구조
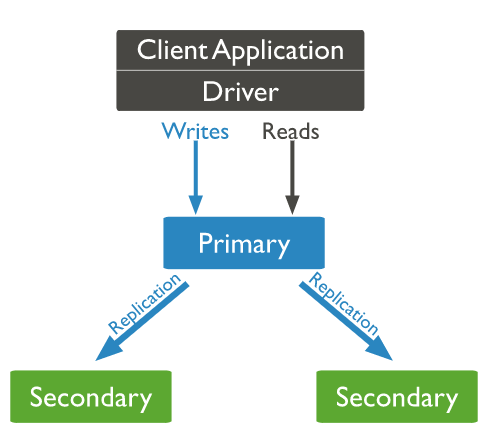
1. Primary
- 클라이언트에서 DB로 읽기 및 쓰기 작업을 한다.
2. Secondary
- 프라이머리로부터 데이터를 동기화 한다.
3. Arbiter
- 데이터를 동기화하지는 않으며 레플리카 셋의 복구를 돕는 역할을 한다.
동작 과정
- Slave → Master: QueryOption_AwaitData 질의 요청 옵션으로 자신의 optime(마지막 oplog 수행시간)보다 큰 oplog를 달라고 요청(5초 주기)
- Master → Slave :쓰기 연산 발생 시, 즉시 데이터 응답/ 6초안에 미발생시 데이터 존재하지않는다는 응답
- Slave: 요구한 Oplog의 데이터가 존재하면 자신의 Oplog에 데이터를 저장하고 다시 1번 과정(Master Oplog에 질의) 반복
동기화 스레드
Master와 Slave 모두 동기화를 위한 스레드가 각각 한개씩 존재
1. Slave(능동적)
→ Master 연결 단절 → Oplog 동기화 불가 → 자신의 Oplog의 마지막 연산 시간을 저장하고 비우기 → 메모리에 보관된 모든 데이터를 Data Store에 저장 → 5초 이후에 다시 Mater와 연결 시도
2. Master(수동적)
→ 쓰기 연산에 집중. Slave가 요구하는 데이터만 전달
- Master가 수동적이기에 복제의 개수가 많아지지 않는 한 복제로 인한 성능이슈는 적음
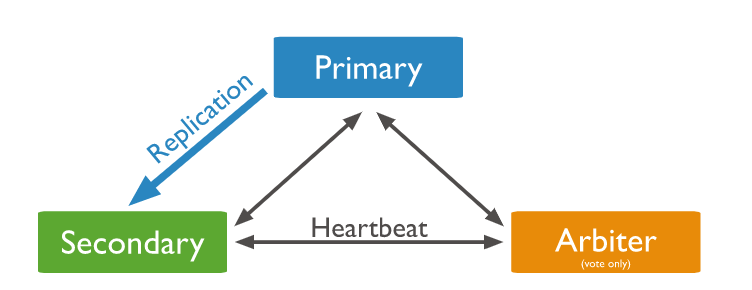
Master 선출
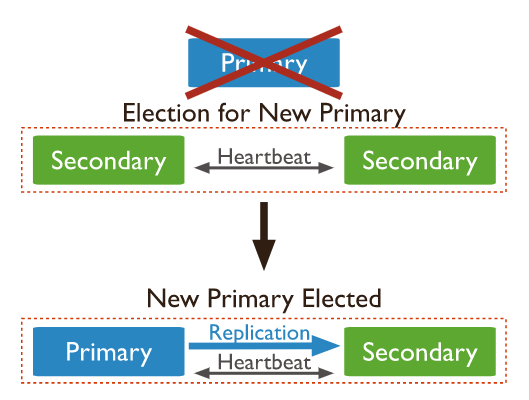
- Heartbeat를 통해 자신을 제외한 다른 노드들이 살아있는지 확인
- Heartbeat를 통한 서버 상태코드
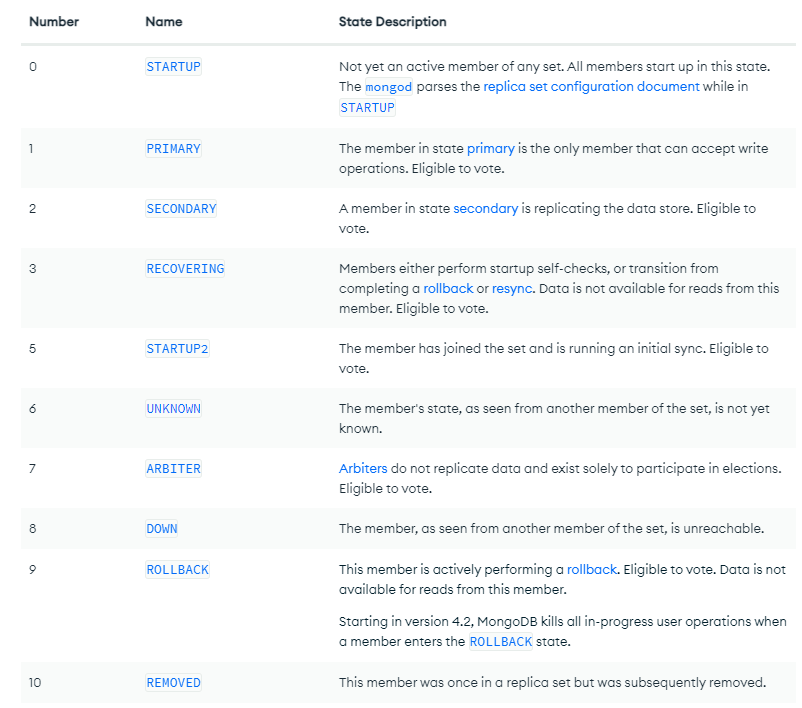
https://www.mongodb.com/docs/v4.4/reference/replica-states/
- 요소
- priority
우선순위, 0이 아닌 노드가 Master로 선출 가능
→ Master에 가중치 - votes
총 vote보다 과반수가 되어야 Master 선출
→ 가장 중요한 노드가 죽었을 때 ReadOnly로 동작
- 과정
- 각 노드가 자신의 Master 자격 확인
- Heartbeat 과반수, priority > 0, 노드들의 가장 최신 optime에서 10초 이내
- 자신이 Master 임을 알림
- 메세지를 받은 노드들이 Priority와 Optime을 비교하여 YES or NO 응답
- 거부권을 행사한 노드: YES를 과반수이상 받아야 Master로 선출
- 거부권 행사 안한 노드: 1분안에 모든 노드에게 거부권을 받야아함
- priority에 의해 가장 최신 정보가 없는 master가 선출된 경우 master보다 최신 데이터는 버림
→ 버려진 데이터는 관리자가 수동 복구할 수 있도록 BSON 파일로 저장됨
- MongoDB Replication Menual
https://www.mongodb.com/docs/manual/replication/

하이루!