[12.07] 내일배움캠프[Spring] TIL-27
1.Spring의 동작원리 개념 학습하기
영속성 컨텍스트?
기존 코드로만 Jpa작성했을 때
Member minsook = new Member();
member.setId("abcd1234");
member.setUsername("민숙");
memberRepository.save(minsook);
memberRepository.find();
만약! 우리가 Jpa를 사용하지 않았다면??
Member minsook = new Member();
member.setId("abcd1234");
member.setUsername("민숙");
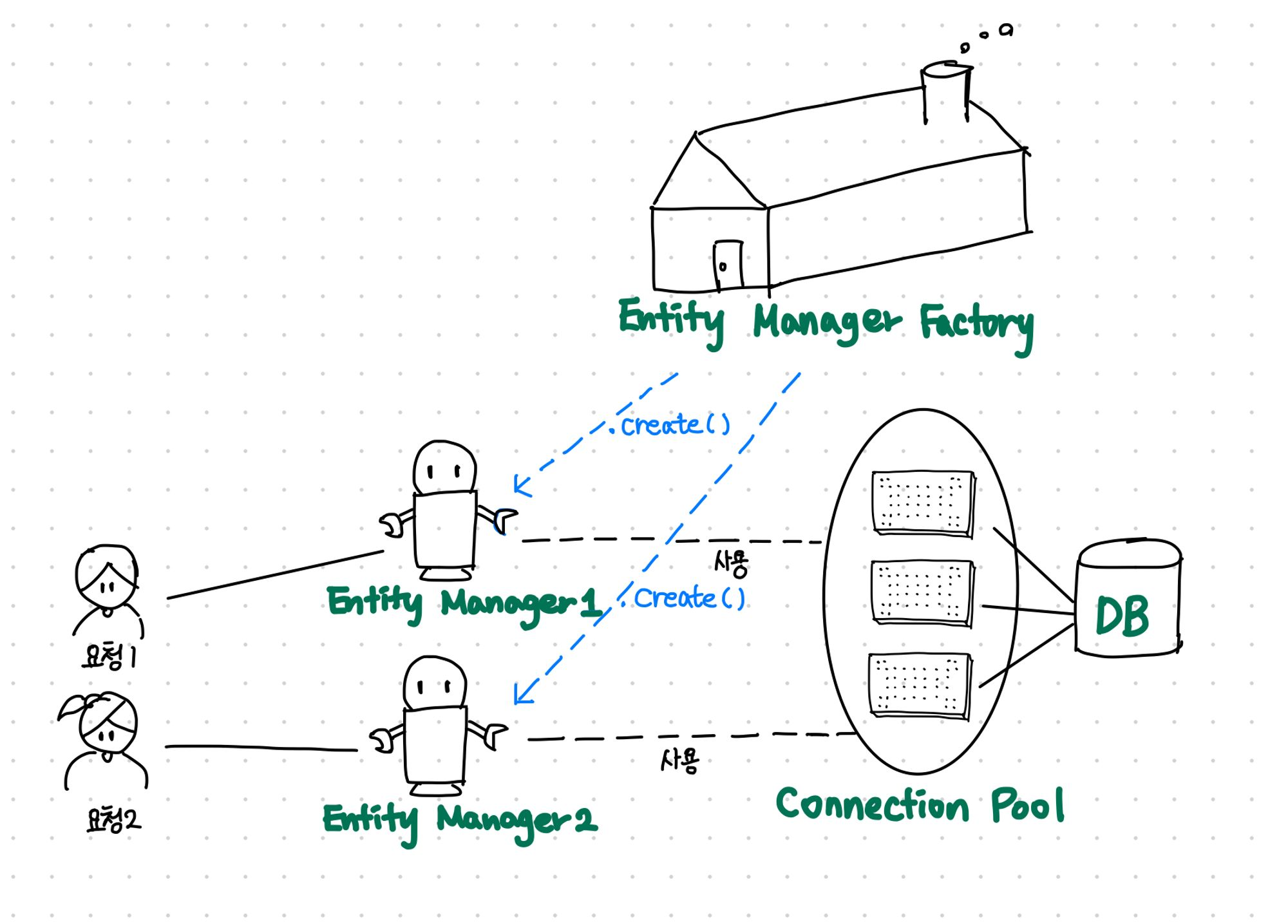
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa심화주차");
EntityManager em = emf.createEntityManager();
em.persist(minsook);
em.find(Member.class, 100L);
왜 EntityManager를 관리하는 하나의 EntityFactory는게 필요할까?
