
🏃♀️ 들어가며...
신입 백엔드 개발자로 입사한 지 벌써 3개월이 지났다. 3개월의 수습 기간 끝에 정직원 전환이 된 기념으로, 수습 때 진행했던 프로젝트에 대한 회고록을 작성해보려 한다.
💥 기존 검색 쿼리 시스템의 문제
Like 함수 → Elasticsearch로 검색 성능을 개선하자
기존의 회사 어드민 페이지의 데이터를 검색하는 방법은 SQL문의 Like 연산자를 아용하여, 사용자가 특정 검색 키워드를 입력하면 해당 키워드를 포함하거나 일치하는 일치하는 모든 레코드(데이터)를 출력하고 있었다.
// Like문 예시
// 상품명이 '멍멍이' 텍스트가 포함되어있는 모든 데이터를 출력
SELECT *
FROM products
WHERE name LIKE '%멍멍이%'데이터베이스 시스템에 있는 데이터를 Row(행) 단위로 한 줄씩 저장시키게 되고 like검색을 사용하게 되면, 테이블의 첫 행부터 마지막 행까지 전체 데이터를 탐색하면서 데이터를 찾아내야 한다. 따라서 탐색해야 될 데이터들이 많아지게 되면 시간도 오래 걸리고 데이터를 모두 읽어야 하기 때문에 속도가 더 느릴 수 있다. 더욱이, 시간이 흐를수록 어드민 페이지에 데이터가 계속해서 쌓이는 구조 상, 앞으로 데이터를 검색하는 데 소요되는 시간이 점차 길어질 것이라고 예측되어, 이 문제를 해결하고자 했다.
Elasticsearch의 간단한 소개 및 검색 원리
※ ELK(=Elasticsearch+Logstash+Kibana) : 데이터 분석에 필요한 모든 유형의 데이터를 실시간으로 검색, 분석, 시각화할 수 있는 데이터 분석 플랫폼
Elasticsearch는 어떤 특정한 정보를 찾으려 할 때 키워드를 중심으로 저장되기 때문에 빠른 검색을 자랑한다.
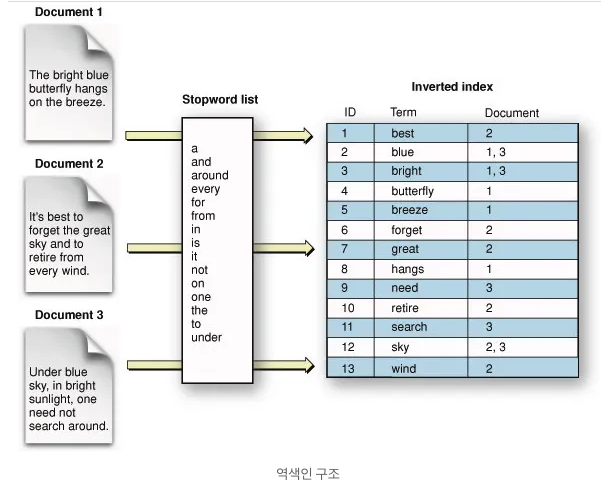
Elasticsearch는 데이터를 저장할 때, 위와 같이 역 인덱스(inverted index) 라는 구조로 만들어 데이터를 저장한다. 이 때 여기서 특정 문장의 단어를 분석하여 key-value 형식의 JSON으로 변환하여 저장한다. 각각 저장된 문서를 'document'라고 한다. 이를 통해 특정 단어가 어느 위치에 있는지를 파악할 수 있다.
예를 들어 sky 라는 단어를 검색하게 되면, 전체 데이터를 모두 읽을 필요 없이 2, 3번 document로 바로 찾아가게 되므로 빠른 속도로 검색 결과들을 찾아낼 수 있다.
※ 반면에, like 연산자를 활용한 텍스트 검색은 테이블의 모든 데이터에 순차적으로 접근하면서 찾고자 하는 문자열(sky)이 있는지 일일히 확인해야한다.
