANK
FROM EMP;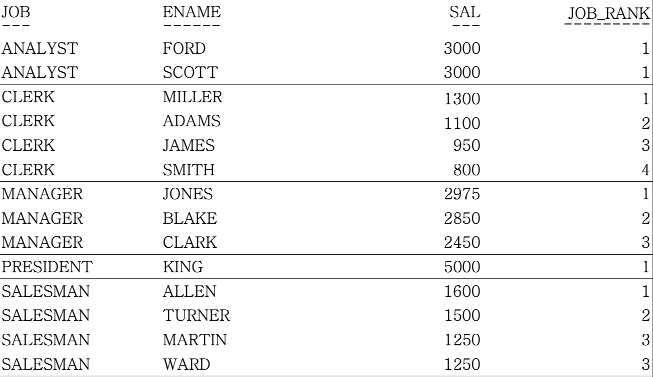
나. DENSE_RANK 함수
DENSE_RANK 함수는 RANK 함수와 흡사하나, 동일한 순위를 하나의 건수로 취급하는 것이 틀린 점이다.
-- 사원데이터에서 급여가 높은 순서와, 동일한 순위를
-- 하나의 등수로 간주한 결과도 같이 출력한다.
SELECT
JOB,
ENAME,
SAL,
RANK()
OVER (ORDER BY SAL DESC) RANK,
DENSE_RANK()
OVER(ORDER BY SAL DESC) DENSE_RANK
FROM EMP;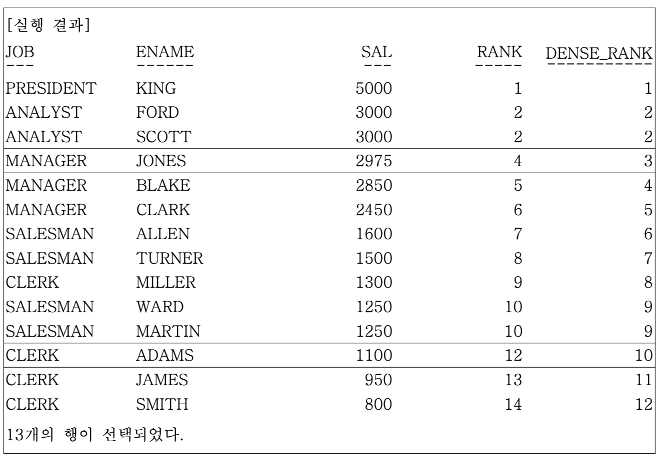
FORD와 SCOTT, WARD와 MARTIN은 동일한 SALARY이므로 RANK와 DENSE_RANK 칼럼에서 모두 같은 순위를 부여한다.
그러나 RANK와 DENSE_RANK의 차이를 알 수 있는 데이터는 FROD와 SCOTT의 다음 순위인 JONES의 경우 RANK는 4등으로 DENSE_RANK는 3등으로 표시되어 있다. 마찬가지로 WARD와 MARTIN의 다음 순위인 ADAMS의 경우 RANK는 12등으로 DENSE_RANK는 10등으로 표시되어 있다.
다. ROW_NUMBER 함수
ROW_NUMBER 함수는 RANK나 DENSE_RANK 함수가 동일한 값에 대해서는 동일한 순위를 부여하는데 반해, 동일한 값이라도 고유한 순위를 부여한다.
-- 사원데이터에서 급여가 높은 순서와,
-- 동일한 순위를 인정하지 않는 등수도 같이 출력한다.
SELECT
JOB,
ENAME,
SAL,
RANK()
OVER (ORDER BY SAL DESC) RANK,
ROW_NUMBER()
OVER(ORDER BY SAL DESC) DENSE_RANK
FROM EMP;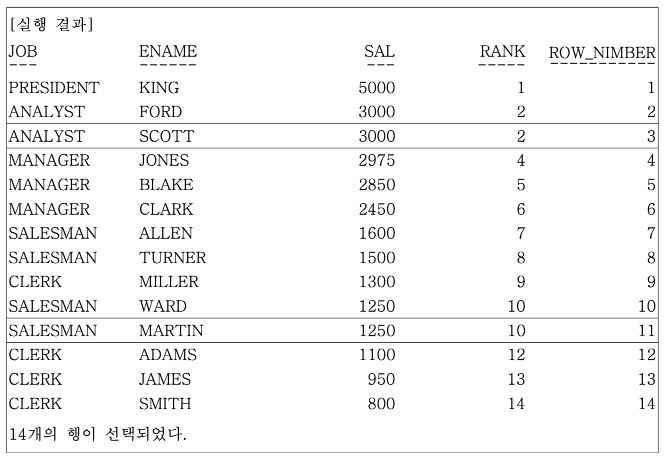
FORD와 SCOTT, WARD와 MARTIN은 동일한 SALARY이므로 RANK는 같은 순위를 부여했지만, ROW_NUMBER의 경우 동일한 순위를 배제하기 위해 유니크한 순위를 정한다.