그래서 영속성 컨텍스트가 뭔데??
👉 엔티티를 영구 저장 하는 환경.
👉 DB에서 꺼내온 데이터 객체를 보관하는 역할.
👉 엔티티 매니저를 통해 엔티티를 조회하거나 저장할 때 엔티티를 보관하고 관리한다.
Jpa 엔티티의 상태
비영속( New ): 영속성 컨텍스트와 관계 없는 새로운 상태
👉 해당 객체의 데이터가 변경되거나 말거나 실제 DB데이터와는 관련없고, 그냥 java객체
Member minsook = new Member();
member.setId("minsook");
member.setUsername("민숙");
영속( Managed ) : 엔티티 매니저를 통해 엔티티가 영속성 컨텍스트에 저장되어 관리되고 있는 상태
👉 데이터의 생성, 변경등을 Jpa가 추적하면서 필요하면 DB에 반영한다.
em.persist(minsook);
준영속( Detached ) : 영속성 컨택스트에서 관리 되다가 분리된 상태
em.detach(minsook);
em.clear();
em.close();
삭제( Removed ) : 영속성 컨택스트에서 삭제된 상태
em.remove(minsook)
영속성 컨텍스트의 설계
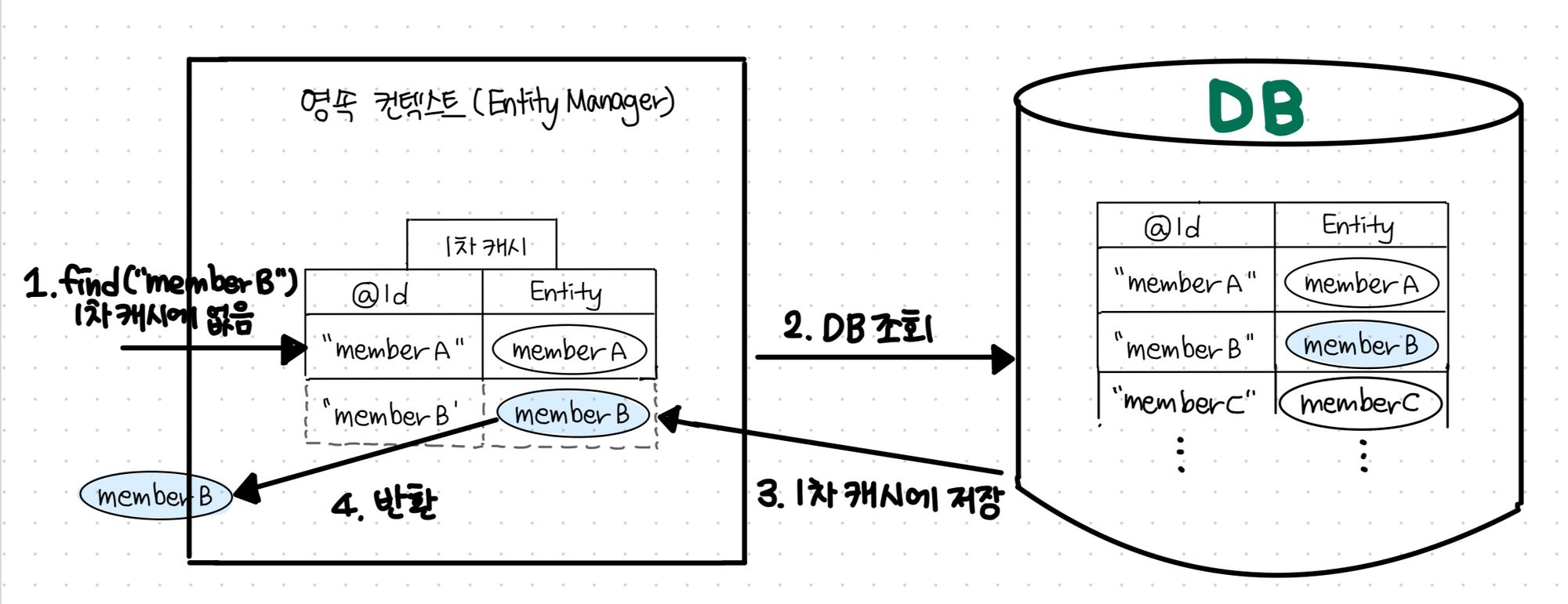
1차 캐시
- DB 이용하는 작업은 부하와 비용이 심한 작업 -> 줄이자 -> 조회할 일 -> 무자비한
Select * from SQL쿼리 내는 것 막자!! -> 그래서 내부에 1차 캐시라는 것을 둠.