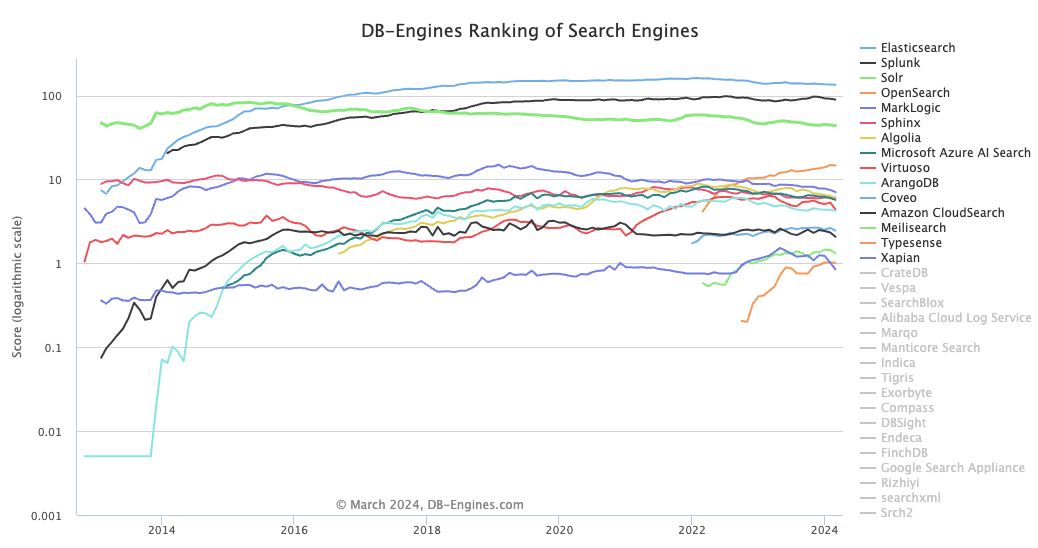
Elasticsearch 도입 이유
- 현재 검색엔진 중, 독보적인 랭킹 1위 & 문서(doc) 업데이트도 활발
출처 : DB-Engines Ranking
- Logstash를 활용하여 실시간으로 인덱싱 후 Elasticsearch에 빠르게 저장 및 검색 가능
Elasticsearch 검색 엔진을 도입해 검색 속도를 향상시킨 외부 기업 사례
1) 사례 1 - [Fitpet Mall] ES 검색엔진을 활용한 상품 검색
- 해당 프로젝트 진행 목적과 가장 유사한 사례
- 상품 검색 시 데이터베이스에 있는 데이터를 검색하는 방식을 사용
SELECT * FROM products WHERE name LIKE ‘%멍멍이%’→ 상품에 대한 데이터가 많아지다 보니 해당 쿼리의 속도가 느려져 상품을 검색하는 데 소요되는 시간이 점차 늘어나는 문제 발생 → 속도 개선 필요 - 이전 방법(RDBMS)
- 응답 시간 약 200~300ms 소요
- 데이터 테이블 크기가 크면 클수록 소요되는 시간 증가
- 이후 방법(Elasticsearch)
- 응답 시간 약 50ms 내외 소요
- 인덱스 크키가 커져도 역 색인 구조로 인한 검색 성능 저하 미미
2) 사례 2 - [NHN Cloud] 엘라스틱 서치를 이용한 상품 검색 엔진 개발 일지
3) 사례 3 - [크몽] 크몽 검색 기능 개선기
아키텍처
BEFORE
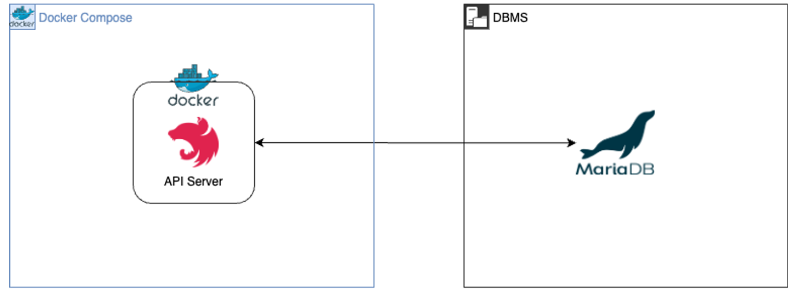
AFTER
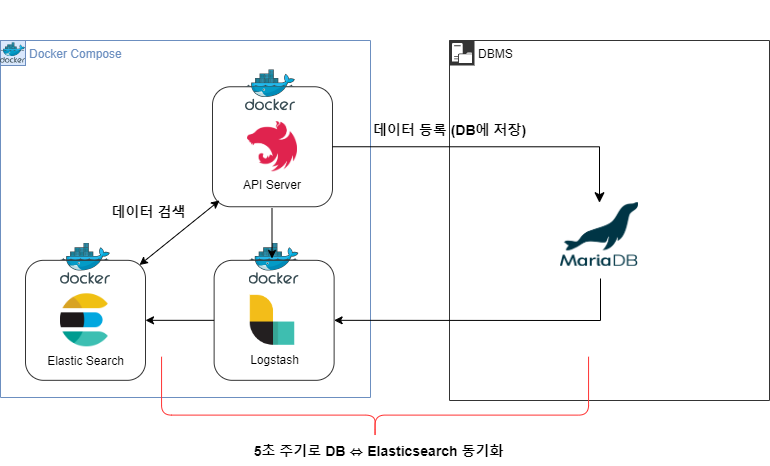
- DB에 새로 추가된 데이터만을 트래킹(tracking)하여 5초 간격으로 Elasticsearch에 동기화하여 저장
- Elasticsearch 인덱스에 저장된 데이터는 Node.js 서버의 API 호출 시 검색된다.
Elasticsearch, Logstash 개발 환경 구축
Docker compose를 활용해 Elasticsearch와 Logstash 서버 환경을 구축했는데, 자세한 내용 및 구현 코드는 아래 포스팅에서 정리하였다.
↓
Docker Compose를 활용한 Elasticsearch, Logstash 개발 환경 구축
NodeJS와 Elasticsearch 연결하기
