
What DQNs are for
DQN도 그렇고 Dueling DQN도 그렇고, 게임 용도로 개발됐습니다.
동영상은 연속된 사진들입니다. 인간은 눈을 통해서 1초에 30장 ~ 60장의 사진을 인지할 수 있고요. 그래서 아이폰 디스플레이가 120Hz이면 60Hz일 때보다 더 스무스해보이는 거에요. 같은 시간에 더 많은 사진들을 보여주면 다음 사진으로 넘어갈 때 차이가 작으니까요. 끊김이 덜한 거죠.
마찬가지로 게임 화면 사진 하나하나를 받아서, AI로 하여금 각 사진에서 어떤 선택이 최선인지 선택하게 하는 거에요. 예를 들어서, 2013년에 Atari라는 벽돌 깨기 게임 공략은 Deep Q-Learning으로 이루어졌다는 게 사람들을 놀라게 했죠. 공을 벽 너머로 보내서 깨부신다는 전략을 AI가 스스로 학습한 것도 놀랍고요.
여기에서 Deep Q-Network를 발전시킨 게 Dueling Deep Q-Network입니다. 지금 제가 보여드리는 건 잠수함 게임인데요. 오른쪽에 있는 게 Deep Q-Network Output array입니다. 빨간색으로 표시된 게 Q-value가 제일 큰 것, 즉 optimal choice라는 것을 보여주는 거고요.
각 단계에서 이런 행동들을 수행할 수 있는데요
- No Operation
- Fire
- Up
- Right
- Left
- Down
- Up-Right
- Up-Left
- Down-Right
- Down-Left
- Up-Fire
- Right-Fire
- Left-Fire
- Down-Fire
- Upper-Right-Fire
- Upper-Left-Fire
- Down-Left-Fire
Oxygen Level을 조절하고, 파란색 잠수부를 구하고, 물고기들을 파괴하거나 피해야 하는 간단한 게임입니다.
How Dueling DQN Works
