[11.14] 내일배움캠프[Spring] TIL-11
1. 파이썬 알고리즘 - 정렬
- 선택 정렬
👉 선택해서 정렬한다.
- 선택 정렬 예시
input = [4, 6, 2, 9, 1]
def selection_sort(array):
n = len(array)
for i in range(n-1):
min_index = i
for j in range(n -i):
if array[i+j] < array[min_index]:
min_index = i + j
array[i],array[min_index] = array[min_index],array[i]
return array
selection_sort(input)
print(input) # [1, 2, 4, 6, 9] 가 되어야 합니다!
- 삽입 정렬
👉 삽입 정렬은 필요할 때만 삽입을 하기 떄문에 효율적..!
다 비교하지 않는다.
👉 번호가 이미 배정되어 있는 곳에 새로운 숫자가 자리를 찾아 들어간다.
input = [4, 6, 2, 9, 1]
def insertion_sort(array):
n = len(array)
for i in range(1,n):
for j in range(i):
if array[i-j-1] > array[i-j]:
array[i-j-1],array[i-j] = array[i-j],array[i-j-1]
else:
# 이 부분은 이미 정렬이 다 되어있다면 break -> 시간 복잡도를 줄일 수 있다는 의미!!
break
return array
result = insertion_sort(input)
print(result) # [1, 2, 4, 6, 9] 가 되어야 합니다!
- 병합 정렬
👉 배열의 앞부분과 뒷부분을 정렬하여 합치는 것!
array_a = [1, 2, 3, 5]
array_b = [4, 6, 7, 8]
def merge(array1, array2):
merge_arr = []
array1_index = 0
array2_index = 0
while array1_index < len(array1) and array2_index < len(array2):
if array1[array1_index] < array2[array2_index]:
merge_arr.append(array1[array1_index])
array1_index+=1
else:
merge_arr.append(array2[array2_index])
array2_index+=1
if array1_index == len(array1):
while array2_index < len(array2):
merge_arr.append(array2[array2_index])
array2_index+=1
if array2_index == len(array2):
while array1_index < len(array1):
merge_arr.append(array1[array1_index])
array1_index += 1
print(merge_arr)
merge(array_a, array_b) # [1, 2, 3, 4, 5, 6, 7, 8] 가 되어야 합니다! --> 나머지 숫자 추가해주는 부분을 못했었음.. 하..
- 분할 정렬
👉 하나를 두가지로 쪼개서 비교하면서 정렬한다.
(재귀함수 사용하면 되겠다!!)
array = [5, 3, 2, 1, 6, 8, 7, 4]
def merge_sort(array):
if len(array) <= 1:
return array
mid = len(array)//2
left_sort = merge_sort(array[:mid])
right_sort = merge_sort(array[mid:])
return merge(left_sort,right_sort)
def merge(array1, array2):
result = []
array1_index = 0
array2_index = 0
while array1_index < len(array1) and array2_index < len(array2):
if array1[array1_index] < array2[array2_index]:
result.append(array1[array1_index])
array1_index += 1
else:
result.append(array2[array2_index])
array2_index += 1
if array1_index == len(array1):
while array2_index < len(array2):
result.append(array2[array2_index])
array2_index += 1
if array2_index == len(array2):
while array1_index < len(array1):
result.append(array1[array1_index])
array1_index += 1
return result
print(merge_sort(array)) # [1, 2, 3, 4, 5, 6, 7, 8] 가 되어야 합니다!2. 파이썬 알고리즘 - 자료구조
- Stack
👉 LIFO -> ex) 컴퓨터의 Ctrl + z
👉 push(data) : 맨위에 데이터를 넣겠다
👉 pop() : 맨위에 것 뽑기
👉 peek() : 맨위에 데이터를 그냥 보기
👉 isEmpty() : 비어있는지 아닌지 확인하기
👉 데이터의 삽입 삭제가 빈번하다 -> 링크드 리스트의 자료구조로 구현하면 되겠다!
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Stack:
def __init__(self):
self.head = None
# 기존에 [4]라는 데이터가 있었다면 그것을 옆으로 밀고 [new data] -> [4] 이런식의 연결
def push(self, value):
new_head = Node(value)
new_head.next = self.head
self.head = new_head
return
# pop 기능 구현
def pop(self):
if self.is_empty():
return "stack is Empty"
delete_head = self.head
self.head = self.head.next
return delete_head.data
def peek(self):
if self.is_empty():
return "stack is Empty"
return self.head.data
# isEmpty 기능 구현
def is_empty(self):
return self.head is None
stack = Stack()
stack.push(3)
print(stack.peek())
stack.push(4)
print(stack.peek())
print(stack.pop())
print(stack.peek())
print(stack.is_empty())
- Stack 자료구조를 활용한 레이저 탑 예제
👉 각 길이를 가진 탑이 배열 형태로 존재한다
👉 ex) top_heights = [6, 9, 5, 7, 4]
👉 4라는 높이의 탑이 레이저를 왼쪽으로 쏜다면 7이라는 높이의 탑에 막힌다. 그 때 index를 저장한다.
def get_receiver_top_orders(heights):
result = [0] * len(heights)
while heights:
height = heights.pop()
#range() 는 순차적이 아닌 역순으로도 가능하다는 것!! 알았음..
for idx in range(len(heights) - 1, 0, -1):
if heights[idx] > height:
result[len(heights)] = idx + 1
break
return result
print(get_receiver_top_orders(top_heights)) # [0, 0, 2, 2, 4] 가 반환되어야 한다!