위 경우는 같은 SALARY에서는 어떤 순서가 정해질지 알 수 없다. (Oracle의 경우 rowid가 적은 행이 먼저 나온다)
이 부분은 데이터베이스 별로 틀린 결과가 나올 수 있으므로, 만일 동일 값에 대한 순거까지 관리하고 싶으면 ROW_NUMBER() OVER (ORDER BY SAL DESC, ENAME) 같이 ORDER BY 절을 이용해 추가적인 정렬 기준을 정의해야 한다.
3. 일반 집계 함수
가. SUM 함수
SUM 함수를 이용해 파티션별 윈도우의 합을 구할 수 있다.
-- 사원들의 급여와 같은 매니저를 두고 있는 사원들의 SALARY 합을 구한다.
SELECT
MGR,
ENAME,
SAL,
SUM(SAL)
OVER(PARTITION BY MGR) MGR_SUM
FROM EMP;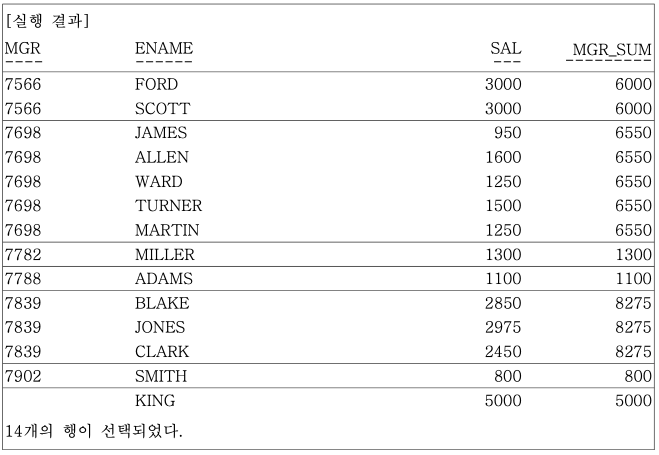
-- OVER 절 내에 ORDER BY 절을 추가해 파티션 내 데이터를 정렬하고
-- 이전 SALARY 데이터까지의 누적값을 출력한다.
-- (SQL Server의 경우 집계 함수의 경우 OVER 절 내의 ORDER BY 절을 지원하지 않는다)
SELECT
MGR,
ENAME,
SAL,
SUM(SAL)
OVER(
PARTITION BY MGR
ORDER BY SAL
RANGE UNBOUNDED PRECEDING) MGR_SUM
FROM EMP;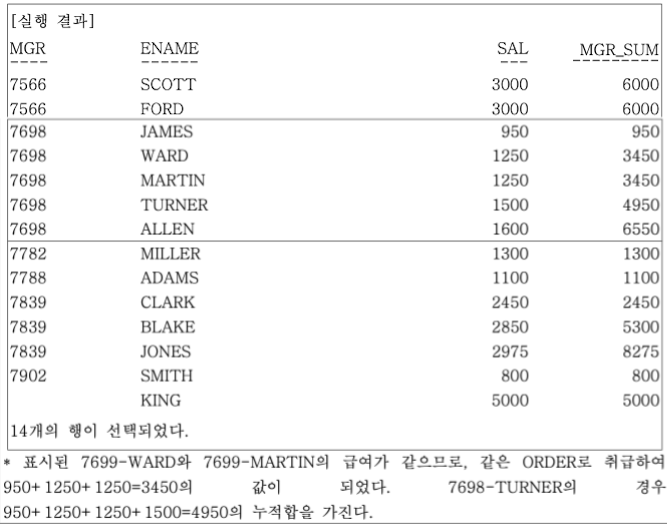
RANGE
정렬된 값에 따라 범위를 정의합니다. 같은 값이 있는 행들은 동일한 범위로 취급됩니다.UNBOUNDED PRECEDING
현재 행부터 파티션의 처음 행까지를 범위로 지정합니다. 다시 말해, 현재 행을 포함한 모든 이전 행들을 선택합니다.그러므로 이 쿼리에서 RANGE UNBOUNDED PRECEDING는 MGR로 분할된 각 파티션 내에서, 현재 행의 SAL 값과 동일하거나 작은 모든 이전 행들의 SAL 값을 합산하여 MGR_SUM 열에 저장합니다.
나. MAX 함수
MAX 함수를 이용해 파티션별 윈도우의 최대값을 구할 수 있다.
-- 사원들의 급여와 같은 매니저를 두고 있는 사원들의 SALARY 중 최대값을 같이 구한다.