- 1)
find("memberB")와 같은 로직이 있을 때 먼저 1차 캐시를 조회한다.
2) 있으면 해당 데이터를 반환한다.
3) 없으면 그 때 실제 DB로 Select * from의 쿼리를 보낸다.
4) 그리고 반환하기 전에 1차 캐시에 저장하고 반환한다.
다시 memberB를 find 하는 요청이 들어와도 굳이 DB를 갈 필요가 없어진다!!!
쓰기 지연 SQL 저장소
1차 캐시와 비슷한 맥락이다.memberA, memberB를 생성할 때 마다 DB를 다녀오는 것은 비효율적이다.- 굳이 여러번
DB를 방문하지 않도록 내부에 쓰기 지연 SQL 저장소를 뒀다.
- 1)
memberA,memebrB를 영속화 한다.
2) entityManager.commit()를 호출하면, 내부적으로 쓰기 지연 SQL 저장소에서 Flush() 발생
3) INSERT A, INSERT B와 같은 쓰기 전용 쿼리들이 DB로 흘러들어간다.
DirtyChecking을 통한 자동 수정

- Jpa는
1차캐시와 쓰기지연 SQL 저장소를 이용해서 변경과 수정을 감지해준다!!
- 1)
1차 캐시에는 DB의 엔티이의 정보만 저장하는 것이 아니다.
2) 해당 엔티티를 조회한 시험의 데이터의 정보를 같이 저장해둔다.
3) 엔티티객체와 조회 시점의 데이터가 다르다면 변경이 발생했다고 알 수 있다!
4) 해당 변경 부분을 반영할 수 있는 Update()쿼리를 작성해둔다.
데이터의 어플리케이션 단 동일성을 보장
Member member1 = em.find(Member.class, "minsook");
Member member2 = em.find(Member.class, "minsook");
System.out.println(member1 == member2) => true
엔티티 매핑 심화
기본 엔티티 매핑
@Entity
@Table (name="USER")
public class Member {
@Id
@Column (name = "user_id")
private String id;
private String username;
private Integer age;
@Enumerated (EnumType. STRING)
private RoleType userRole;
@Temporal (TemporalType. TIMESTAMP)
private Date createdDate;
@Temporal (TemporalType. TIMESTAMP)
private Date modifiedDate;
}
@Entity
1) 기본 생성자는 필수이다.
2) final class , enum, interface등에는 사용할 수 없음.
3) 저장할 필드라면 final사용하면 안된다!!
@Table
1) 엔티티와 매핑할 테이블의 이름, 생략하는 경우 매핑한 엔티티의 이름을 테이블 이름으로 사용
@Column
1) 객체 필드를 테이블 컬럼에 매핑하는데 사용한다.
2) 생략이 가능하다.
3) 속성들은 자주 쓸 일이 없고, 특정 속성은 무시무시한 effect가 있다는 것 만 알아두자.
@Enumerated
1) Java Enum을 테이블에서 사용한다고 생각하면 좋을 것 같다.
2) 일반적으로는 String 속성을 많이 사용한다.
연관 관계 관련 심화
@Entity
@Getter
@Setter
public class Member {
@Id
@Column(name = "member_id")
private String id;
private String username;
@ManyToOne
@JoinColumn(name="team_id")
private Team team;
public void setTeam(Team team) {
this.team = team;
}
}
@Entity
@Getter
@Setter
public class Team {
@Id
@Column (name = "TEAM_ID")
private String id;
private String name;
}
@ManyToOne : 이름 그대로 다대일(N:1)관계라는 매핑 정보
주요 속성 : optional(연관된 데이터가 있어야 매핑 가능), fetch,cascade@JoinColumn(name="food_id"): 외래 키를 매핑할 때 사용
다대일(N:1)에서 다(N)가 외래키를 가진다!!