- Queue
👉 FIFO 구조(선형구조)
👉 enqueue(data) : 맨 뒤에 데이터 추가하기
👉 dequeue() : 맨 뒤에 데이터 빼기
👉 peek() : 맨 위의 데이터 보기
👉 isEmpty() : 큐가 안에 비었는지 확인
👉 데이터 넣고 빼기 많이 하니까 링크드 리스트 자료구조가 좋겠다!
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Queue:
def __init__(self):
self.head = None
self.tail = None
def enqueue(self, value):
new_node = Node(value)
if self.is_empty():
self.head = new_node
self.tail = new_node
return
self.tail.next = new_node
self.tail = new_node
return
def dequeue(self):
if self.is_empty():
return "Queue is Empty"
delete_head = self.head
self.head = self.head.next
return delete_head.data
def peek(self):
if self.is_empty():
return "Queue is Empty"
return self.head.data
def is_empty(self):
return self.head is None
queue = Queue()
queue.enqueue(3)
print(queue.peek())
queue.enqueue(4)
print(queue.peek())
queue.enqueue(5)
queue.dequeue()
print(queue.peek())
- Hash
👉 키를 값에 매핑할 수 있는 , 연관 배열 추가에 사용되는 자료구조
👉 데이터의 검색과 저장이 아주 빠르게 진행된다 ( 중요 !! )
👉 ex) dict = {"fast":"빠른","slow":"느린"}
👉 찾는 데이터가 있는지 다 둘러보지 않고 키 값으로 바로 검색하기 때문에 엄청 빠름
- 파이썬의 Hash 함수
👉 임의의 길이를 갖는 메세지를 입력하여 고정된 길이의 해쉬값을 출력하는 함수
- 해쉬 함수의 원리
items = [None] * 8
hash("fast") % 8
6 >>> index
items[hash("fast")%8] = "빠른"
items[hash("slow")%8] = "느린"
items
[None, None, '느린', None, None, None, '빠른', None]
items[hash("fast")%8]
'빠른' >>> 결과
- 해쉬 함수 구현 예제
class Dict:
def __init__(self):
self.items = [None] * 8
def put(self, key, value):
index = hash(key)%len(self.items)
self.items[index] = value
return
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index]
my_dict = Dict()
my_dict.put("test", 3)
print(my_dict.get("test")) # 3이 반환되어야 합니다!
👉 문제 : 해쉬 값은 달라도 % 8 으로 했을 때 index의 값이 동일하게 나올 수 있다. -> 해쉬의 충돌!!!!
- 해쉬함수 index충돌 해결법 - 1
👉 링크드 리스트를 사용하자( 체이닝 이라고 부름 )
👉 키와 value를 같이 링크드 리스트에 저장하자!
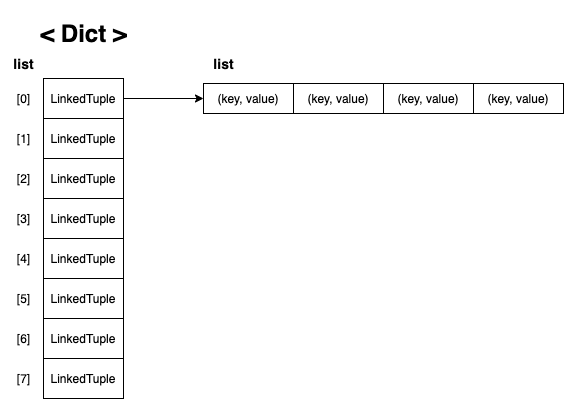
class LinkedTuple:
def __init__(self):
self.items = list()
def add(self,key,value):
self.items.append((key,value))
# ("abcdef","test33") -> [("abcedf","test33")]
# ("abcdef22","test44") -> [("abcedf","test33"),("abcdef22","test44")]
def get(self,key):
for k,v in self.items:
if key == k:
return v
class LinkedDict:
def __init__(self):
self.items = [] # [LinkedTuple(),LinkedTuple(),LinkedTuple() ..]
for i in range(8):
self.items.append(LinkedTuple())
def put(self,key,value):
index = hash(key) % len(self.items)
self.items[index].add(key,value)
# return
def get(self,key):
index = hash(key) % len(self.items)
return self.items[index].get(key)
linked = LinkedDict()
linked.put("sda","test1")
linked.put("sda2","test2")
print(linked.get("sda"))
- 해쉬함수 index충돌 해결법 - 2
👉 배열에 중복되지 않는 다음 index에 넣을 것 ( 개방 주소법이라 부름 )
- 해쉬 함수 총 정리
👉 키, 데이터를 저장함으로써 즉각적으로 검색할 때 빠르다.
