
🌟 프로젝트 소개
담채 DamChae(감정을 담아 공간을 채우다)
담채란?
- 감정을 나누고 공유하는 감정일기 플랫폼과 MBTI기반 감정분석 커뮤니티
- 인공지능 모델을 통해 텍스트에서 감정을 추출하고 분류해서 보여준다
- 인공지능 모델은 Kobert + Stable Diffusion 이용
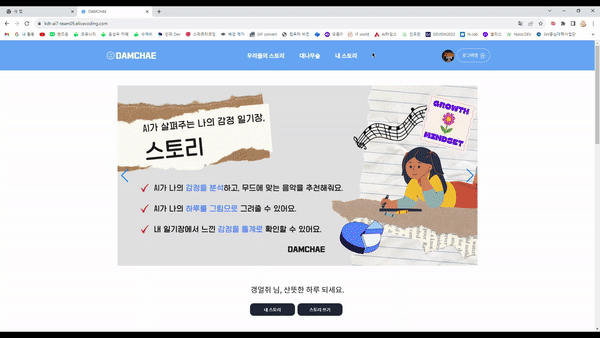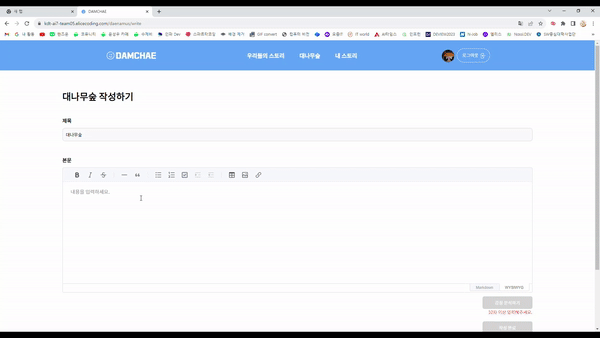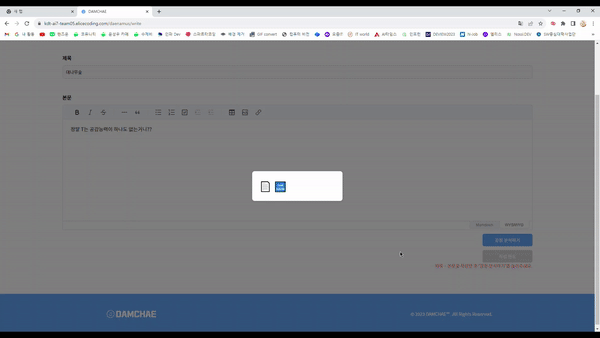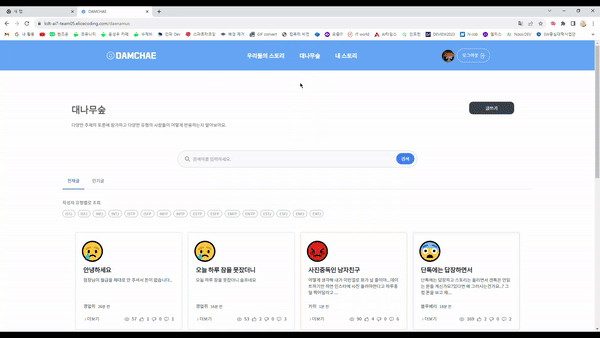
1. 스토리 (감정일기장)


- 오늘 있었던 일, 기록하고 싶은 일을 작성
- 감정분석을 통해 분노/불안/놀람/기쁨/슬픔/중립 중 하나로 오늘의 감정이 선택
2. 대나무숲 (MBTI토론장)


- 작성자 MBTI별 글 조회가 가능 → 각 MBTI별로 어떤 주제가 활발한지 알 수 있다
- 본문을 작성하고 감정 분석하기를 누르면 작성자의 감정을 분석하여 이모티콘으로 표시
- 댓글을 달면 감정분석을 통해 도출된 감정으로 MBTI유형별 반응 확인
※ 나머지 페이지는 생략..
사용 기술 스택
담당 역할: 백엔드
🌟 What I Learned
🧩 트랜잭션 처리
은행에서 계좌를 출금하는 행위를 예시로 들어보자.
계좌를 출금할 때는 나의 계좌 잔액을 줄이는 단계와 출금하는 단계가 존재.
이때 어떤 장애로 인해 잔액을 줄이고 출금하는 전 단계에서 에러가 났을 경우 내 계좌에 있는 돈만 사라지고 실제 출금이 안되는 경우가 발생.