Q-value의 최대치와 Q-value의 최소치를 비교한 것입니다. Q-value의 최대치가 곧 게임에서의 action이 되는데요. 문제는 Q-min과 Q-max의 차이가 크지 않다는 것입니다. Q-value의 변동성에 비해서, 최적의 선택과 최악의 선택이 차이가 크게 나타나지 않는다는 점이죠.
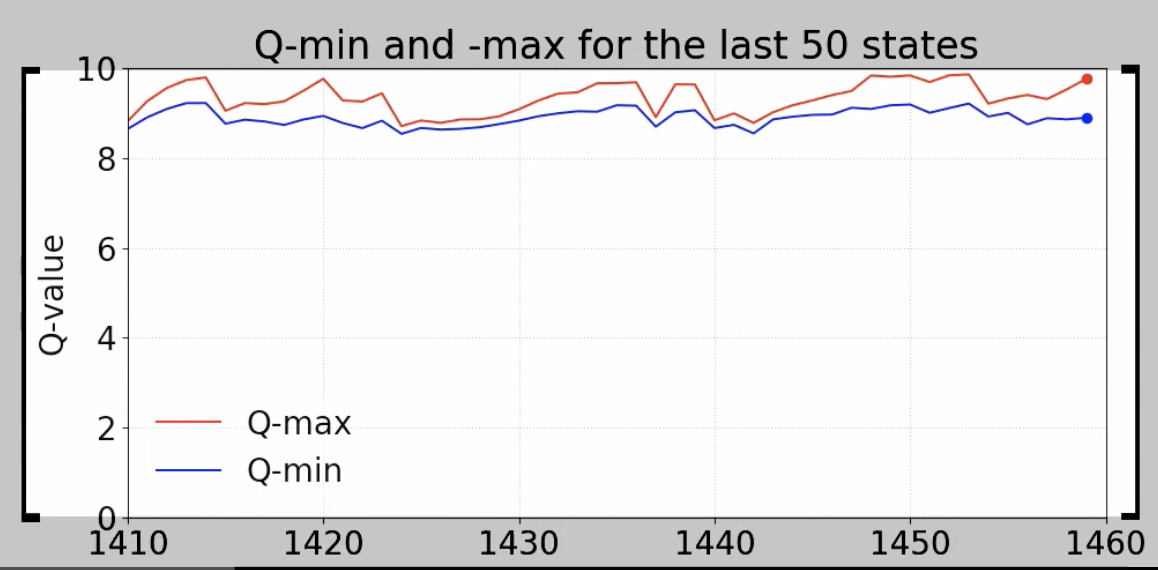
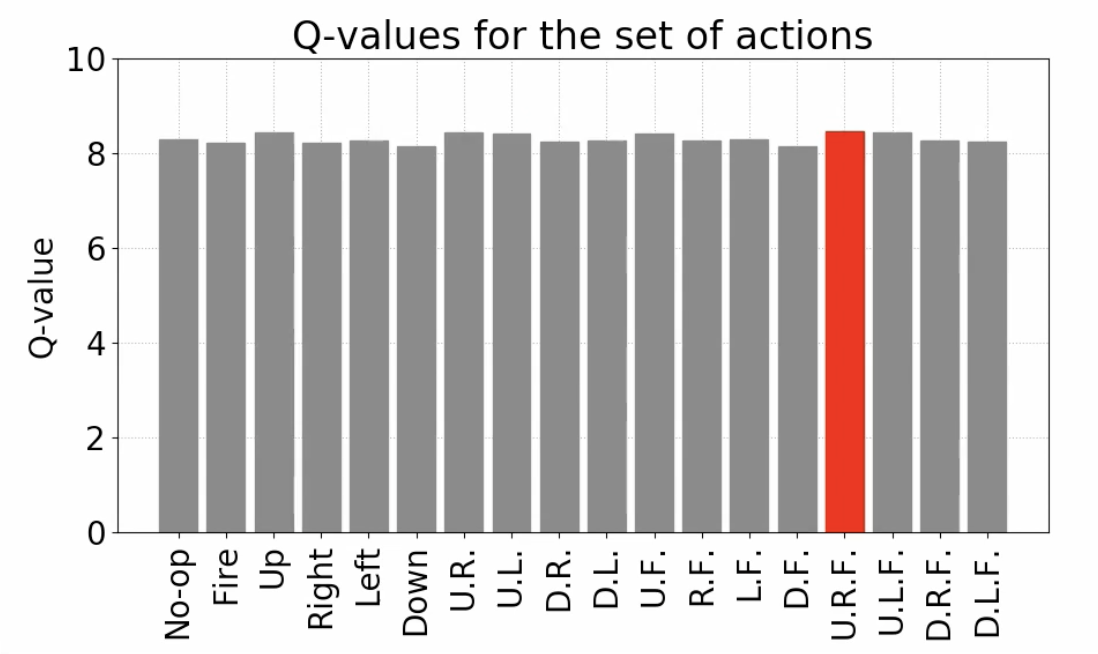
그래서 다음 같이 Q-value 중에서 최대값을 뽑아내는 방식보다는
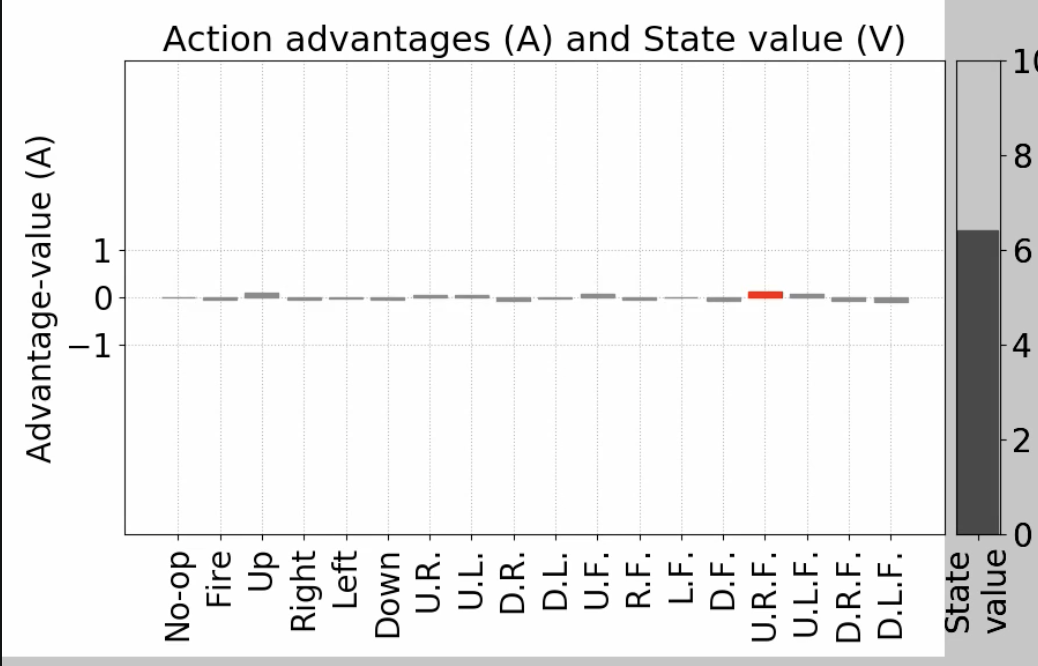
다음과 같이 전체 평균과의 차이를 도출해내는 게 더 적합합니다.
이를 공식으로 복잡하게 나타내면 다음과 같습니다.
Q value = State Value (V) + (Advantage Value - Mean of Advantage Values)
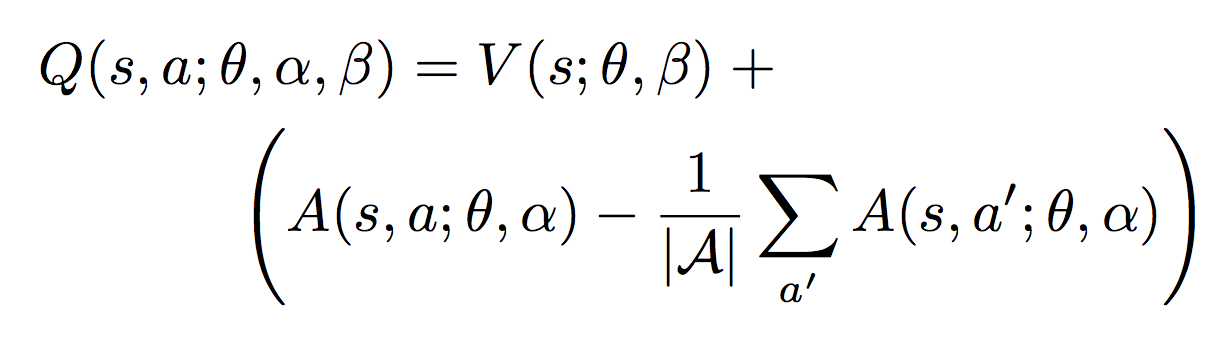
여기서 "Dueling"에서 어떤 의미일까요?