SELECT
MGR,
ENAME,
SAL,
MAX(SAL)
OVER(PARTITION BY MGR) MGR_MAX
FROM EMP;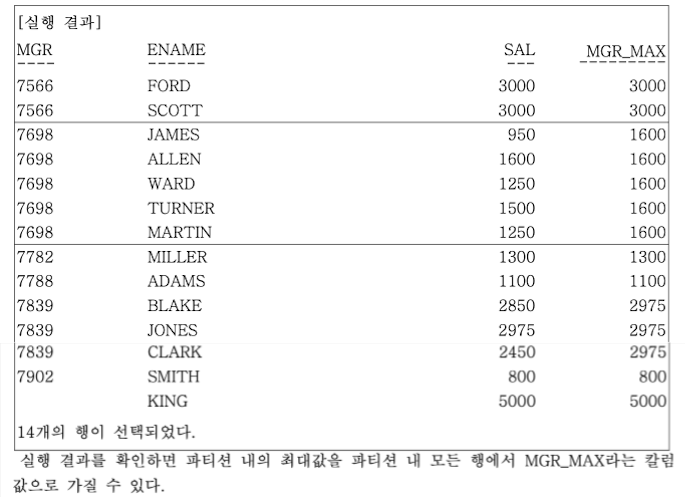
-- INLINE VIEW를 이용해 파티션별 최대값을 가진 행만 추출할 수도 있다.
SELECT
MGR,
ENAME,
SAL,
FROM (
SELECT
MGR,
ENAME,
SAL,
MAX(SAL)
OVER (PARTITION BY MGR) IV_MAX_SAL
FROM EMP)
WHERE SAL= IV_MAX_SAL
);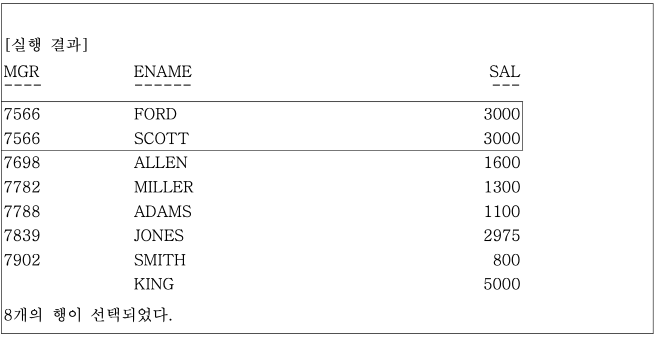
실행 결과를 보면 MGR 7566의 SCOTT, FORD는 같은 최대값을 가지므로, WHERE SAL = IV_MAX_SAL 조건에 의해 두건 모두 추출되었다.
다. MIN 함수
MIN 함수를 이용해 파티션별 윈도우의 최소값을 구할 수 있다.
-- 사원들의 급여와 같은 매니저를 두고 있는 사원들을
-- 입사일자를 기준으로 정렬하고, SALARY 최소값을 같이 구한다.
SELECT
MGR,
ENAME,
HIREDATE,
SAL,
MIN(SAL)
OVER (
PARTITION BY MGR
ORDER BY HIREDATE) MGR_MIN
FROM EMP;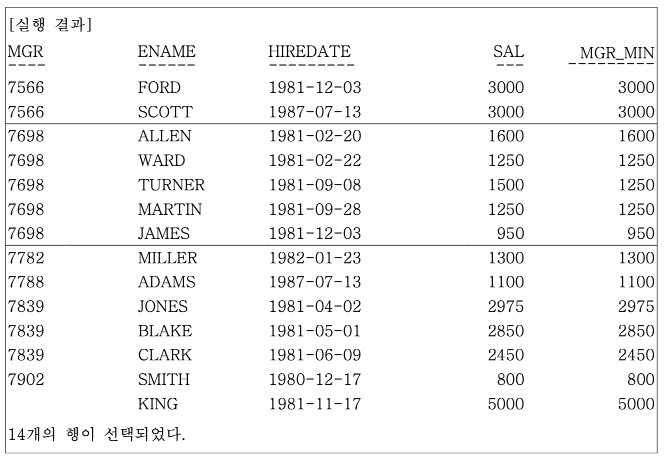
라. AVG 함수
AVG 함수와 파티션별 ROWS 윈도우를 이용해 원하는 조건에 맞는 데이터에 대한 통계값을 구할 수 있다.
-- EMP 테이블에서 같은 매니저를 두고 있는 사원들의
-- 평균 SALARY를 구하는데, 조건이 같은 매니저 내에서
-- 자기 바로 앞의 사번과 바로 뒤의 사번인 직원만을 대상으로 한다.