여러 단계 중 하나의 단계가 실패하면 전부 다 초기 상태로 되돌리는 기능이 필요하다.
이러한 기능을 트랜잭선(Transaction)이라 한다.
트랜잭션 내에서 발생하는 어떤 에러라도 감지하면 해당 트랜잭션은 롤백되며,
이번 프로젝트에서 좋아요/싫어요, 게시글 생성 및 삭제에 사용되었다.
Mongoose에서 Transaction사용 예시
※ 예외 처리 try-catch-finally 중요!
class forestLikeDislikeService {
static async createForestPostLike(userId, postId) {
// 트랜잭션 시작
const session = await mongoose.startSession();
session.startTransaction();
try {
const likeInfo = await forestLikeDislikeModel.findLikeInfo(
userId,
postId,
);
if (likeInfo) {
const errorMessage = '좋아요를 이미 눌렀습니다';
return { errorMessage };
}
await forestLikeDislikeModel.createLike(session, userId, postId);
const dislikeInfo = await forestLikeDislikeModel.deleteDislike(
session,
userId,
postId,
);
if (dislikeInfo) {
await forestLikeDislikeModel.updateClickCounts(postId, 1, -1);
} else {
await forestLikeDislikeModel.updateClickCounts(postId, 1, 0);
}
// 트랜잭션 커밋 (모두 성공 시)
await session.commitTransaction();
return { result: 'Success' };
} catch (error) {
// 트랜잭션 Rollback (하나라도 실패 시)
await session.abortTransaction();
console.error('Transaction aborted:', error);
} finally {
// 세션 종료
session.endSession();
}
}
}
class forestLikeDislikeModel {
static async createLike(session, userId, postId) {
await forestLike.create([{ userId, postId }], { session });
return;
}
....
}await create , await updateClickCounts 등 여러 작업이 실행될 때 위와 같이 mongoose에서 startSession객체를 가져온다.
🧩 라우터 선언 순서의 중요성
/recommend 라우터를 구현 중, 실행했더니 /:storyId 라우터가 실행되는 이슈가 생겼다.
storyPostRouter.post('/',uploadS3.single('thumbnail'),storyPostController.createStoryPost,);
storyPostRouter.get('/', storyPostController.readAllStories);
storyPostRouter.get('/:storyId', storyPostController.readStoryDetail);
storyPostRouter.delete('/:storyId',storyPostController.deleteStoryPost,);
storyPostRouter.post('/isAlreadyWrote', storyPostController.checkAlreadyWrite,);
storyPostRouter.get('/recommend',storyPostController.getPredict);이슈 원인은 바로 라우터 선언 순서에 있었다.
/recommend 라우터가 같은 자리의 params 라우터에 빨려들어가서 해당 라우터가 불려진 것이었다.
해결방법은 고정적인 주소에 대한 라우터를 먼저 선언하고, params와 같은 가변적인 주소에 관련된 라우터를 그 다음에 선언한다.
storyPostRouter.post('/',uploadS3.single('thumbnail'),storyPostController.createStoryPost,);
storyPostRouter.get('/', storyPostController.readAllStories);
storyPostRouter.post('/isAlreadyWrote', storyPostController.checkAlreadyWrite,);
storyPostRouter.get('/recommend',storyPostController.getPredict);
storyPostRouter.get('/:storyId', storyPostController.readStoryDetail);
storyPostRouter.delete('/:storyId',storyPostController.deleteStoryPost,);🧩 multer-S3 사용법
multer와 multerS3을 통해 AWS S3에 접근하여 S3 버킷에 이미지 파일을 저장하고, DB에는 그 버킷의 이미지 파일 경로(이미지 주소)를 저장하는 프로세스를 구축했다.
export const s3 = new S3Client({
credentials: {
accessKeyId: process.env.S3_ACCESS_KEY_ID,
secretAccessKey: process.env.S3_SECRET_ACCESS_KEY,
},
region: process.env.S3_REGION,
});
export const uploadS3 = multer({
storage: multerS3({
// 저장 위치
s3,
bucket: process.env.S3_BUCKET_NAME,
acl: 'public-read',
contentDisposition: 'inline',
contentType: multerS3.AUTO_CONTENT_TYPE,
// 파일명 설정
async key(req, file, done) {
....위에서 설정한 uploadS3가 실행되면 설정한 이름의 Bucket에 파일을 업로드할 수 있다.