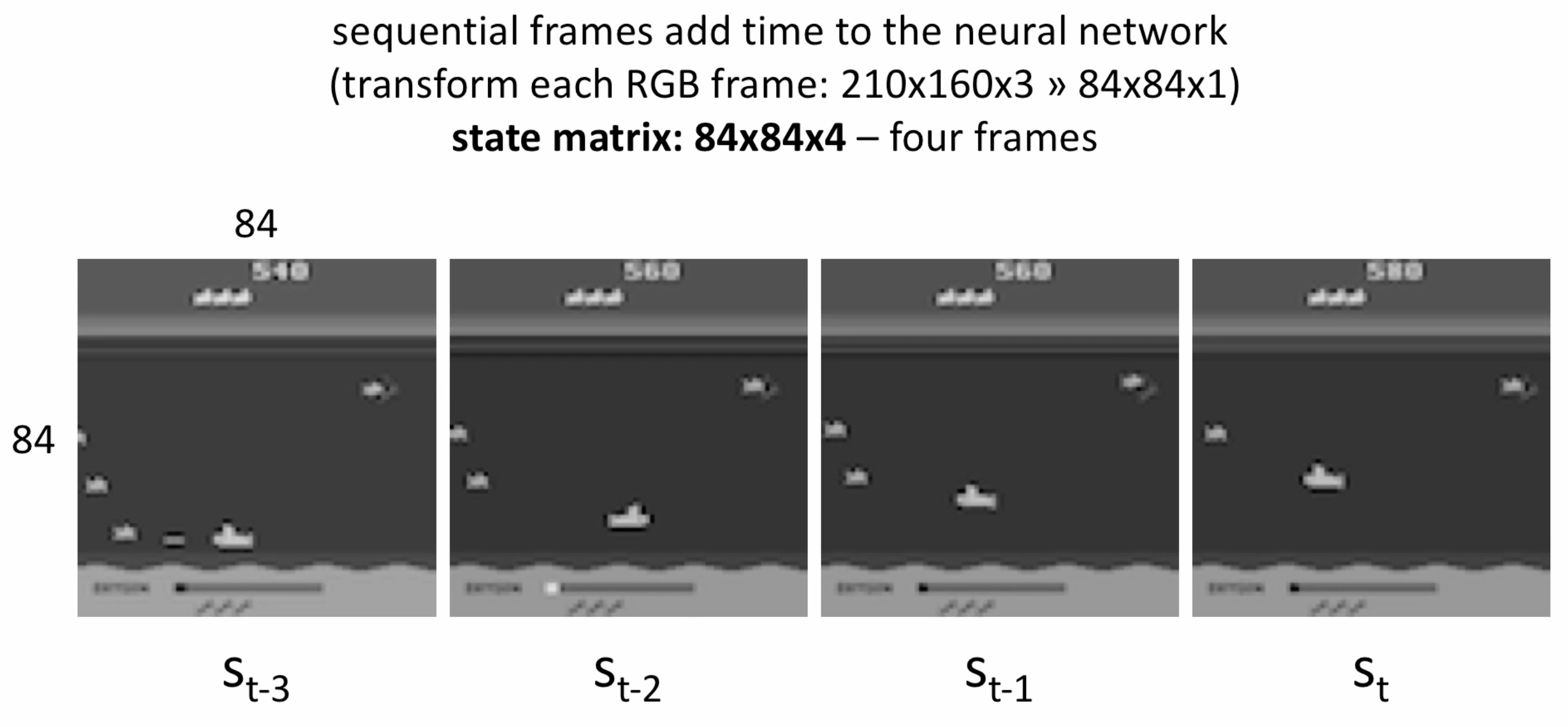
일단 어떤 프레임들을 딥러닝 모델이 받는지 봅시다. 경제학에서 T-1, T-2, T처럼 프레임을 표시하고요, Sequential하게 각 Frames들을 받습니다. 각 frame은 84 x 84 x 1 이고요.