SELECT
MGR,
ENAME,
HIREDATE,
SAL,
ROUND(
AVG(SAL)
OVER(
PARITION BY MGR
ORDER BY HIREDATE
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)) MGR_AVG
FROM EMP;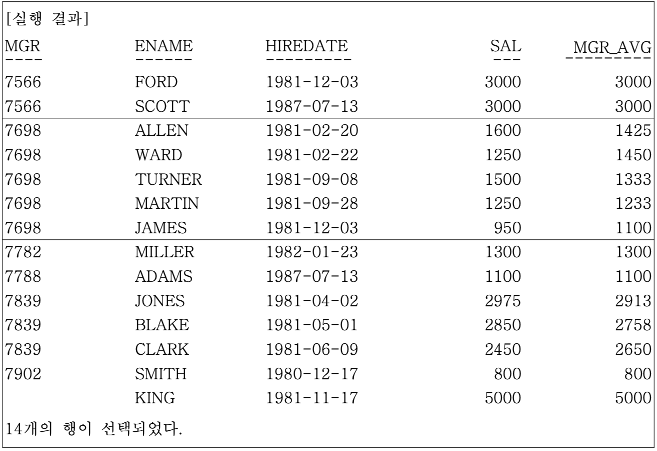
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
ROWS
윈도우 내에서 행들을 어떻게 처리할지 정의합니다. ROWS 키워드를 사용하면 정확한 행의 수를 기반으로 윈도우를 정의하게 됩니다.
BETWEEN 1 PRECEDING
현재 행에서 바로 앞에 있는 하나의 행을 포함합니다. 즉, 현재 행을 기준으로 이전 행 하나를 윈도우에 추가합니다.
AND 1 FOLLOWING
현재 행에서 바로 뒤에 있는 하나의 행을 포함합니다. 즉, 현재 행을 기준으로 다음 행 하나를 윈도우에 추가합니다.
따라서, ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING의 전체 의미는 다음과 같습니다
- 현재 행을 기준으로, 바로 앞에 있는 행 하나와 바로 뒤에 있는 행 하나를 포함한 총 3개의 연속된 행을 대상으로 연산을 수행합니다.
- 현재 행이 파티션의 첫 번째 행이라면 이전 행이 없으므로, 현재 행과 다음 행만 대상으로 합니다.
- 현재 행이 파티션의 마지막 행이라면 다음 행이 없으므로, 이전 행과 현재 행만 대상으로 합니다.
실행 결과에서 ALLEN의 경우 파티션 내에서 첫 번째 데이터이므로 앞의 한 건은 평균값 집계 대상이 없다. 결과적으로 평균값 집계 대상은 본인의 데이터와 뒤의 한 건으로 평균값을 구한다. (1600 + 1250) / 2 = 1425의 값을 가진다.
TURNER의 경우 앞의 한건과, 본인의 데이터와, 뒤의 한 건으로 평균값을 구한다. (1250 + 1500 + 1250) / 3 = 1333의 값을 가진다.
JAMES의 경우 파티션 내에서 마지막 데이터이므로 뒤의 한 건을 제외한, 앞의 한 건과 본인의 데이터를 가지고 평균값을 구한다. (1250 + 950) / 2 = 1100의 값을 가진다.
마. COUNT 함수
COUNT 함수와 파티션별 ROWS 윈도우를 이용해 원하는 조건에 맞는 데이터에 대한 통계값을 구할 수 있다.
-- 사원들을 급여 기준으로 정렬하고,
-- 본인의 급여보다 50 이하가 적거나 150 이하로 많은 급여를 받는 인원수를 출력하라.
SELECT
ENAME,
SAL,
COUNT(*)
OVER(
ORDER BY SAL
RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) SIM_CNT
FROM EMP;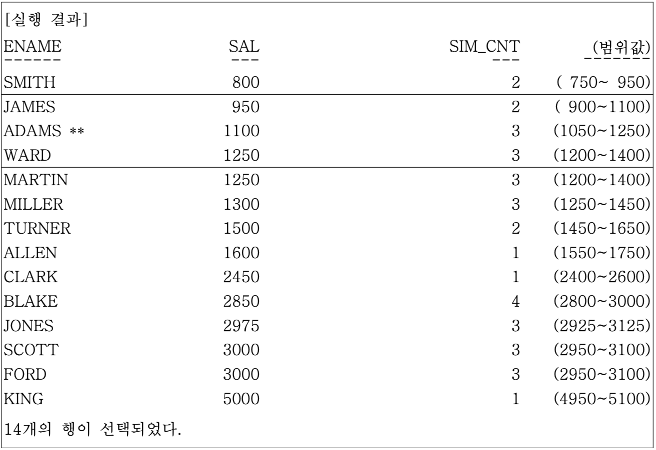
ROWS 그리고 RANGE
- RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING:
RANGE는 현재 행의 값(SAL 칼럼을 기준으로)을 기반으로 윈도우를 정의합니다.