이 때 acl과 contentDisposition을 적절하게 설정해야하는데, 보통 게시글의 이미지는 공개적으로 보여지는 것이 일반적이기 때문에 acl 권한을 public-read으로 설정하고, 브라우저 상에서 이미지 파일을 바로 열어보거나 보여줄 수 있도록 contentDisposition을 inline으로 설정했다.
🧩 좋아요 기능 구현 방법
이전 프로젝트에서는 좋아요 스키마를 따로 생성하지 않고 MongoDB의 쿼리 조건 연산자(예: $inc $addToSet)를 이용하여 좋아요 기능을 구현했다. 좋아요 또는 싫어요를 누르면 likeCount값과 likeUsers배열 값이 수정되므로 해당 라우터의 HTTP요청 메소드로 put을 사용했다.
// 좋아요 추가
static async addLike({ postId, pressLikeUserId }) {
const filter = { _id: postId};
const update = {
// 좋아요 카운트 1씩 증가
$inc: { likeCount: 1 },
// 배열에 좋아요누른 사용자 ID 추가 ($push대신 $addToSet사용하여 중복방지)
$addToSet: { likeUsers: pressLikeUserId },
};
const option = { returnOriginal: false };
const AddLike = await BlogPostModel.findOneAndUpdate(
filter, update, option
);
return AddLike;
}이와 달리, 이번 프로젝트에서는 사용자가 좋아요를 누른 게시글을 조회하는 기능을 구현하게 되어 $연산자를 사용하지 않고 좋아요 스키마를 새로 생성했다.
const forestLikeSchema = new Schema(
{
userId: {
type: Schema.Types.ObjectId,
ref: 'User',
required: true,
},
postId: {
type: Schema.Types.ObjectId,
ref: 'ForestPost',
required: true,
},
},
....좋아요(싫어요)를 누른 사용자ID와 좋아요(싫어요)가 눌린 게시글ID를 가져오고, 게시글의 좋아요(싫어요) 정보를 조회(get)하는 api, 생성(post)하는 api, 취소(delete)하는 api를 개발했다.
※ 참고글
🧩 Populate으로 참조 데이터 가져오기
populate는 Mongoose에서 가장 중요한 메소드 중 하나로, ObjectId 형식으로 저장된 특정 필드를 참조된 컬렉션의 문서 형태로 불러올 수 있다.
// populate 적용 전
{
"userId": ObjectId,
"title": String,
"content": String,
"imageId": ObectId,
....
}
// populate 적용 후
{
"userId": {
"_id":ObjectId,
"email": String,
"password": String,
"nickname":String,
},
"title": String,
"content": String,
"imageId": {
"_id": ObjectId,
"fileName": String,
"filePath": String
},
....
}find VS populate
1,2차 프로젝트에서는 find메소드로 컬렉션에서 조건에 맞는 다큐먼트를 조회한 후 다시 다른 모델의 find메소드를 호출하여 참조된 다른 컬렉션의 정보를 불러오는 비효율적인 방법으로 구현해오고 있었다는 걸 알았다.
따라서 별도의 쿼리를 추가하지 않고 한 번의 요청으로 연관된 데이터를 가져올 수 있는 populate 메소드를 사용해서 코드를 간결화하고 데이터의 일관성을 유지하려 노력했다.
🌟 신경 쓴 부분
파일 선택 후 직접 업로드 VS AI로 이미지 생성 후 업로드
이번 프로젝트에서는 이미지를 보여주는 방식에 대해 고민을 많이 했다. 각각 다른 두 가지 방법으로 구현해야했는데 첫번째는 사용자가 직접 선택한 이미지 파일의 경로를 프론트에게 보내주는 방법, 두번째는 AI(Stable Diffusion)로 이미지 생성 후 생성된 경로를 프론트에게 보내주는 방법이었다.
첫번째는 전송된 파일 데이터를 req.file 객체에 저장하고 multerS3 미들웨어를 사용하여 파일 업로드를 처리하는 일반적인 방법이라 큰 어려움이 없었다.
두번째 방법을 어떤 식으로 짜야할지 감이 안왔었는데.. 이미지 생성 후 응답 데이터를 print해보니 금방 해결법을 찾았다. 아래와 같이 Flask서버 안에서 이미지 생성에 필요한 매개변수와 data를 지정하여 요청 바디를 생성한 후 생성된 요청을 API에 전송하고 응답을 받아올 때 해당 응답 데이터에는 이미지의 Base64값이 들어있었다.
def generate_image():
# axios사용하여 POST요청으로 전달된 content(게시글 내용) JSON 데이터를 파싱 후 data변수에 저장
data = request.get_json()
url = "https://api.stability.ai/v1/generation/stable-diffusion-xl-beta-v2-2-2/text-to-image"
body = {
"text_prompts": [
{
"text": data,
"weight": 1
}
],
}
headers = {
...