@Getter
@Entity
@NoArgsConstructor
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String memberName;
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Orders> orders = new ArrayList<>();
public Member(String memberName) {
this.memberName = memberName;
}
}
@Getter
@Entity
@NoArgsConstructor
public class Orders {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "food_id")
private Food food;
@ManyToOne
@JoinColumn(name = "member_id")
private Member member;
public Orders(Food food, Member member) {
this.food = food;
this.member = member;
}
}
@Getter
@Entity
@NoArgsConstructor
public class Food {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String foodName;
@Column(nullable = false)
private int price;
@OneToMany(mappedBy = "food",fetch = FetchType.EAGER)
private List<Orders> orders = new ArrayList<>();
public Food(String foodName, int price) {
this.foodName = foodName;
this.price = price;
}
}
@OneToMany, mappedBy
객체는 연관 관계라는 것이 없다. -> 서로 다른 단방향으로 조회하는 로직 2개를 잘 묶어서 양 방향인 것 처럼 보이게 하는 것! ->
멤버객체에 주문객체의 주소값 / 주문 객체에는 멤버객체의 주소값을 가지고 있는 것!!
Member
| id | member_name | order |
|---|
| - | - | - |
| - | - | - |
| - | - | - |
Order
| id | food_id | member_id |
|---|
| - | - | - |
| - | - | - |
| - | - | - |
- 연관 관계 주인에 의해
mappedBy된다!! ( 정말 중요한 문장인 것 같음)
양방향 연관관계의 주의점
Order order = new Order ("order", "order”);
em.persist(order);
Order order2 = new Order (”order2", "order2”);
em.persist(order2);
Member member = new Member("member", ”member”);
member.getOrders().add(order);
member.getOrders().add(order2);
em.persist(member);
| memberId |
|---|
| order | null |
| order2 | null |