50 PRECEDING는 현재 행의 SAL 값보다 50 이상 작은 행을 포함합니다.
150 FOLLOWING은 현재 행의 SAL 값보다 150 이상 큰 행을 포함합니다.
따라서, 현재 행의 SAL 값을 기준으로 이 값보다 50 이상 작거나 150 이상 큰 모든 행들이 윈도우에 포함됩니다.
- ROWS BETWEEN 50 PRECEDING AND 150 FOLLOWING:
ROWS를 사용하면, 행의 값이 아닌 행의 위치를 기준으로 윈도우를 정의합니다.
따라서 50 PRECEDING는 현재 행보다 50행 앞의 행부터 현재 행까지를 포함하고, 150 FOLLOWING은 현재 행에서 150행 뒤의 행까지를 포함합니다.
위 SQL 문장은 파티션이 지정되지 않았으므로 모든 건수를 대상으로 -50 ~ +150 기준에 맞는지 검사하게 된다. ORDER BY SAL로 정렬이 되어 있으므로 비교 연산이 쉬워진다. **표시된 ADAMS의 경우 자기가 가지고 있는 SALARY 1100을 기준으로 -50에서 + 150까지 값을 가진 1050에서 1250까지의 값을 가진 JAMES(950), ADAMS(1100), WARD(1250) 3명의 데이터 건수를 구할 수 있다.
4. 그룹 내 행 순서 함수
가. FIRST_VALUE 함수
FIRST_VALUE 함수를 이용해 파티션별 윈도우에서 가장 먼저 나온 값을 구한다. SQL Server에서는 지원하지 않는 함수이다. MIN 함수를 활용하여 같은 결과를 얻을 수도 있다.
-- 부서별 직원들을 연봉이 높은 순서부터 정렬하고,
-- 파티션 내에서 가장 먼저 나온 값을 출력한다.
SELECT
DEPTNO,
ENAME,
SAL,
FIRST_VALUE(ENAME)
OVER(
PARTITION BY DEPTNO
ORDER BY SAL DESC
ROWS UNBOUNDED PRECEDING) DEPT_RICH
FROM EMP;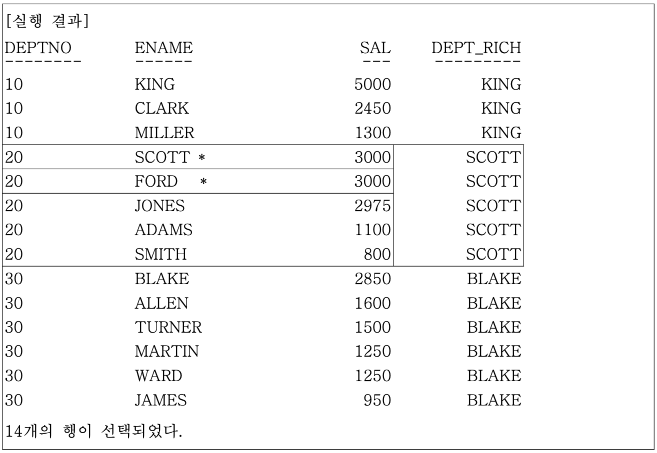
실행 결과를 보면 같은 부서 내에 최고 급여를 받는 사람이 둘 있는 경우, 즉, * 표시가 있는 부서번호 20의 SCOTT과 FORD 중에서 어느 사람이 최고 급여자로 선택될지는 위의 SQL 문만 가지고는 판단할 수 없다.
FIRST_VALUE는 다른 함수와 달리 공동 등수를 인정하지 않고 처음 나온 행만을 처리한다.
위처럼 공동 등수가 있을 경우에 의도적으로 세부 항목을 정렬하고 싶다면 별도의 정렬 조건을 가진 INLINE VIEW를 사용하거나, OVER () 내의 ORDER BY 절에 칼럼을 추가해야 한다.
-- 같은 값을 가진 FIRST)VALUE를 처리하기 위해 ORDER BY 정렬 조건을 추가한다.
