
🔠 키워드
- DBMS 엔진
- 관계형 데이터베이스(SQL)
- 비관계형 데이터베이스(NoSQL)
- CAP Theory
- 데이터베이스 확장(Scailing)
- 데이터베이스 동시성 제어
DBMS 엔진
DBMS: 데이터에 대한 스키마(테이블)정의(DDL), 저장 및 분석(DML) 그리고 관리 제공하는 응용 프로그램
프로그램을 생성하는 다양한 언어와 엔진들이 존재하는 것처럼 DB에도 DB를 관리할 수 있게 해주는 다양한 DBMS가 존재한다!
그럼 먼저 DBMS 2가지 먼저 살펴보자
보기 전에 앞서 가장 큰 차이점은 관계형 데이터베이스는 High Reliability 즉 ACID를 준수한다는 점, 비관계형 데이터베이스는 High Scalability 즉 확장성이 좋다는 점이 있다.
구체적으로 살펴보자!!
관계형 데이터베이스(SQL)
2차원(행렬) 구조 데이터 + 관계 기반 데이터 종속성 표현
- Guaranteed Consistency
- Data Integrity
=> 수평적 확장에 한계
영어로 보니까 어려워서 구글에 쳐봤더니
트랜잭션: 전체 트랜잭션이 하나의 단위로 기록되고 실패시 전체 Roll back
정규화: DB 설계 시 중복을 최소화해서 구조화하는 프로세스
이렇게 보니까 쉽다 ㅎㅎ
💡 여행 예약(항공권 예약, 기차 예약, 숙소 예약)이라는 Transaction A가 존재
- 항공권 예약 ⇒ 가는 표 예약/오는 표 예약
- 기차 예약 ⇒ 가는 표 예약/오는 표 예약
- 숙소 예약 ⇒ 첫째날 숙소 예약/둘쨋날 숙소 예약
-> 해당 상황에서 항공권 둘 중 하나가 실패하면 아예 실패 시켜야 함.
수업중에 알려준 내용까지 덧붙여보면 Transaction이 고신뢰성을 보장하기 위해서는 ACID 특성을 필수로 가져야 한다.
- Atomicity(원자성): 완벽하게 수행이 되거나/완벽하게 수행이 되지 않거나
- Consistency(일관성): 데이터 정합성
- Isolation(격리성): 동시에 다수 트랜잭션이 발생 시 모든 트랜잭션은 독립되어야 한다.
- Durability(지속성): 데이터 지속적으로 존재
이러한 특징 때문에 장단점은 아래와 같다.
장점
- 데이터의 성능이 일반적으로 좋아 정렬, 탐색, 분류가 빠르다.
- 고신뢰성, 데이터 무결성
- 정규화에 따른 갱신 비용을 최소화
단점
- 기존에 작성된 스키마를 수정하기 어렵다.
- 데이터베이스의 부하를 분석하기 어렵다.
- 빅데이터를 처리하는데 매우 비효율적이다.
비관계형 데이터베이스(NoSQL)
트리 구조 데이터 = 트리 기반 데이터 종속성 표현
- Eventual Consistency
- Schema-less
=> 수평적 확장에 유리(웹 2.0과 빅데이터 시대를 맞이함에 따라, 무한 확장 가능한 DB 필요)
NoSQL = Not Only SQL
해당 DB는 관계형 데이터베이스의 한계를 뛰어넘기 위해 만들어진 새로운 형태의 DB이다!
관계형 데이터베이스와 달라 PK, FK, JOIN 등의 관계를 정의하지 않는다(신기)
대신 거대한 Map으로 key-value 형식을 지원함! 이러한 형식은 분산 환경에서 데이터 처리를 더욱 빠르게 하기 위해 개발되었다.
방금 관계형 데이터베이스에서 ACID 얘기를 했는데...!
사실 비 관계형 데이터베이스에서 보장되어야 하는 개념이 있다.
바로 BASE!