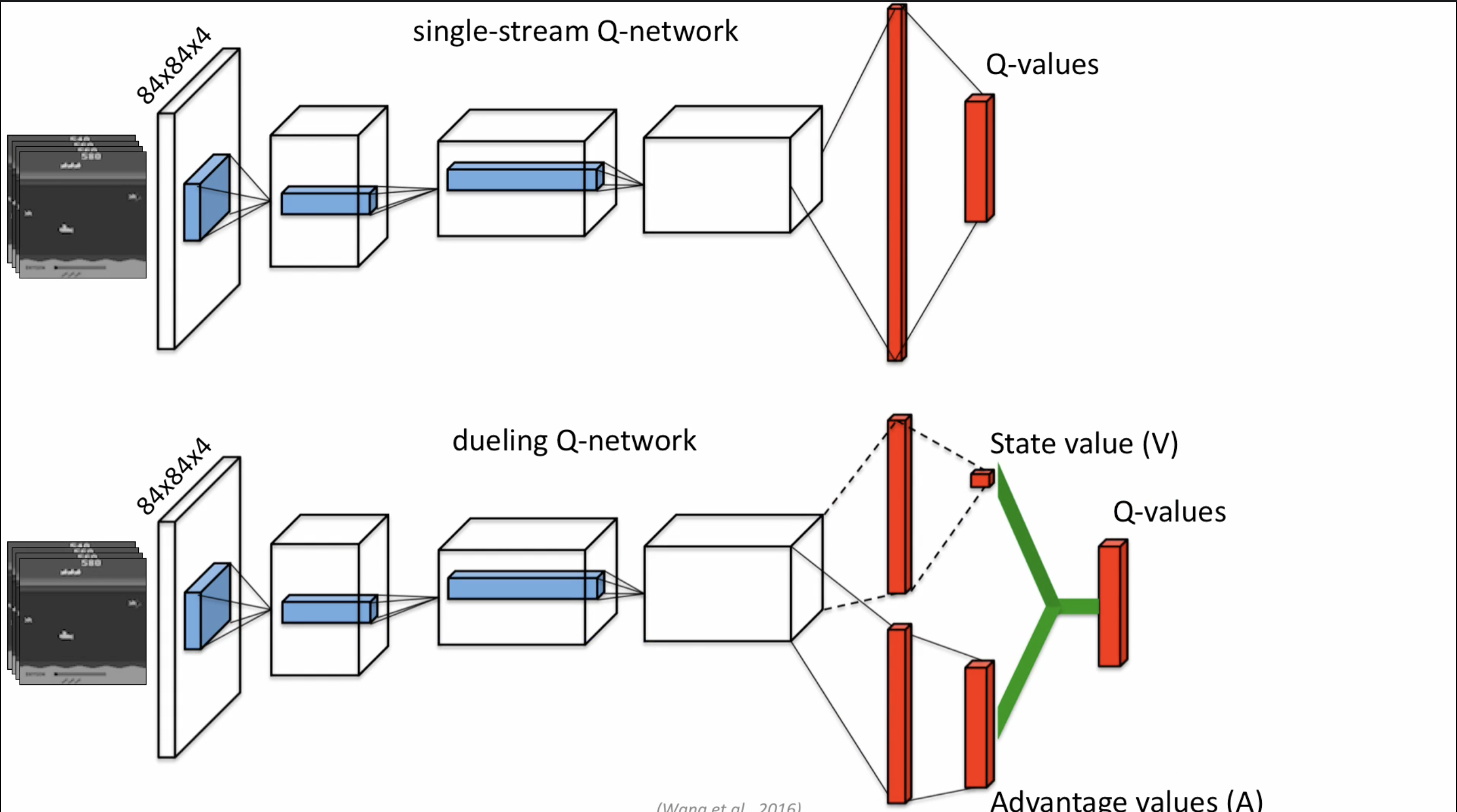
아래가 Dueling Q Network이고, 위가 Single-stream Q-network입니다. 보시다시피 Dueling Q Network는 State value와 Advantage value 두 가지를 갖고 Q-value를 도출합니다.
