
1. redis 란
- 레디스는 고성능 키-값 저장소로서 문자열, 리스트, 해시, 셋, 정렬된 셋 형식의 데이터를 지원하는 NoSQL
인메모리 데이터베이스- Redis에 모든 데이터를 메모리에 저장하는 빠른 DB가 다라고 생각할지도 모릅니다. 하지만 빠른 성능은 레디스의 특징 중 일부분 입니다. 다른 인메모리 디비들과의 가장 큰 차이점은
레디스의 다양한 자료구조 - 다양한 자료구조를 지원하게 되면
개발의 편의성이 좋아지고 난이도가 낮아진다
는 장점 - 어떤 데이터를 정렬을 해야하는 상황이 있을 때, DBMS를 이용한다면 DB에 데이터를 저장하고, 저장된 데이터를 정렬하여 다시 읽어오는 과정은 디스크에 직접 접근을 해야하기 때문에 시간이 더 걸린다는 단점이 있습니다. 하지만 이 때
In-Memory
데이터베이스인Redis
를 이용하고 레디스에서 제공하는Sorted-Set
이라는 자료구조를 사용하면 더 빠르고 간단하게 데이터를 정렬할 수 있습니다.
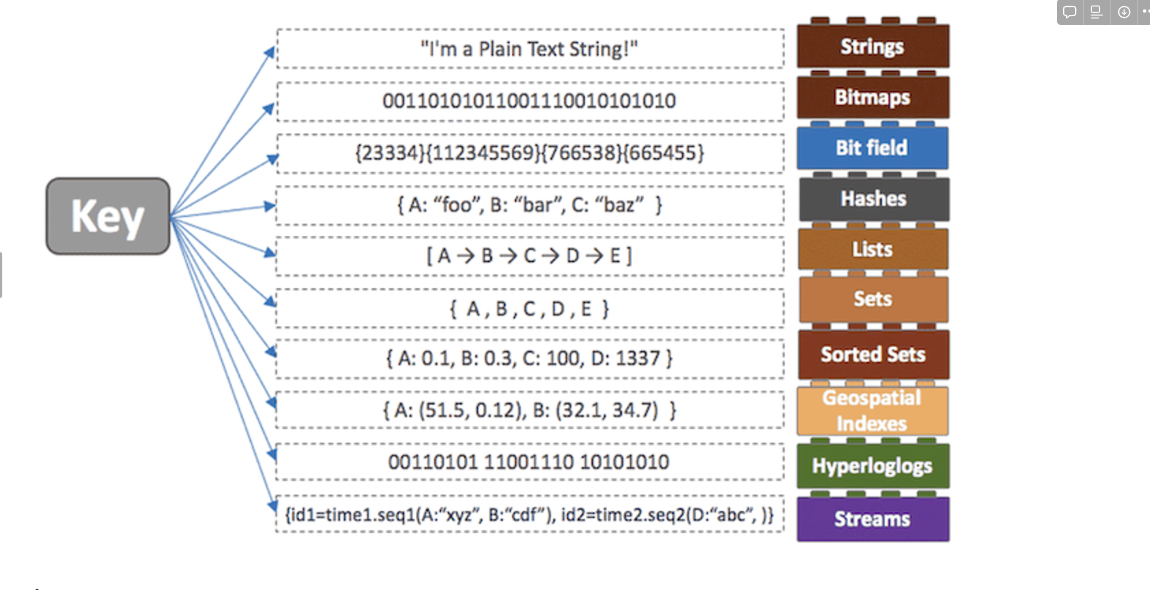
특징
NoSQL로서 Key-Value 타입의 저장소인 레디스(Redis, Remote Dictionary Server)의 주요 특징은 아래와 같습니다.
영속성을 지원하는 인메모리 데이터 저장소읽기 성능 증대를 위한 서버 측 복제를 지원쓰기 성능 증대를 위한 클라이언트 측 샤딩(Sharding) 지원다양한 서비스에서 사용되며 검증된 기술문자열, 리스트, 해시, 셋, 정렬된 셋과 같은 다양한 데이터형을 지원. 메모리 저장소임에도 불구하고 많은 데이터형을 지원하므로 다양한 기능을 구현
2. 데이터 저장형식
[REDIS] 📚 캐시 데이터 영구 저장하는 방법 (RDB / AOF)
- 메모리에 저장하는 방식으로 사용 but 메모리의 데이터를 disk에 저장할수도 있음
그래서 서버가 꺼진 후 restart되더라도, disk에 저장해놓은 데이타를 다시 읽어서 메모리에 로딩하기 때문에 데이타 유실되지 않는다.
이런 Persistent(영속성) 기능은 휘발성 메모리 DB를 데이터 스토어로서 활용한다는 장점이 있지만 이 기능 때문에 장애의 주 원인이 되기도 한다.
그러므로 이 기능을 잘 알아보고 사용하는게 중요하다.
redis에서는 데이타를 저장하는 방법이 RDB (snapshotting) 방식과 AOF (Append only file) 두가지가 있다.
- RDB 방식은 특정한 각격마다 메모리에 있는 레디스 데이터 전체를 디스크에 쓰는 것이다. (백업에 용이)
- AOF 방식은 명령이 실행될때 마다 데이터를 파일에 기록하여 데이터의 손실이 거의 없다.