Basically Available: 기본적으로 Availability 보장
Soft state: Consistency의 책임은 DB가 아닌 개발자에게
Eventual consistency: ACID에서의 Consistency에 대응되는 것
NoSQL 종류
- Key-Value 기반 DB: Redis
- Document(Key-Value 확장)기반 DB: MongoDB, CouchDB
- Column 기반 DB: Cassandra
- 데이터 분석을 위해 사용
- 빅데이터 쿼리 시 굉장히 빠른 결과 도출
- 무자비한 SELECT * 그리고 굉장히 느린 UPDATE
왜 자꾸 수평적 확장 얘기를 하는걸까?
수직적 확장을 하는 것은 인스턴스 교체, 서버 스펙 높이기와 같은 비용을 요구한다.
하지만 수평적으로 확장한다면 이러한 비용을 줄일 수 있다.
장점
- 대용량 데이터를 처리하는데 효율적
- 복잡한 데이터 구조 저장 가능
- 데이터 모델링이 유연
- 읽기 작업보다 쓰기 작업이 더 빠르고, 관계형 DB에 비해 읽기/쓰기 성능이 모두 더 뛰어남
- key-value 저장방식으로 응답 속도나 처리 효율 등에서 성능이 뛰어남
단점
- 데이터 무결성 제약이 강하지 않음
CAP Theory
분산 시스템은 아래의 CAP 3개를 모두 보장할 수 없다. 최대 2개 보장 가능
- Consistency(일관성)⭐: UPDATE, INSERT, DELETE 시 모든 노드가 같은 값을 가져야 한다.
ex. 고객이 A상담원과 얘기한 내용을 B상담원도 알고 있어야 한다. 즉 각 상담원들은 서로 같은 정보를 공유한다. - Availability(가용성)⭐: 분산 시스템 중 일부가 실패해도 나머지는 정상적으로 서비스
ex. 고객은 원하는 정보를 언제든지 고객센터를 통해 알 수 있어야 한다. - Partition Tolerance(파티션 허용 오차): 네트워크 장애에 대한 내결함성(FT)
ex. 고객센터 내에 전산문제가 발생해도 고객센터 자체는 정상적으로 운영되어야 한다. 즉 통신이 복구되기 전까지 잠시 기다리라고하거나 예전 정보로라도 상담을 진행해야 함!
CAP이론은 분산 데이터베이스 시스템에 분할이 생겼을 때 Consistency(일관성)와 Availability(가용성) 중에 하나를 희생해야 한다는 것!
예를 들어보면
두 노드로 이루어진 분산 시스템에서 분할이 생겼을 때 데이터의 일관성을 보장하는 것이 불가능하다. 그러므로 분할이 생겼더라도
1) 정상적으로 요청을 처리해 일관성을 희생하고 가용성을 높이던지,
2) 잠시 요청 처리를 중단하고 중단된 노드가 재실행될 때까지 기다려 가용성을 희생하고 일관성을 지키는 방법
중 하나를 선택해야 한다.
아래는 ACID와 BASE를 비교한 표이다.
| 특징 | ACID | BASE |
|---|---|---|
| 데이터 일관성 | 강조 | 유연하게 다룸 |
| 가용성 | 덜 강조 | 강조 |
| 데이터 일관성 보증 | 엄격하게 보장 | 유연하게 다룸 |
| 응답 시간 | 예측 가능 | 일시적이고 느림 |
데이터베이스 확장(Scaling)
대규모 DB 시스템에서 부하 분산 및 확장성을 위해 진행해야 하는 작업!
이를 위한 작업으로 Partitioning, Sharding, Replication이 있다.