SELECT
DEPTNO,
ENAME,
SAL,
FIRST_VALUE(ENAME)
OVER(
PARTITION BY DEPTNO
ORDER BY SAL DESC, ENAME ASC
ROWS UNBOUNDED PRECEDING) DEPT_RICH
FROM EMP;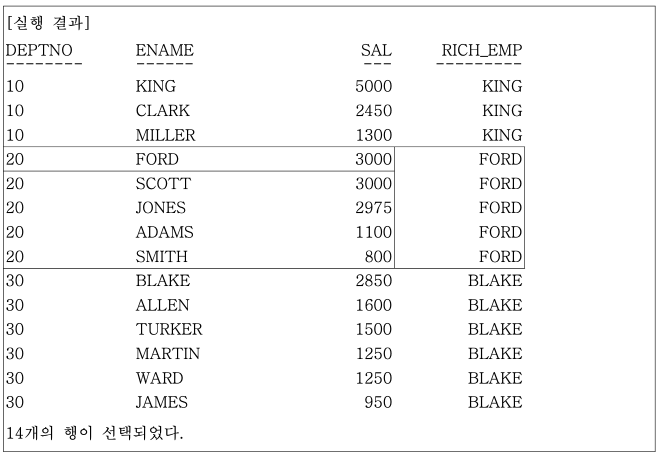
SQL에서 같은 부서 내에 최고 급여를 받는 사람이 둘 있는 경우를 대비해서 이름을 두 번째 정렬 조건으로 추가한다. 실행 결과를 확인하면 부서번호 20의 최고 급여자가 이전의 SCOTT 값에서 ASCII 코드가 적은 값인 FORD로 변경 된 것을 확인할 수 있다.
나. LAST_VALUE 함수
LAST_VALUE 함수를 이용해 파티션별 윈도우에서 가장 나중에 나온 값을 구한다. SQL Server에서는 지원하지 않는 함수이다. MAX 함수를 활용하여 같은 결과를 얻을 수도 있다.
-- 부서별 직원들을 연봉이 높은 순서부터 정렬하고,
-- 파티션 내에서 가장 마지막에 나온 값을 출력한다.
SELECT
DEPTNO,
ENAME,
SAL,
LAST_VALUE(ENAME)
OVER(
PARTITION BY DEPTNO
ORDER BY SAL DESC
ROWS
BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) DEPT_RICH
FROM EMP;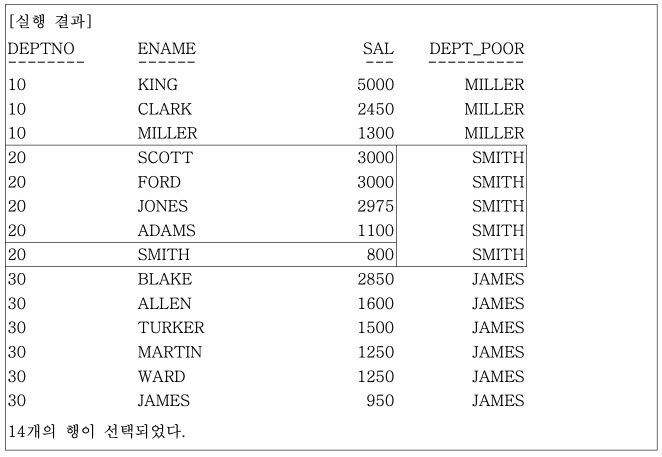
실행 결과에서 LAST_VALUE는 다른 함수와 달리 공동 등수를 인정하지 않고 가장 나중에 나온 행만을 처리한다. 만일 공동 등수가 있을 경우 의도적으로 정렬하고 싶다면 별도의 정렬 조건을 가진 INLINE VIEW를 사용하거나, OVER () 내의 ORDER BY 조건에 칼럼을 추가해야 한다.
다. LAG 함수
LAG 함수를 이용해 파티션별 윈도우에서 이전 몇 번째 행의 값을 가져올 수 있다. SQL Server에서는 지원하지 않는 함수이다.
LAG 함수는 현재 행에 대한 지정된 물리적 오프셋 이전의 행에서 데이터를 액세스합니다.
-- 직원들을 입사일자가 빠른 기준으로 정렬을 하고,
-- 본인보다 입사일자가 한 명 앞선 사원의 급여를 본인의 급여와 함께 출력한다.
SELECT
ENAME,
HIREDATE,
SAL,
LAG(SAL)
OVER(ORDER BY HIREDATE) PREV_SAL
FROM EMP
WHERE JOB = 'SALESMAN';
LAG 함수는 3개의 ARGUMENTS 까지 사용할 수 있는데, 두 번째 인자는 몇 번째 앞의 행을 가져올지 결정하는 것이고 (DEFAULT 1), 세 번째 인자는 예를 들어 파티션의 첫 번째 행의 경우 가져올 데이터가 없어 NULL 값이 들어오는데 이 경우 다른 값으로 바꾸어 줄 수 있다. 결과적으로 NVL이나 ISNULL 기능과 같다.