( 시간 복잡도가 상수만큼 밖에 걸리지 않기 때문 ) ( Dict자료형과 동일하다. )
- 해쉬 함수 예제
all_students = ["나연", "정연", "모모", "사나", "지효", "미나", "다현", "채영", "쯔위"]
present_students = ["정연", "모모", "채영", "쯔위", "사나", "나연", "미나", "다현"]
def get_absent_student(all_array, present_array):
student_dict = {}
for key in all_array:
student_dict[key] = True # 키 값으로 삭제하므로 value값은 아무거나 상관없음
for key in present_array:
del student_dict[key] >> 처음 보는 개념 알아두기 del
for key in student_dict.keys():
return key
print(get_absent_student(all_students, present_students))
> 시간복잡도를 줄일 수 있지만 공간 복잡도를 많이 사용한다.
- 3주차 마무리 숙제 풀어보기 - 1
👉 최대한 할인 받을 수 있는 금액 구하기
shop_prices = [30000, 2000, 1500000]
user_coupons = [20, 40]
def get_max_discounted_price(prices, coupons):
prices.sort()
coupons.sort()
tot = 0
count_coupons = len(coupons)
for i in range(count_coupons):
next_price = prices.pop()
next_coupon = coupons.pop()
tot += next_price - (next_price * (next_coupon * 0.01))
for i in prices:
tot+=i
return tot
print(get_max_discounted_price(shop_prices, user_coupons)) # 926000 이 나와야 합니다.👉 정답 코드는 stack자료구조를 사용하지 않고 쿠폰과 가격의 index를 각각 저장하고 비교했다.
- 3주차 마무리 숙제 풀어보기 - 2
👉 올바른 괄호를 찾기 -> ()() 올바르다 )()( 올바르지 않다
s = "()))()"
def is_correct_parenthesis(string):
stack = []
for i in range(len(string)):
if string[i] == "(":
stack.append(i) # 어떤 값이 들어갔는지 중요하지 않음..!
elif string[i] == ")":
if len(stack) == 0:
return False
else:
stack.pop()
if len(stack) != 0:
return False
else:
return True
print(is_correct_parenthesis(s)) # True 를 반환해야 합니다!
👉 정답 코드는 " ( " 를 배열에 저장하고 " ) "를 만났을 때
pop() 진행해 만약 그 배열이 비었을 때 True를 반환하게 함.
👉 내 생각으로 짠 코드는 처음에 무조건 " ( "으로 시작하고,
그 때, " ( "의 갯수와 " ) "의 갯수를 count하여 같다면 True를 반환하게 코딩했다. > 정답 코드와 결과는 같지만 정확히 맞는지는 모르겠다.
- 3주차 마무리 숙제 풀어보기 - 3
👉 멜론 베스트 엘범 뽑기 -> 나는 생각을 못함...
{'classic': 1450, 'pop': 3100} -> dict 정렬을 해야함 -> 람다함수를 써야함 !!
{'classic': [[0, 500], [2, 150], [3, 800]], 'pop': [[1, 600], [4, 2500]]} -> 이런식으로 저장돼야 함def get_melon_best_album(genre_array, play_array):
n = len(genre_array)
genre_total_play_dict = {}
genre_index_play_array_dict = {}
for i in range(n):
genre = genre_array[i]
play = play_array[i]
if genre not in genre_total_play_dict:
genre_total_play_dict[genre] = play
genre_index_play_array_dict[genre] = [[i, play]]
else:
genre_total_play_dict[genre] += play
genre_index_play_array_dict[genre].append([i, play])
sorted_genre_play_array = sorted(genre_total_play_dict.items(), key=lambda item: item[1], reverse=True) -> key의 원소 값으로 정렬하겠다!! , reverse = True -> 내림차순
result = []
for genre, _value in sorted_genre_play_array:
index_play_array = genre_index_play_array_dict[genre]
sorted_by_play_and_index_play_index_array = sorted(index_play_array, key=lambda item: item[1], reverse=True)
for i in range(len(sorted_by_play_and_index_play_index_array)):
if i > 1:
break
result.append(sorted_by_play_and_index_play_index_array[i][0])
return result
print("정답 = [4, 1, 3, 0] / 현재 풀이 값 = ", get_melon_best_album(["classic", "pop", "classic", "classic", "pop"], [500, 600, 150, 800, 2500]))
print("정답 = [0, 6, 5, 2, 4, 1] / 현재 풀이 값 = ", get_melon_best_album(["hiphop", "classic", "pop", "classic", "classic", "pop", "hiphop"], [2000, 500, 600, 150, 800, 2500, 2000]))3. 느낀점⭐
1) 어떤 상황이 주어졌을 때 ex. 검색, 저장 , 삭제 등.. 에 최적의 성능을 내는 자료구조가 다양하고 그 상황에 맞게 쓰는게 프로그램의 효율을 늘릴 수 있다.
2) 너무 복잡하게 생각하지말자..

기록하는 습관