Partitioning
하나의 테이블을 여러 데이터로 쪼개어 저장하는 것
Vertical Partitioning
컬럼(열) 쪼개기
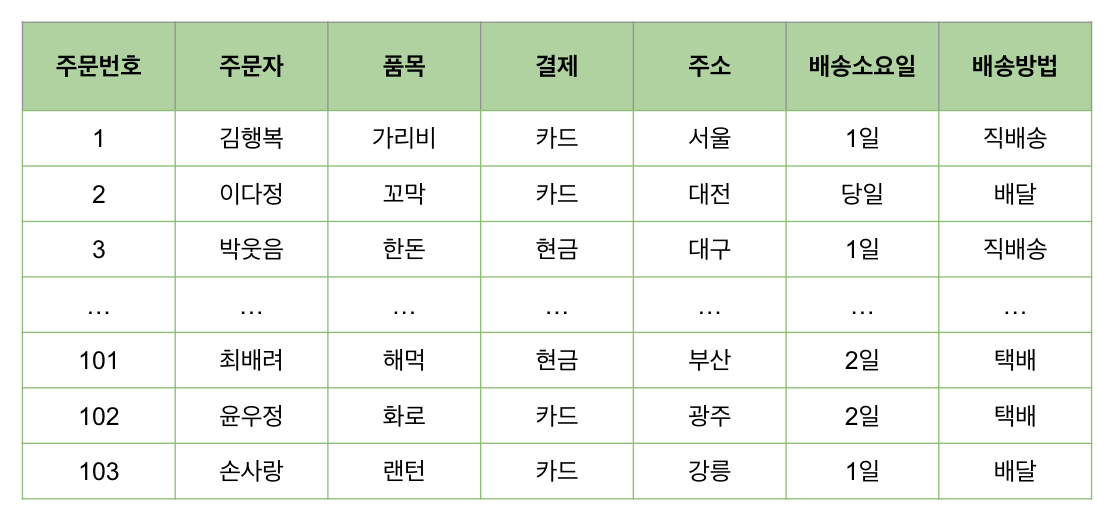
Horizontal Partitioning(Sharding)
로우(행) 쪼개기
같은 테이블 스키마를 가진 데이터를 다수의 DB에 분산하여 저장하는 방법
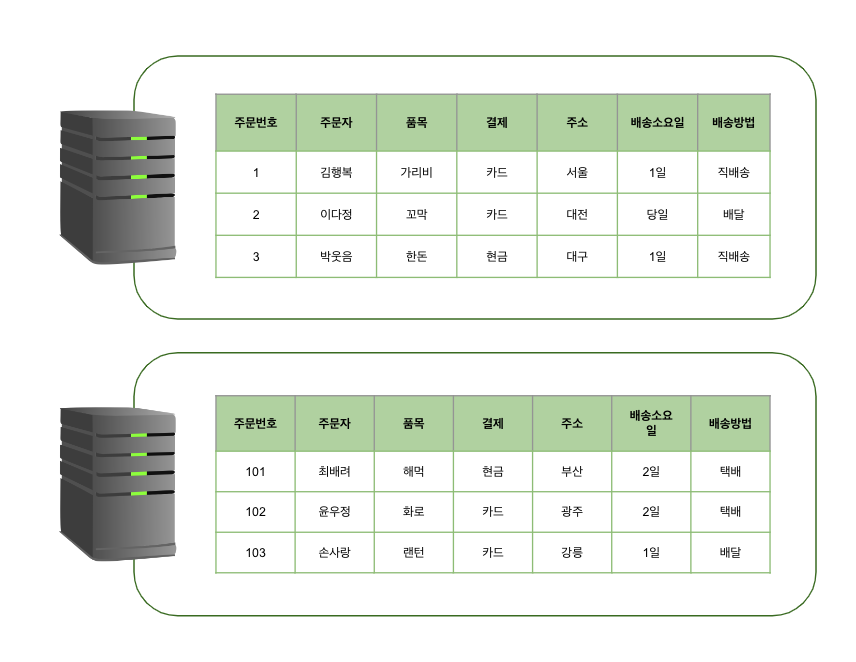
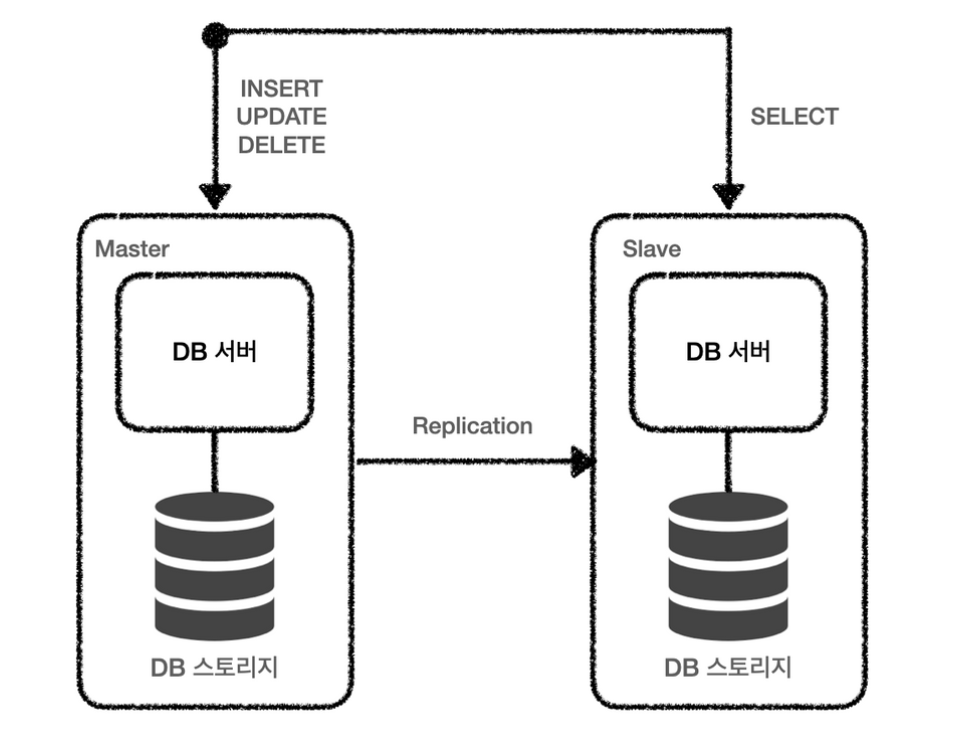
Replication