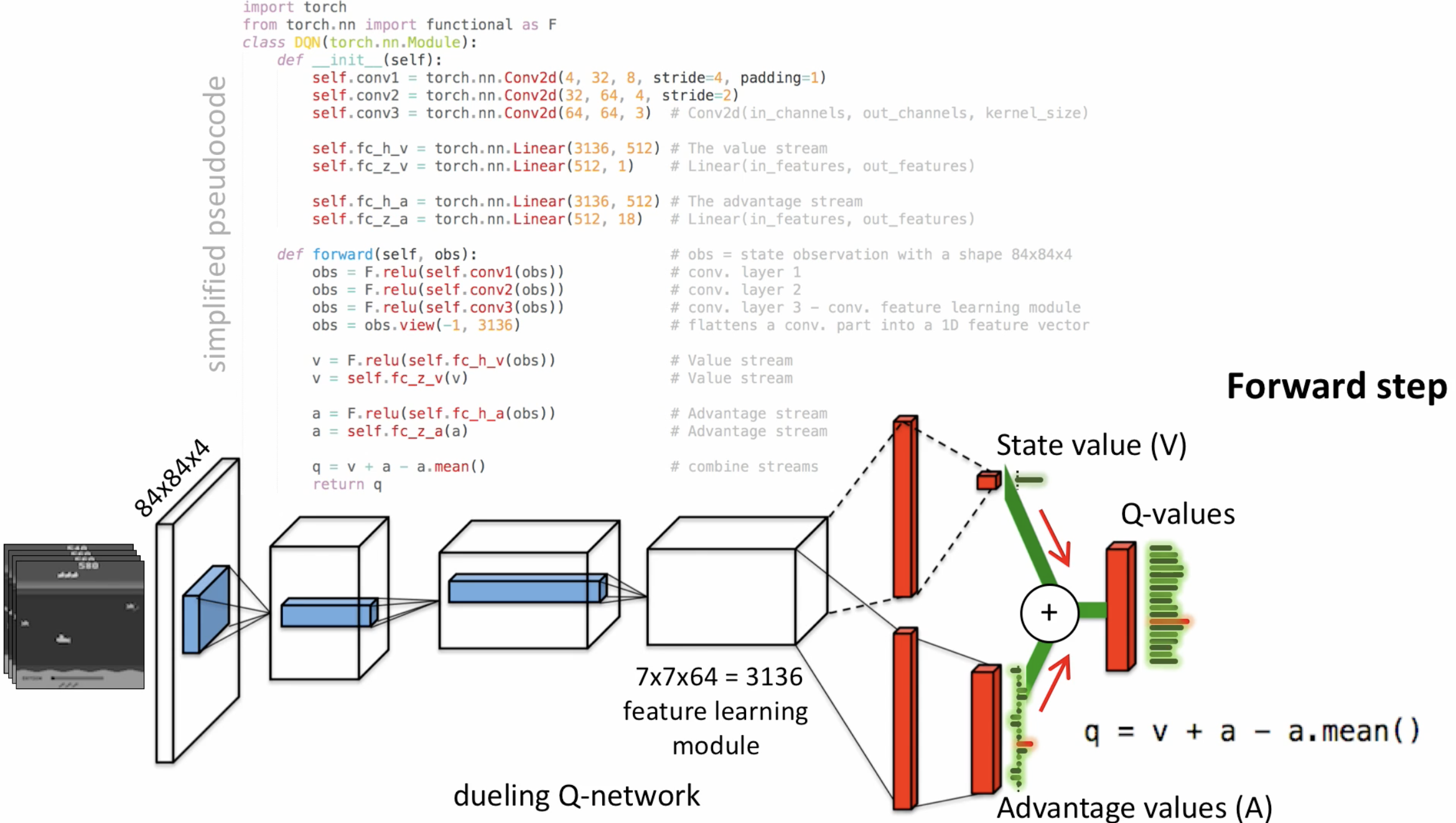
이게 어떤 다른 점이 뭐가 있을까요? Forward step에서 사실 유의미한 차이는 없습니다.
유의미한 차이는 Training 단계에서 나타나는데요, backpropogation 단계에서 한 가지 정보만 주냐, 아니면 두 가지 정보를 나눠서 주냐에서의 차이가 있습니다.