npm install @elastic/elasticsearch@8.13.0- Docker 버전과 동일한 8.13.0을 설치하였다.
import { Client } from '@elastic/elasticsearch';
export const ELASTICSEARCH_CONFIG = new Client({
node: 'http://es01:9200',
maxRetries: 5,
requestTimeout: 60000,
sniffOnStart: true,
});elasticsearch를 연결하고,
const dataInfo = await ELASTICSEARCH_CONFIG.search({
index: "인덱스명",
// 오프셋 페이지네이션
from: (pageNo - 1) * perPage,
size: perPage,
query: {
bool: {
must: mustQueries,
must_not: mustNotQueries,
filter: filterQueries,
},
},
});node.js의 search api에서 검색이 되도록 쿼리 검색 로직을 구현하였다.
Elasticsearch는 must, must_all, term, match, match_phrase 등의 다양한 쿼리를 활용하여 여러 조건으로 검색할 수 있기 때문에, 빠른 검색 속도 뿐만 아니라 사용자가 원하는 결과를 정확히 도출할 수 있는 것도 큰 장점이다.
(참고)
초심자들을 위한 Elastic Search 시작하기 (with NodeJS)
wildcard? tokenizer?
검색 속도는 향상시키면서, 기존의 어드민 페이지의 검색 결과와 거의 동일한 결과를 얻기 위해 처음 고안한 방법은 wildcard을 활용하는 것이었다.
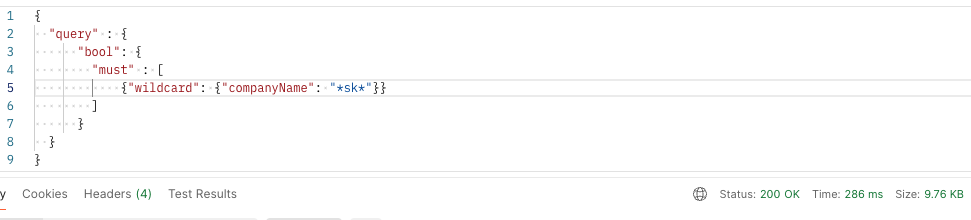
그러나 wildcard 방식은 SQL의 "Like" 연산자와 유사하여, 위 이미지와 같이 286ms, 평균 약 250ms 정도의 응답 시간이 나와 기존 방식과 유사한 성능을 띄었다.
따라서 wildcard 대신, LIKE 검색과 유사하게 색인할 수 있는 ngram을 적용한 커스텀 tokenizer을 적용해보았고, 테스트 해본 결과 13ms의 응답 시간을 기록하여 wildcard 방식 대비 95.36% 정도 감소했다.