SELECT
ENAME,
HIREDATE,
SAL,
LAG(SAL, 2, 0)
OVER(ORDER BY HIREDATE) PREV_SAL
FROM EMP
WHERE JOB = 'SALESMAN';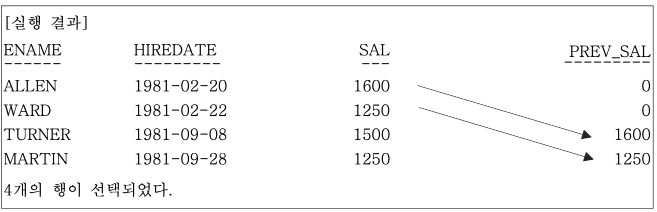
라. LEAD 함수
LEAD 함수를 이용해 파티션별 윈도우에서 이후 몇 번째 행의 값을 가져올 수 있다. 참고로 SQL Server에서는 지원하지 않는 함수이다.
-- 직원들을 입사일자가 빠른 기준으로 정렬을 하고,
-- 바로 다음에 입사한 인력의 입사 일자를 함께 출력한다.
SELECT
ENAME,
HIREDATE,
LEAD(HIREDATE)
OVER(ORDER BY HIREDATE) NEXTDATE
FROM EMP;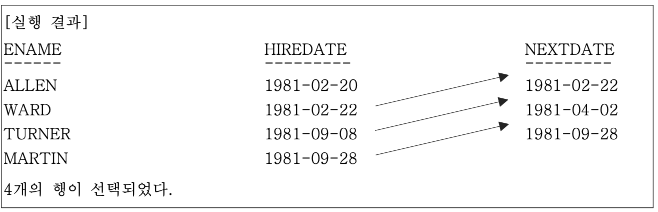
LEAD 함수는 3개의 ARGUMENTS 까지 사용할 수 있는데, 두 번째 인자는 몇 번째 앞의 행을 가져올지 결정하는 것이고 (DEFAULT 1), 세 번째 인자는 예를 들어 파티션의 마지막 행의 경우 가져올 데이터가 없어 NULL 값이 들어오는데 이 경우 다른 값으로 바꾸어 줄 수 있다. 결과적으로 NVL이나 ISNULL 기능과 같다.
5. 그룹 내 비율 함수
가. RATIO_TO_REPORT 함수
RATIO_TO_REPORT 함수를 이용해 파티션 내 전체 SUM(칼럼)값에 대한 행별 칼럼 값의 백분율을 소수점으로 구할 수 있다. 결과 값은 >0 &<= 1 의 범위를 가진다. 그리고 개별 RATIO의 합을 구하면 1이 된다. SQL Server에서는 지원하지 않는 함수이다.
JOB이 SALESMAN인 사원들을 대상으로 전체 급여에서 본인이 차지하는 비율을 출력한다.
SELECT
ENAME,
SAL
ROUND(
RATIO_TO_REPORT(SAL) OVER(),
2) R_R
FROM EMP
WHERE JOB = 'SALESMAN';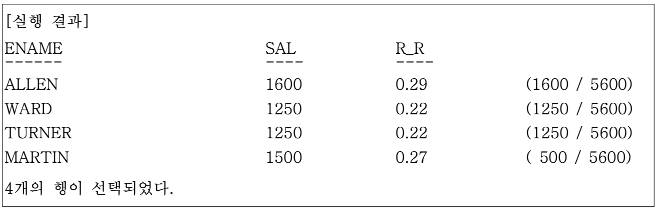
실행 결과에서 전체 값은 1650 + 1250 + 1250 + 1500 = 5600이 되고, RAIO_TO_REPORT 함수 연산의 분모로 사용된다. 그리고 개별 RATIO의 전체 합을 구하면 1이 되는 것을 확인할 수 있다.
0.29 + 0.22 + 0.22 + 0.27 =1
나. PERCENT_RANK 함수
PERCENT_RANK 함수를 이용해 파티션별 윈도우에서 제일 먼저 나오는 것을 0으로, 제일 늦게 나오는 것을 1로 하여, 값이 아닌 행의 순서별 백분율을 구한다. 결과 값은 >= 0 &<=1 의 범위를 가진다. 참고로 SQL Server에서는 지원하지 않는 함수이다.
-- 같은 부서 소속 사원들의 집합에서
-- 본인의 급여가 순서상 몇 번째 위치쯤에 있는지 0과 1 사이의 값으로 출력한다.