- 연관관계의 주인이 아닌 member.order에만 값을 저장했기 때문!!
순수 객체까지 고려한 양방향 연관 관계
order.setMember(member)
member.getOrders().add(order);
연관 관계 편의 메소드
private Order order;
public void setMember(Member member) {
this.member = member;
member.getOrders().add(this);
}
...
}
프록시

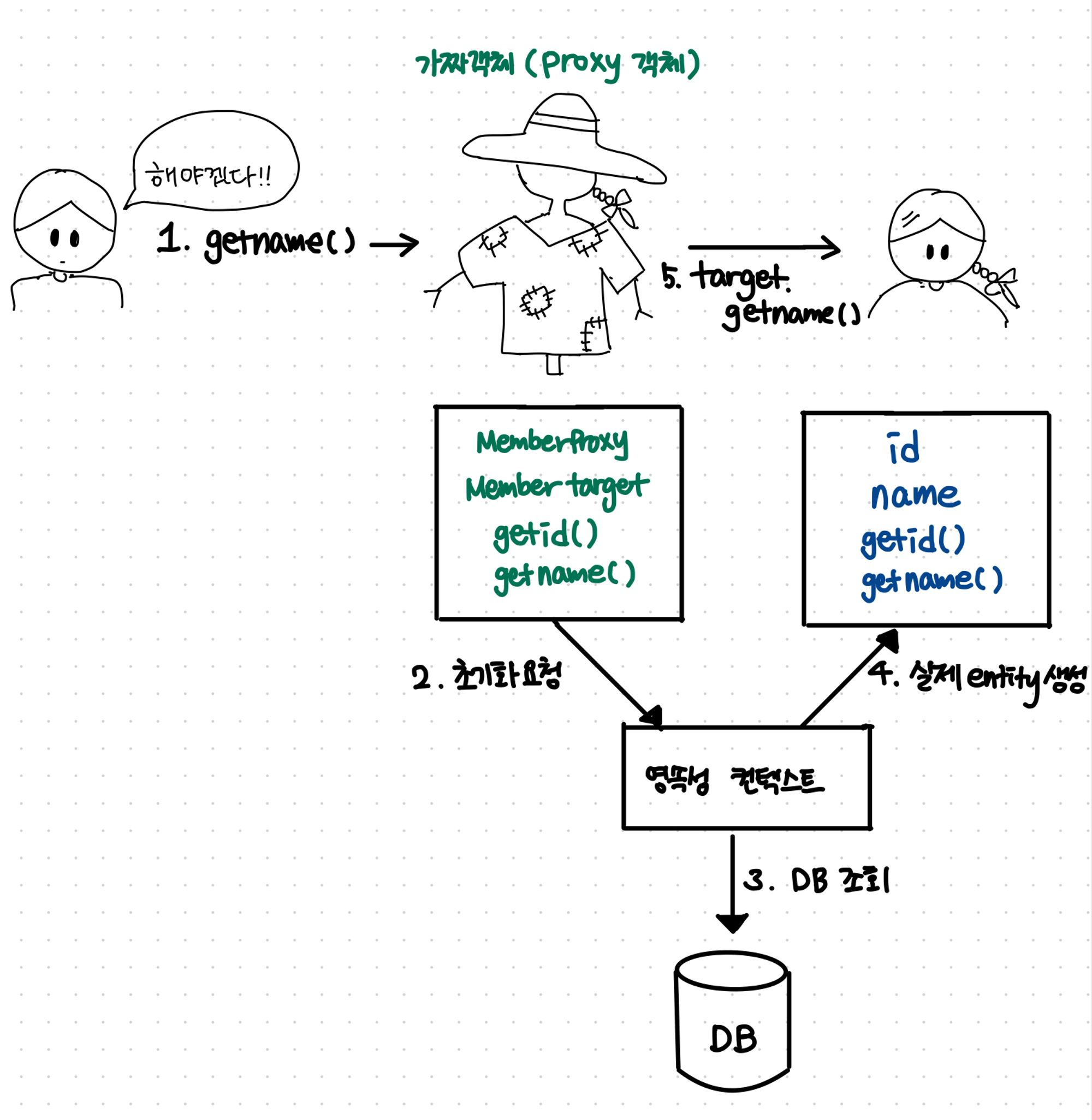
- 엔티티를 조회할 때 항상 연관된 엔티티가 모두 사용되는 것은 아니다.
따라서 Jpa는 굳이필요 없는 DB조회를 줄이면서 성능을 최적화 하기 때문에 이런 문제 해결을 위해 엔티티가 실제 사용될 때 까지 데이터베이스 조회를 지연하는 방법을 제공하는데 이것을 지연로딩이라한다.
- 지연 로딩 기능을 사용하려면 실제 엔티티 객체 대상에 데이터베이스 조회를 지연할 수 있는 가짜 객체가 필요한데, 이것을
프록시 객체라고 부른다.
지연로딩, 즉시로딩
즉시로딩: @ManyToOne(fetch=FetchType.EAGER )->엔티티 조회할 때 연관된 엔티티도 함께 조회지연로딩 : @ManyToOne(fetch=FetchType.LAZY ) ->연관된 엔티티를 실제 사용할 때 조회
2. Java - CodingTest
Level - 0
캐릭터 움직이기 문제
- 좌표(0,0)에서 시작
- up,down,left,right로 각각 이동 가능하며, 주어진 필드 값 ex) (3,3)이면 x는 -1 ~ 1 , y는 -1 ~ 1 이동가능.
- 여기서는 벽에 닿았을 때 조건 걸어주는 것을 망각했음...!
class Solution {
public int[] solution(String[] keyinput, int[] board) {
int width = board[0] / 2;
int height = board[1] / 2;
int x = 0;
int y = 0;
for(int i=0;i<keyinput.length;i++){
if(keyinput[i].equals("up")) {
if(y==height) continue;
y++;}
if(keyinput[i].equals("down")) {
if(y==-height) continue;
y--;}
if(keyinput[i].equals("right")) {
if(x==width) continue;
x++;}
if(keyinput[i].equals("left")) {
if(x==-width) continue;
x--;}
}
if (x > width) {
x = width;
} else if (x < -width) {
x = -width;
}
if (y > height) {
y = height;
} else if (y < -height) {
y = -height;
}
int[] answer = {x, y};
return answer;
}
}
영어가 싫어요
- 영어가 싫은 머쓱이는 영어로 표기되어있는 숫자를 수로 바꾸려고 합니다. 문자열 numbers가 매개변수로 주어질 때, numbers를 정수로 바꿔 return 하도록 solution 함수를 완성해 주세요.
