코딩테스트
1.어린 동물 찾기
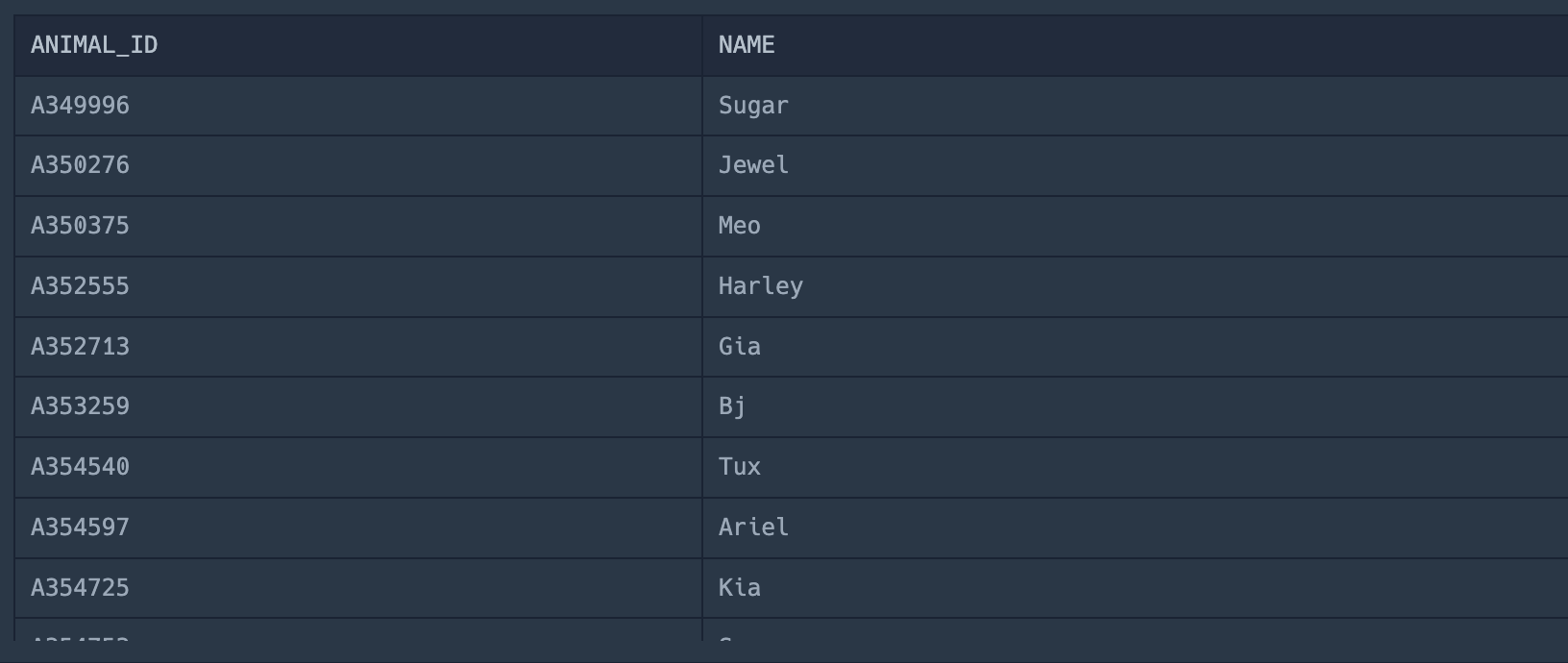
2.상위 n개 레코드

Table에서 맨 앞의 레코드 두개를 가져온다.ORDER BY랑 궁합이 잘맞는다.이렇게 작성하면 Column을 오름차순으로 정렬한 데이터 중 앞에서 두개를 가져온다.table에서 데이터를 한개만 가져오는데, 위에서 세번째 데이터를 가져오게 된다. (0이 시작이므로 2는
3.3월에 태어난 여성 회원 목록 출력하기

WHERE 절에서, 특정 달 또는 해, 날을 지정할 때는 AS필요 없이 바로 작성한다.여기서 %c는 달의 숫자가 한자리일 경우 한자리만 출력한다.1월이면 1,12월이면 12
4.재구매가 일어난 상품과 회원 리스트 구하기