}
response = requests.post(url, headers=headers, json=body)이미지의 Base64값을 json응답으로 반환 후 해당 데이터를 Buffer객체로 변환했다.
아래와 같이 이미지를 S3에 업로드하기 위한 파라미터를 설정하고 이미지 데이터를 S3에 업로드하고 업로드된 이미지 S3경로 URL과 파일명을 프론트에게 전달했다.
static async uploadStableImageInS3(imageData) {
const uploadParams = {
Bucket: process.env.S3_BUCKET_NAME,
Key: key, // 파일명 + 경로
Body: imageData, // Buffer 객체
ContentType: 'image/jpeg',
ACL: 'public-read',
};
await saveS3(uploadParams); // 이미지 데이터를 S3에 업로드
const filePath = `https://${process.env.S3_BUCKET_NAME}.s3.${process.env.S3_REGION}.amazonaws.com/${key}`;
const newImage = {
fileName: key,
path: filePath,
};
const createImage = await imageModel.create({ newImage });
return createImage;
}🌟 만족했던 점
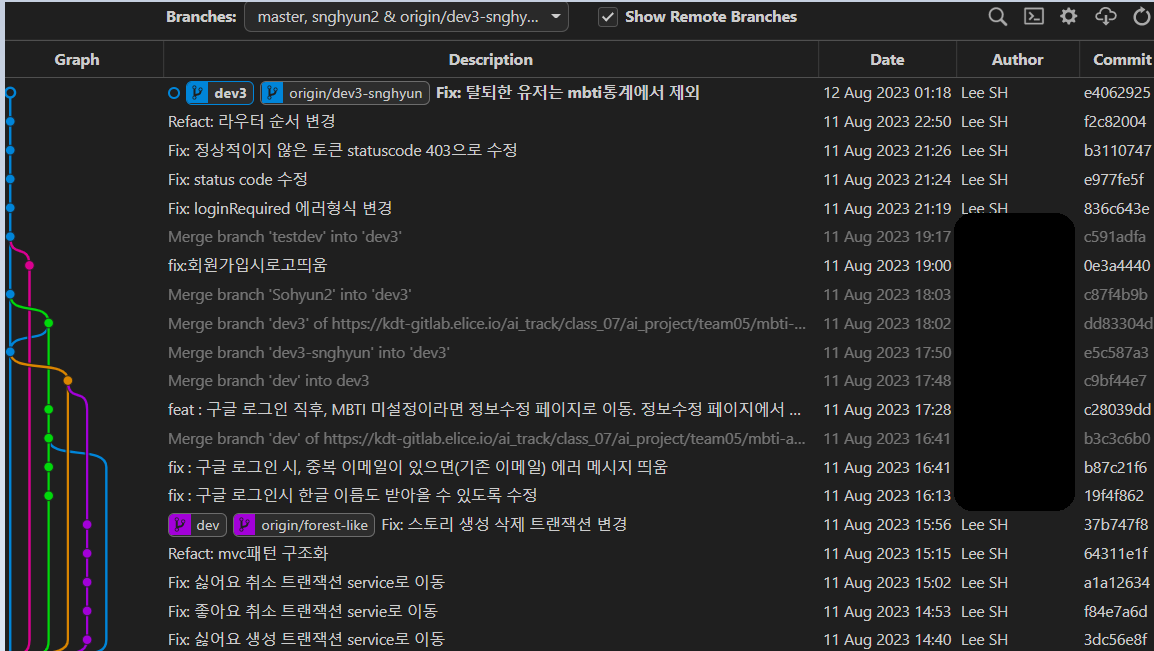
👍 깃랩 관리
이전 회고 때 언급했던 것처럼 1차 프로젝트 당시에는 VsCode Live Share 확장 프로그램을 쓰느라 깃랩 관리가 전혀 안되고 있었다. 따라서 여유시간을 활용하여 별도로 Git을 공부하며 commit, push, pull, merge에 대한 이해를 높였고 팀에서 정한 커밋 컨벤션 규칙을 따라 3차 때 총 190번의 커밋을 수행했다.
👍 Prettier 적용
Prettier는 코드 스타일을 일관성 있게 유지하며 들여쓰기, 따옴표 사용, 줄바꿈 등을 자동으로 조정하여 통일된 코드를 생성할 수 있다.