실제 데이터가 저장되어 있는 저장소 복제하는 것
서버와 DB 스토리지를 모두 확장
여러 개의 DB를 권한에 따라 수직적인 구조로 구축하는 방식
비동기 방식으로 데이터 동기화하기 때문에 일관성있는 데이터를 얻지 못할 수도 있다.
쓰기 담당/ 읽기 담당을 나누어, 쓰기 발생 시 읽기 담당에 모두 동기화를 맞춰야 한다.
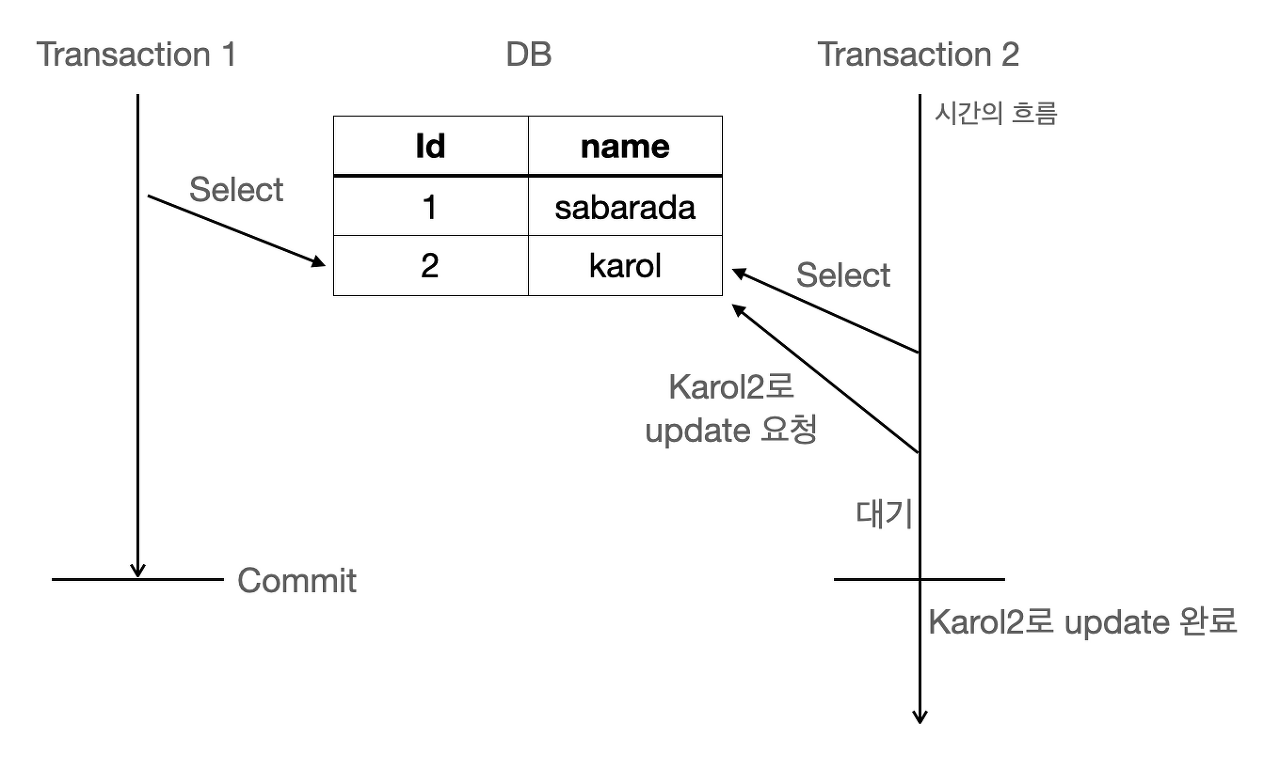
데이터베이스 동시성 제어(Concurrency Control)
Pessimistic Locking(비관적 락): "분명히 충돌날거야"
DBMS 레벨에서의 Locking이다.