GROUP BY : 데이터를 그룹으로 묶는다! 테이블에 저장된 컬럼의 값이 동일한 데이터를 그룹으로 묶어서 출력한다. SELECT에서 지정한 컬럼에서 중복된 값을 제외하고 하나씩만 출력한다. 만약 user 테이블에 name, gender 컬럼이 있을 때, gender
5.서울에 위치한 식당 목록 출력하기
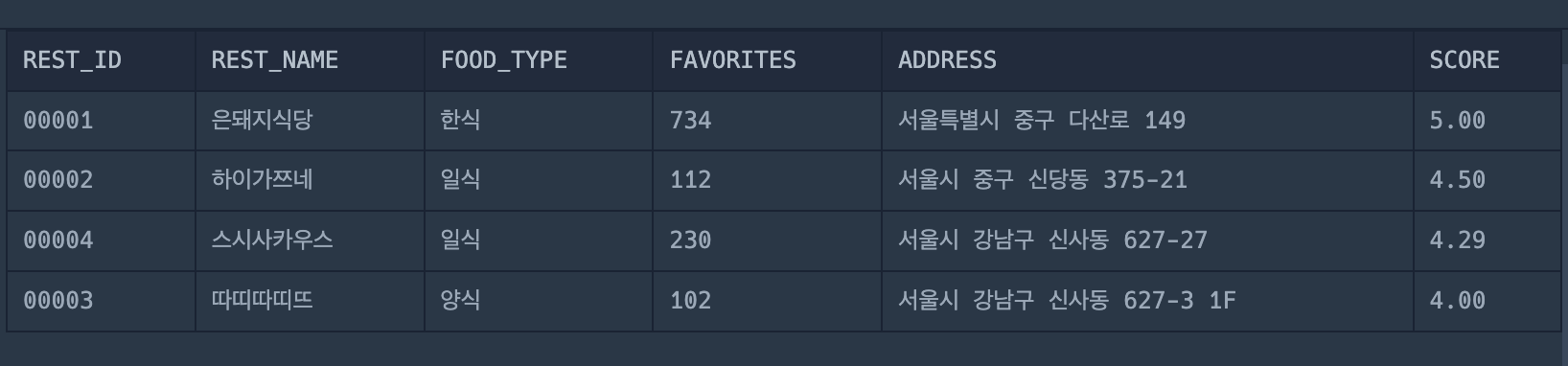
컬럼의 데이터 평균을 소수점 둘째자리까지 표현한다! (셋째자리에서 반올림한다.)
6.오프라인/온라인 판매 데이터 통합하기
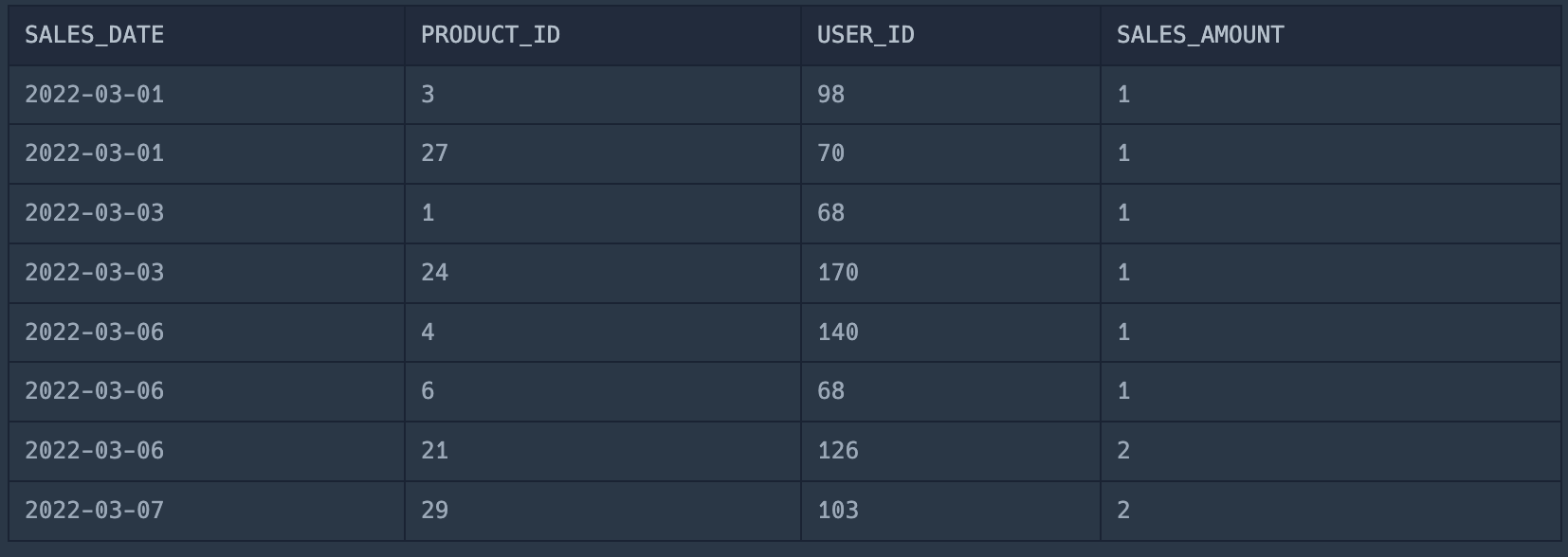
두 경우 모두 컬럼이 같아야한다. 그런데 이 문제의 경우, offline의 user id 컬럼이 없어 어려웠는데 offline_sales 테이블의 select 절에서 user id 항목에 NULL을 넣어주니 됐다.그런데 결과를 보니까 어차피 3월에 오프라인 데이터가 없
7.중복 제거하기