Prettier을 사용함으로써 수동으로 코드 스타일을 맞추는 과정이 필요없어 시간을 절약할 수 있었고 merge과정에서 스타일로 인한 불필요한 충돌 이슈가 전혀 없었다.
🌟 아쉬웠던 점
🧨 3계층 구조로 코드를 명확하게 작성하는 연습이 필요
3계층 구조의 역할 간단 정리
● Router(Controller) - Service - Model로 나눈다고 했을 때
● Router(Controller)는 사용자의 Request에서 필요한 데이터(Query, Param, Body 등)를 뽑아내서 Service로 전달하고 완료 된 결과 값을 사용자에게 전달하는 역할을 한다.
● Service는 Router로 부터 전달 받은 데이터를 바탕으로 비즈니스 로직을 수행하는 역할을 한다.
○ DB에 저장할 형태로 데이터를 가공 (예: 패스워드 해시)
○ 각종 예외처리 (예: 존재하지 않는 데이터를 읽거나 수정, 삭제하려는 경우)
○ DB 이 외의 외부 서비스를 이용해야 되는 경우, 해당 로직 처리 (예: 회원가입 시 인증 메일 발송)
○ Service는 하나의 Model만 사용하는 것이 아니라, 여러 Model 또는 다른 Service를 활용하여 로직을 구현할 수 있다. (예: 회원 탈퇴를 구현할 경우 단순히 UserService에서 User 데이터만 삭제하는 것이 아니라, 해당 User와 관련 된 모든 정보 (예: Order, Article, Comment)를 한꺼번에 처리해줘야 함
● Model은 DB와 인터렉션하며 데이터를 저장하거나 데이터를 읽어오는 역할을 한다.위 정리글을 참고했을 때 3계층 간의 경계가 모호하게 작성된 코드가 많았다.
- controller에서 model을 직접 호출하는 경우가 있음
- DB관련 코드(예: populate)가 controller에도 있고 service에도 있음
... 등등
Controller에서는 req에서 필요한 데이터를 파싱한 후 나머지는 Service에서 처리하도록 수정하는 것이 필요할 듯하다.
🧨 응답 및 에러 코드 통일
백엔드 역할을 각각의 페이지(회원정보관리, 스토리, 대나무숲)로 분담하여 작업했는데, 프로젝트 초반에 응답과 에러 코드 처리에 대한 충분한 논의가 이루어지지 않아 응답과 에러 처리 관련 코드를 전체적으로 일관성 있게 통일하지 못했다.
다음 프로젝트에서는 prettier뿐만 아니라 응답/에러 처리에 관련해서도 의논해야할 것 같다.
🌟 시도해보고 싶은 것
-
HTTPS사용
백엔드 개발자의 역할은 API를 개발하는 것 뿐만 아니라, 그 API를 통해 안전하게 데이터를 전달하기 위한 서버를 구축하는 일도 매우 중요하다.
이전까지 제작한 프로젝트들은 모두 HTTP 서버로 배포되었지만, 앞으로는 HTTPS를 적용해보고 싶다. -
커서 기반 페이지네이션
프로젝트에서 데이터를 조회하는 모든 기능에 일괄적으로 오프셋 기반 페이지네이션을 적용했었다.
이 프로젝트 특성 상 SNS처럼 실시간으로 빠르게 데이터가 추가되고 삭제되는 경우도 별로 없을 것 같고, 데이터 양도 그리 많지 않을 것 같아 간단한 방법인 오프셋을 선택했지만 실제 서비스를 개발할 때는 대용량 데이터를 데이터 유실 없이 조회할 수 있는 커서 기반 페이지네이션을 구현하게 될 확률이 높을 것 같아 다음번에는 커서기반 페이지네이션도 한번 구현해보고 싶다.
🌟 마치며
프로젝트 마지막까지 밤을 새며 에러를 잡고 좋은 결과를 얻어낼 수 있었다. 최종 순위는 내일 발표나겠지만 우수 발표팀에 선정된 것 만으로도 충분히 기뻤다 ㅎㅎ 최선을 다해준 우리 팀원들 모두 고생많았다!
3차 프로젝트를 끝으로 엘리스에서의 6개월 여정이 마무리되었다. React와 Node에 대해 1도 몰랐던 내가 이제는 인공지능 웹 서비스를 만들 수 있는 개발자가 된 것이다. 부트캠프 수료만으로는 아직 부족한 실력이지만 앞으로 계속 공부하면서 더욱 성장한 개발자가 되도록 노력하겠다!

많은 도움이 되었습니다, 감사합니다.