SELECT
DEPTNO,
ENAME,
SAL,
PERCENT_RANK()
OVER(
PARTITION BY DEPTNO
ORDER BY SAL DESC) P_R
FROM EMP;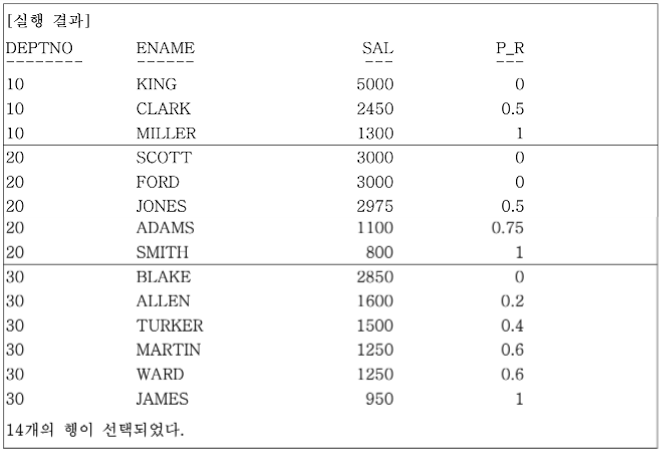
SCOTT, FORD와 WARD, MARTIN의 경우 ORDER BY SAL DESC 구문에 의해 급여가 같으므로 같은 ORDER로 취급한다.
다. CUME_DIST 함수
CUME_DIST 함수를 이용해 파티션별 윈도우의 전체건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율을 구한다. 결과 값은 >0 &<= 1 의 범위를 가진다. 참고로 SQL Server에서는 지원하지 않는 함수이다.
-- 같은 부서 소속 사원들의 집합에서 본인의 급여가
-- 누적 순서상 몇 번째 위치쯤에 있는지 0과 1 사이의 값으로 출력한다.
SELECT
DEPTNO,
ENAME,
SAL,
CUME_DIST()
OVER(
PARTITION BY DEPTNO
ORDER BY SAL DESC) CUME_DIST
FROM EMP;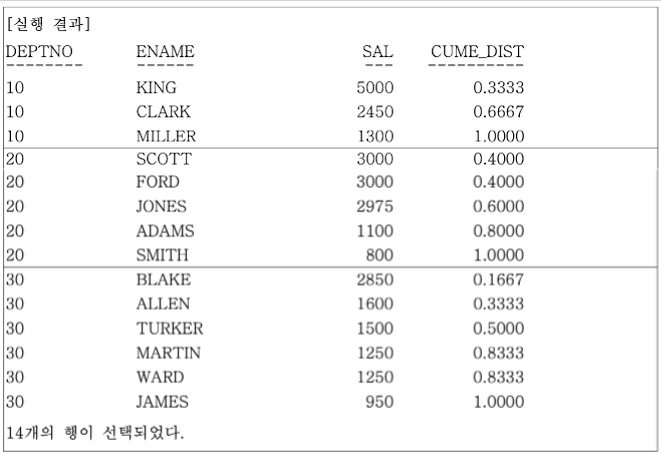
SCOTT, FORD와 WARD, MARTIN의 경우 ORDER BY SAL에 의해 SAL 이 같으므로 같은 ORDER로 취급한다. 다른 WINDOW 함수의 경우 동일 순서면 앞 행의 함수 결과 값을 따르는데, CUME_DIST의 경우는 동일 순서면 뒤 행의 함수 결과값을 기준으로 한다.
라. NTILE 함수
NTILE 함수를 이용해 파티션별 전체 건수를 ARGUMENT 값으로 N 등분한 결과를 구할 수 있다.
-- 전체 사원을 급여가 높은 순서로 정렬하고,
-- 급여를 기준으로 4개의 그룹으로 분류한다.
SELECT
DEPTNO,
ENAME,
SAL,
NTILE(4)
OVER(ORDER BY SAL DESC) QUAR_TILE
FROM EMP;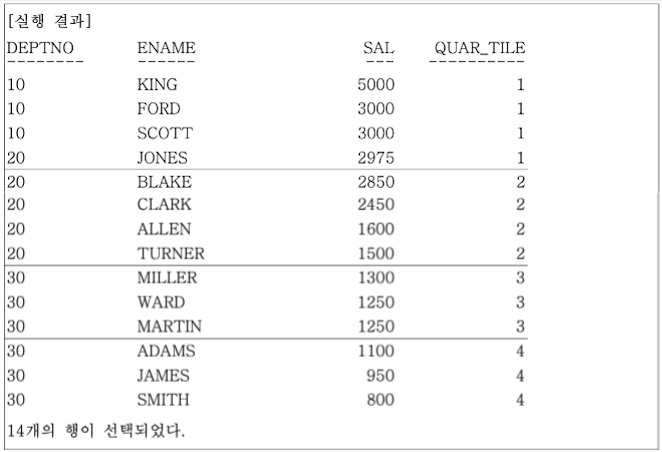
위 예제에서 NTILE(4)의 의미는 14명의 팀원을 4개 조로 나눈다는 의미이다. 전체 14명을 4개의 집합으로 나누면 몫이 3명, 나머지가 2명이 된다. 나머지 두 명은 앞의 조부터 할당한다.
즉, 4명(몫 3명 + 나머지 1명) + 4명(몫 3명 + 나머지 1명) + 3명 + 3명으로 조를 나누게 된다.