서브쿼리는 쿼리 안에 있는 또다른 select 쿼리다.이 예에서 SELECT \* FROM t1 ... 은 바깥 쿼리이고,(SELECT column1 FROM t2) 이게 서브쿼리다.서브쿼리 안에 서브쿼리 안에 서브쿼리가 계속 들어갈 수 있다!서브쿼리의 장점으로는1\.
8.성분으로 구분한 아이스크림 총 주문량

그룹화 된 각각의 데이터들의 합계를 구하고 싶다면 SELECT에서 SUM을 사용하자.만약, sum을 사용하지 않으면이렇게 출력이 되는데,전체 데이터는 아래와 같다.total_order 순으로 정렬을 했는데, sum을 사용하지 않았을경우 첫번째 데이터가 출력되지 않는 이
9.동명 동물 수 찾기

HAVING : 그룹으로 묶은 행의 조건을 설정한다.
10.가격대 별 상품 개수 구하기
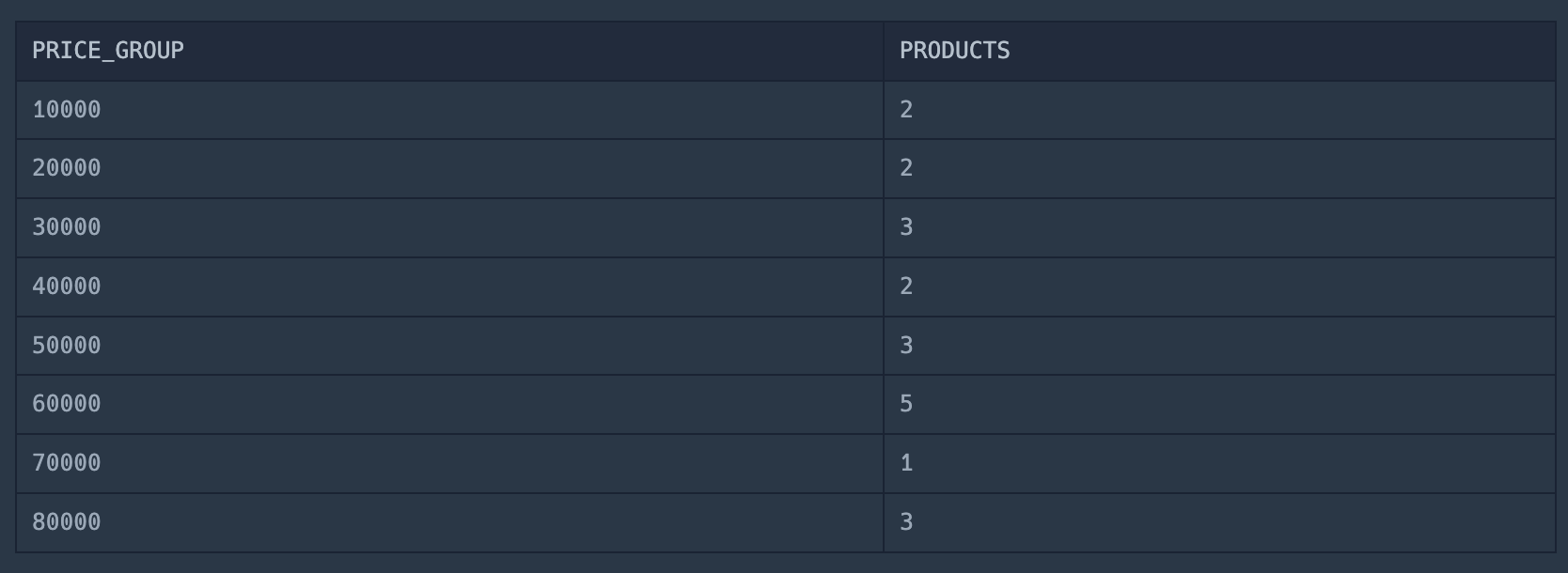
TRUNCATE : 값을 내림한다.