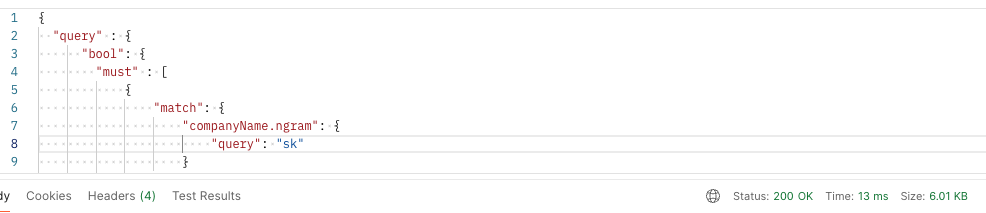
(참고)
https://findstar.pe.kr/2018/07/14/elasticsearch-wildcard-to-ngram/
결과
응답 속도 개선
30명의 유저가 1초만에 2번 반복해서 에러가 발생해도 계속 요청을 보내도록 설정 후 테스트 진행
<prod 서버 - ELK 미적용>
- 응답 시간 평균 37ms

<test 서버 - ELK 적용>
- 응답 시간 평균 19ms

✅ 동일한 DB환경에서 운영 서버(ELK 미적용)과 테스트 서버(ELK 적용)에 대해 응답 시간을 비교한 결과, 운영 서버의 평균 응답 시간은 37ms, 테스트 서버의 평균 응답 시간은 19ms로 차이가 있음을 확인. (검색 결과는 동일하게 나오도록 설정)
✅ 점점 데이터가 쌓이더라도, 데이터 양에 상관없이 예전과 같이 짧은 응답 시간을 유지할 수 있게 될 것
검색 품질 개선
1. 띄어쓰기 및 대소문자 구분없이 검색이 가능하여 사용자 편의성 증대
(이미지는 보안 상 첨부X)
"analyzer": {
"my_ngram_analyzer": {
"tokenizer": "my_ngram_tokenizer",
"filter": ["lowercase"]
}
},{
"analysis": {
"char_filter": {
"whitespace_remove": {
"type": "pattern_replace",
"pattern": "\\s+",
"replacement": ""
}
},
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lowercase"],
"char_filter": ["whitespace_remove"]
}
}
}
}- 예를 들어 'sk 하이닉스' or 'SK 하이닉스' or 'sk하이닉스' or 'SK하이닉스'로 검색해도, 똑같이 "SK 하이닉스"와 관련된 데이터가 검색된다.
2. 검색어와 관련도 높은 순으로 정렬하여 정확한 검색 결과 제공

- 저 score값이 높은 순으로 document을 정렬하여 검색 우선 순위를 조정하였다.
💥 문제상황: DB에서 삭제된 데이터는 트래킹이 불가능하다.
Logstash에서는, 최근 폴링한 시점을 기록하여 새로 추가된 데이터를 트래킹하여 엘라스틱 서치에 적재한다. 하지만 DB에서 데이터가 삭제되었을 때, 해당 데이터를 트래킹하여 엘라스틱 서치에도 삭제되도록하는 트래킹 방법을 따로 지원하지는 않고 있다.
삭제 임시 보관함에 들어간 데이터들은 30일 이후 일괄적으로 삭제된다.
삭제 임시 보관함에 데이터가 Insert될 경우, dataAvail 필드에는 insert된 날짜의 timestamp가 찍히고 있다(delete api). 즉, delete 요청(삭제 임시 보관함 insert) 요청이 들어왔을 때 직히는 날짜
여기서 3가지 방법을 생각해보았다.
- DB 삭제 이벤트가 발생했을 때, 직접 엘라스틱 서치에 해당되는 문서의 삭제 요청을 날린다.