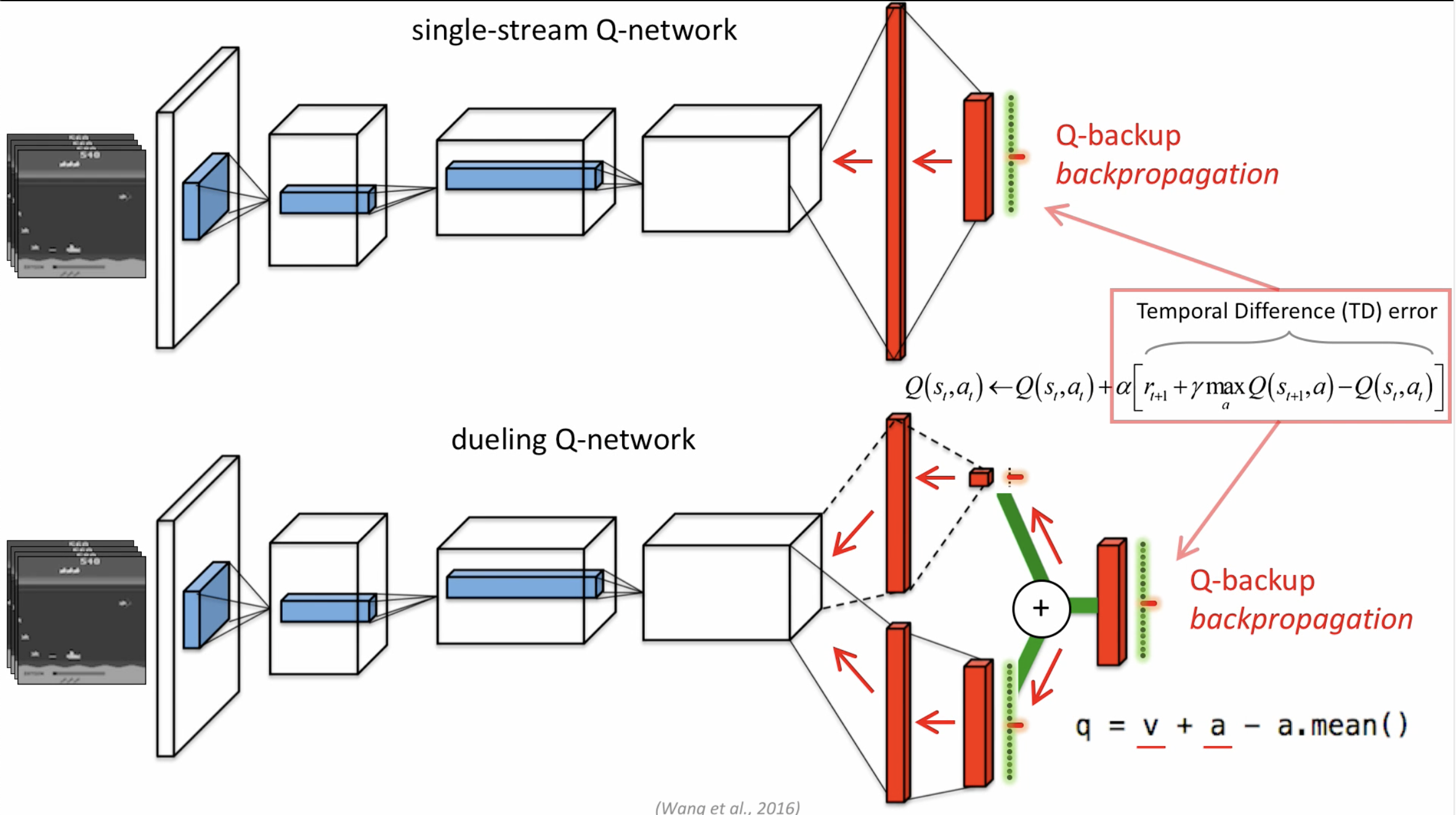
상황 정보(V)와 Advantage Value 두 가지를 종합한 게 다른 DQN보다 성능이 좋음을 알 수 있습니다.

Pytorch Code for Dueling DQN
class Dueling_DQN(nn.Module):
def __init__(self, in_channels, num_actions):
super(Dueling_DQN, self).__init__()
self.num_actions = num_actions
# convolution networks
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=32, kernel_size=8, stride=4)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1)
# Advantage Value & State Value
self.fc1_adv = nn.Linear(in_features=7*7*64, out_features=512)
self.fc1_val = nn.Linear(in_features=7*7*64, out_features=512)
# Advantage Value & State Value
self.fc2_adv = nn.Linear(in_features=512, out_features=num_actions)
self.fc2_val = nn.Linear(in_features=512, out_features=1)
self.relu = nn.ReLU()
def forward(self, x):
batch_size = x.size(0)
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
x = x.view(x.size(0), -1)
adv = self.relu(self.fc1_adv(x))
val = self.relu(self.fc1_val(x))
adv = self.fc2_adv(adv)
val = self.fc2_val(val).expand(x.size(0), self.num_actions)
# Q-value from dueling DQN
x = val + adv - adv.mean(1).unsqueeze(1).expand(x.size(0), self.num_actions)
return xReferences