| numbers | result |
|---|
| "onetwothreefourfivesixseveneightnine" | 23456789 |
| "onefourzerosixseven" | 14067 |
class Solution {
public Long solution(String numbers) {
char [] res = numbers.toCharArray();
StringBuffer str = new StringBuffer();
StringBuffer answer = new StringBuffer();
for(char i : res){
str.append(i);
if(str.toString().equals("zero")){
answer.append("0");
str.delete(0,str.length());
}
if (str.toString().equals("one")) {
answer.append("1");
str.delete(0,str.length());
}
if(str.toString().equals("two")){
answer.append("2");
str.delete(0,str.length());
}
if(str.toString().equals("three")){
answer.append("3");
str.delete(0,str.length());
}
if(str.toString().equals("four")){
answer.append("4");
str.delete(0,str.length());
}
if(str.toString().equals("five")){
answer.append("5");
str.delete(0,str.length());
}
if(str.toString().equals("six")){
answer.append("6");
str.delete(0,str.length());
}
if(str.toString().equals("seven")){
answer.append("7");
str.delete(0,str.length());
}
if(str.toString().equals("eight")){
answer.append("8");
str.delete(0,str.length());
}
if(str.toString().equals("nine")){
answer.append("9");
str.delete(0,str.length());
}
}
return Long.parseLong(answer.toString());
}
}
겹치는 선분의 길이( 개인적으로 어려웠음..!!! )
- 선분 3개가 평행하게 놓여 있습니다. 세 선분의 시작과 끝 좌표가 [[start, end], [start, end], [start, end]] 형태로 들어있는 2차원 배열 lines가 매개변수로 주어질 때, 두 개 이상의 선분이 겹치는 부분의 길이를 return 하도록 solution 함수를 완성해보세요.
lines가 [[0, 2], [-3, -1], [-2, 1]]일 때 그림으로 나타내면 다음과 같습니다.
| lines | result |
|---|
| [[0, 1], [2, 5], [3, 9]] | 2 |
| [-1, 1], [1, 3], [3, 9]] | 0 |
| [[0, 5], [3, 9], [1, 10]] | 8 |
import java.util.HashMap;
import java.util.Map;
class Solution {
public int solution(int[][] lines) {
Map<Integer, Integer> map = new HashMap<>();
for (int i=0; i<lines.length; i++) {
int min = Math.min(lines[i][0], lines[i][1]);
int max = Math.max(lines[i][0], lines[i][1]);
System.out.println(min+"//"+max);
for (int j=min; j<max; j++) {
map.put(j, map.getOrDefault(j, 0) + 1);
}
}
int answer = 0;
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
if (entry.getValue() >= 2) {
answer++;
}
}
return answer;
}
}
Level - 1
두 정수사이의 합
- 두 정수 a, b가 주어졌을 때 a와 b 사이에 속한 모든 정수의 합을 리턴하는 함수, solution을 완성하세요.
예를 들어 a = 3, b = 5인 경우, 3 + 4 + 5 = 12이므로 12를 리턴합니다.
import java.util.Arrays;
class Solution {
public long solution(int a, int b) {
long answer = 0;
int [] arr = new int[]{a,b};
Arrays.sort(arr);
for (int i = arr[0] ;i <=arr[1];i++){
answer+=i;
}
return answer;
}
}
3. 느낀점⭐
1) Jpa는 sql를 객체를 알아서 매핑해서 만들어 주는 만큼 어떻게 동작하는지 알아야 쓰기 쉬울 것 같다.
2) Jpa의 영속성 컨택스트와 JDBC의 개념이 바보 같이 헷갈렸었다 .
3) 지금 까지 이해한 것은 Jpa는 EntityManagerFactory에서 EntityManager를 바탕으로 영속성 컨택스트라는 영구적 엔티티 저장영역을 갖게되며, 그 안에는 효율등의 이유로 인한 1차 캐시, 쓰기지연 SQL저장소 등이 있다.
4) 저번 시간 어떻게 Service -> Repository를 거친 것이 아닌 Entity에 변경 만으로 DBUpdate()가 됐는지 의문이였는데 DirtyChecking 때문인 것을 깨달았다.