- 즉 DB에서 데이터가 Hard Delete으로 삭제될 때, 엘라스틱 서치에서도 해당 데이터들이 함께 삭제되도록 service 로직에 코드 추가 🧡
-
파이프라인에 dataAvail에 찍힌 날짜가 현재 난ㄹ짜에서 30일 이전일 경우 자동으로 삭제
→ DB와의 동기화가 제대로 되지 않는 문제가 발생할 수 있음 -
삭제 임시 보관함에 들어가는 데이터의 수가 그리 많지 않아, 따로 자동 삭제 기능을 추가하지 않고 나중에 일괄적으로 수동으로 삭제하는 방법
간편성을 고려했을 때 1번이 나아보여, "1번"을 채택했다.
구현 과정
// repository.ts
/* 삭제 대상 Q&A 리스트를 삭제(Hard-Delete)하는 요청 */
async deleteDataList(idxList: number[]): Promise<void> {
await this.dataModel
.createQueryBuilder()
.withDeleted()
.delete()
.from(DataEntity)
.where('dataIdx IN (:...idxList)', { idxList })
.execute();
}
-----------------------------------------------
// service.ts
await dataService.deleteDataList(idxList)
await ELASTICSEARCH_CONFIG.deleteByQuery({
index: 'main-test01',
body: {
query: {
terms: {
_id: idxList,
},
},
},
});-
service 로직에서, DB에 데이터가 삭제된 후 곧바로 엘라스틱 서치에서 해당 데이터들을 삭제하는 프로세스로 구현했다.
-
하지만 위 코드를 구현 중 문제가 발생하였다.
Promise.all로 구현 중, 어느 한쪽의 Promise에 InterneException 에러를 강제로 발생시키면, 다른 한쪽에서는 삭제가 정상적으로 이루어지는 이슈
const deleteFromDBPromise = this.dataSchedulerRepository.deleteDataList(idxList); const deleteFromElasticPromise = this.dataSchedulerRepository.deleteDataListFromElastic(idxList); const [isDeletedFromDB, isDeletedFromElastic] = await Promise.all([ deleteFromDBPromise.catch((err) => { throw new BadRequestException('DB에서 삭제하는 중 에러 발생: ' + err.message); }), deleteFromElasticPromise.catch((err) => { throw new BadRequestException('Elastic에서 삭제하는 중 에러 발생: ' + err.message); }), ]); if (!isDeletedFromDB || !isDeletedFromElastic) { // 하나라도 False가 나올 경우 throw new BadRequestException('data 삭제가 정상적으로 이뤄지지 않았습니다'); }➡ "트랜잭션"이 필요해보임
// repository.ts /* 삭제 대상 Q&A 리스트를 삭제(Hard-Delete)하는 요청 */ async deleteDataList(idxList: number[]): Promise<void> { return this.dataModel.manager.transaction(async (manager) => { await manager .createQueryBuilder() .withDeleted() .delete() .from(DataEntity) .where('dataIdx IN (:...idxList)', { idxList }) .execute(); await ELASTICSEARCH_CONFIG.deleteByQuery({ index: 'main-test01', body: { query: { terms: { _id: idxList, }, }, }, }); // throw new InternalServerErrorException(); 🍀 }); }- Querybuilder, Manager Transaction을 사용
deleteQnaList()함수 안에 DB에서 데이터를 삭제하는 로직과 Elasticsearch에 데이터를 삭제하는 로직을 포함- 🍀 정상 작동 확인!
Lesson Learned
✔ "역시 프로젝트의 최종 보스는 기술 스택 세팅"
ELasticsearch와 Logstash 세팅(파이프라인 포함)부분이 제일 어려웠던 것 같다. 2~3시간 걸린다고 생각했는데, 1주일이 넘게 걸렸다. Volume 이슈, 설정 이슈 등 자잘한 이슈들이 많이 있었다
✔ 이슈 관리 & 코드 리뷰
사이드 프로젝트를 했을 때와 다르게, 이슈 및 마일스톤 관리와 일관된 커밋 메세지 작성에 더욱 신경을 썼다. 특히 팀원들에게 현재 내가 어떤 이슈를 진행 중인지 공유하기 위해 Feature, Modify, HotFix, Deploy, Setting 등 새 작업을 시작할 때 꼭 이슈를 등록하였다. 이슈 관리는 협업 과정에서 매우 중요한 일 중 하나라고 생각한다.