데이터를 읽을 때/편집을 시도하기 전에 데이터를 잠그는 방식
쓰기가 읽기를 기다린다.
장점: 데이터 무결성 보장 수준이 높아진다.
단점: 동시성이 떨어진다.
읽기를 해도 쓰지 못하게 막거나, 쓰기를 해도 읽지 못하게 하는 것
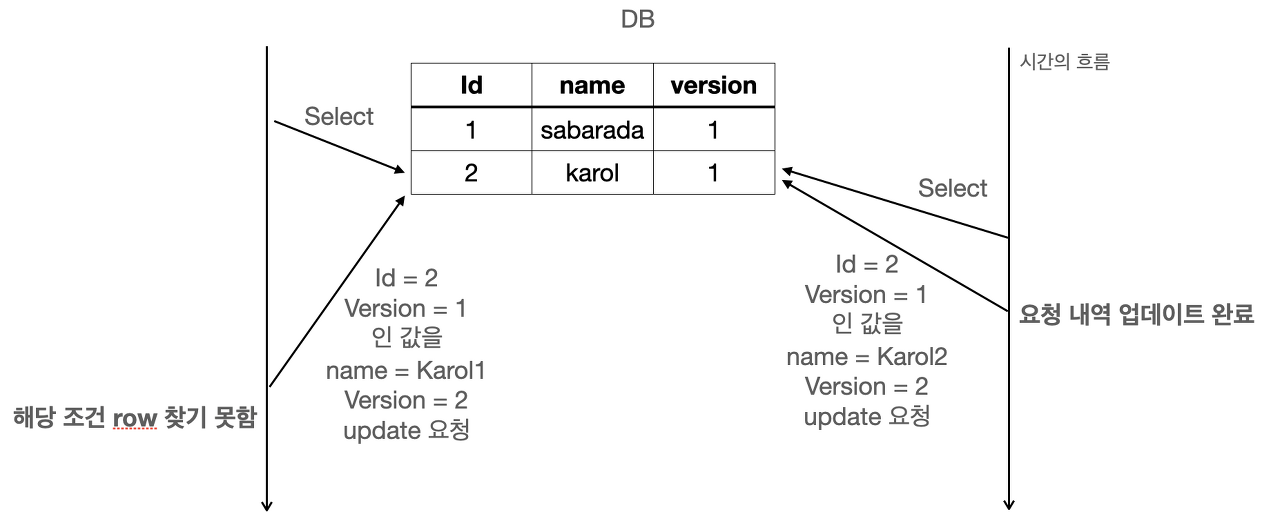
Optimistic Locking(낙관적 락): "에이 설마, 충돌나지 않을거야"
Application 레벨에서의 Locking이다.
업데이트 시에 충돌 여부를 확인하는 방식
쓰기와 읽기는 별개
장점: 동시성이 좋다.
단점: 데이터 무결성 보장 수준이 낮다.
참고 문헌
https://newehblog.tistory.com/38
https://onduway.tistory.com/106
https://eunsun-zizone-zzang.tistory.com/50
https://sabarada.tistory.com/175