그리고 PR을 올릴 때 반영하고자 하는 브랜치명, 관련 이슈 목록, 특이사항 등을 포함한 PR 템플릿을 함께 추가하여 리뷰어(Reviewer)가 변경된 코드를 쉽게 파악할 수 있도록 했다.
무엇보다 코드리뷰가 굉장히 도움이 많이 되었다. 심플하고 사소한 코드라도 "왜 사용했지?" 라는 질문을 계속 던져주게 함으로써 코드의 목적과 사용 의도를 명확히 이해하고 더 나은 해결책을 찾을 수 있게 도와주셨다. 👍
✔ Commit 하기 전, 코드가 잘 변경되었는지, 테스트로 사용한 주석을 잘 해제했는지 등 꼼꼼하게 살피기
✔ 로컬 환경에서 개발 → 테스트 서버로 배포하기 까지의 과정을 경험
- 테스트 서버는 여러 개의 Back 서버가 운영되고 있다. → 각 서버가 동일한 작업을 수행하려고 할 때 충돌 현상이 발생
→ Redis의 분산 락을 적용하여 충돌 해결 - 로컬과 테스트 각각의 환경에 맞게 Docker compose 파일을 수정해야한다.
보완해야할 부분
실시간으로 바로 검색이 되어야 한다
- 기존에는 데이터가 등록되면 바로 DB에 저장되기 때문에 데이터가 등록되면 그 즉시 검색이 가능했지만, 현재 프로젝트에서는 데이터가 등록된 후 5초 뒤에 적재가 되기 때문에 실시간으로 바로 검색이 불가능하다.
schedule => "*/5 * * * * *" - 매초마다 적재되도록 설정하면 데이터베이스 부하가 일어날 수 있기 때문에, DB에 이벤트가 일어날 때마다 적재될 수 있게 하는 트리거 기능을 알아보는 중이다. (하지만 레퍼런스가 별로 없어 쉽지는 않아보인다..)
단일(single) 노드 → 다중(multi) 노드
- 한정된 시간으로 처음부터 다중 노드로 구현하기 보다는, 먼저 작동이 잘 되는지 부터 빨리 확인하기 위해 단일 노드로 구현했었다.
- 개발환경 또는 테스트를 진행하기 위해서는 엘라스틱서치의 단일(single) 노드로도 충분하지만, 실제 운영 환경에서는 엘라스틱 서치 중단 이슈 등을 대비하기 위해 여러 노드를 구성하는 것이 더 안전하다.
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:8.13.0
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- ./elastic/es01/data:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
-
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:8.13.0
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- ./elastic/es02/data:/usr/share/elasticsearch/data
networks:
-
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:8.13.0
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- ./elastic/es03/data:/usr/share/elasticsearch/data
networks:
-향후 계획
검색 품질 고도화
- 한국어의 특성을 반영하여 정확하게 토큰화를 수행하는 Nori Tokenizer도 함께 적용하여 한국어 텍스트를 보다 효과적으로 분석하고 검색 품질을 향상시켜볼 수 있을 것이다.
Elasticsearch을 활용한 추가 검색 기능 구현
- Elasticsearch를 활용하면 검색 속도를 개선하고, 맞춤법 교정 / 연관 검색어 / 자동 완성 기능을 개발할 수 있다.
- 만약 어드민 페이지에 적용한다면, 관리자가 자주 찾는 검색어를 완전히 입력하지 않고도 원하는 검색어를 선택할 수 있도록 '자동 완성' 기능을 우선 도입하고자 한다.
- 꼭 어드민 페이지가 아니더라도, 다른 페이지에서도 엘라스틱 서치를 적용하게 된다면 위 3가지의 기능을 구현해보고 싶다.
Kibana 대시보드 개발
- ELK 스택 중 하나인 키바나 대시보드를 활용하여, 엘라스틱 서치에 적재되어있는 데이터로 유의미한 인사이트를 도출해 사내 의사결정을 지원하는 서비스를 제작하고자 한다.
References
https://velog.io/@alli-eunbi/Elastic-Search-%EC%8B%9C%EC%9E%91%ED%95%98%EA%B8%B0-with-NodeJS
https://findstar.pe.kr/2018/07/14/elasticsearch-wildcard-to-ngram/
https://wonyong-jang.github.io/elk/2021/02/08/ELK-Elastic-Search4.html