- Redis는 인메모리 데이터를 주기적으로 파일에 저장하는데, Redis 프로세스가 장애로 인해 종료되더라도 해당 파일을 읽어들이면 이전의 상태를 동일하게 복구할 수 있다.
- 우리가 직접 세팅하지 않더라도 Redis는 자동으로 .rdb 라는 확장자의 파일에 인메모리 데이터를 저장하도록 디폴트 설정 되어있다.
- RDB 방식은 메모리의 snapshot을 그대로 저장하기 때문에 서버를 재구동시할 때 snapshot을 다시 읽으면 되므로 속도가 빠른 장점이 있다.
- 그러나, snapshot을 추출하는데 시간이 오래걸리고 도중에 서버가 꺼지면 이후의 데이터를 모두 사라진다는 단점이 있다.
- 실제로 SAVE 옵션으로 50GB 의 메모리 상태를 저장한다면 7 ~ 8분 정도 소요
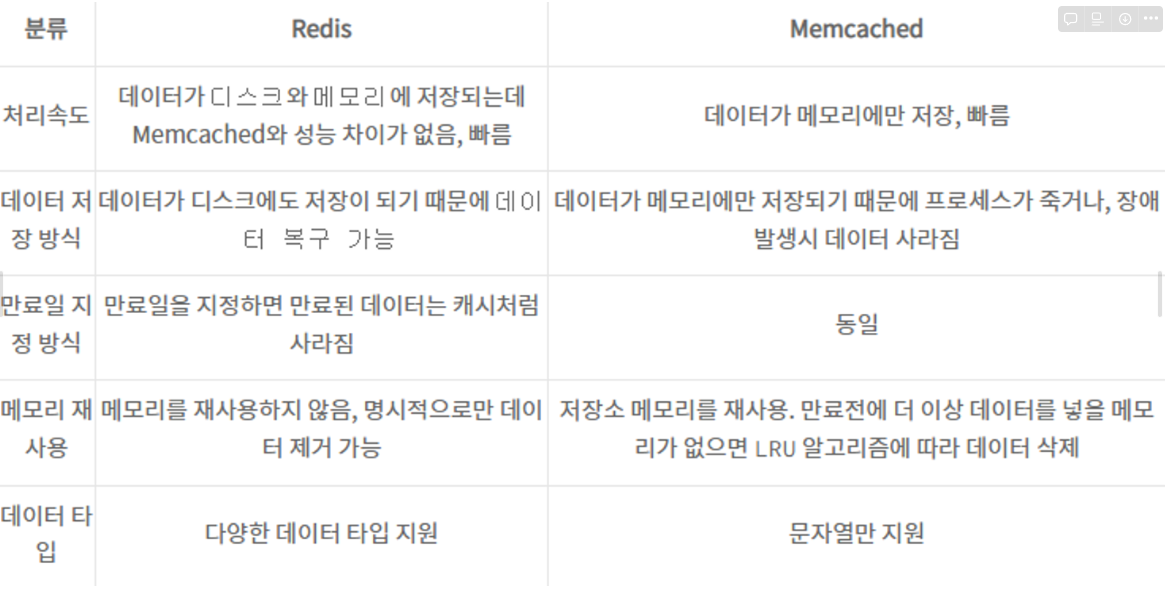
3. 장단점, 활용시 고민 사항
장점
- 리스트, 배열과 같은 데이터를 처리하는데 유용 value 값으로 다양한 데이터 형식을 지원하기 때문
- 리스트형 데이터 입력과 삭제가 MySql에 비해 10배정도 빠르다. 여러 프로세스에서 동시에 같은 key에 대한 갱신을 요청하는 경우, 데이터 부정합 방지
Atomic처리 함수를 제공한다(원자성).
- 메모리를 활용하면서 영속적인 데이터 보존(
Persistence) 명령어로 명시적 삭제, expires를 설정하지 않으면 데이터가 삭제되지 않는다.스냅샷기능을 제공해 메모리 내용을 *.rdb 파일로 저장하여 해당 시점으로 복구할 수 있다.AOF: Redis의 모든 Wirte/Update 연산을 log 파일에 기록 후 서버 재시작 시 순차적으로 재실행, 데이터 복구
- 1개의
싱글 쓰레드로 수행되기 때문에, 서버 하나에 여러개의 Redis Server를 띄울 수 있다.(Master-Slave 구조) master-slave 간의 복제는non-blocking
단점
- In-memory 방식이기 때문에 장애 발생시 데이터 유실이 발생한다.
- 따라서 영속적인 데이터 보존을 위해
스냅샷과 AOF기능을 통한 복구 방식을 주의해서 작성해야 데이터 유실에 대비할 수 있다.
활용시 고려 사항
1. 컬렉션 안에 너무 많은 아이템을 사용하지 않는다.
너무 많은 아이템을 사용하게 되면, 명령어 수행에 걸리는 시간이 증가하여 퍼포먼스가 떨어집니다.
따라서 1만개 이하 수준으로 유지합니다.
2. Expire 는 컬렉션의 item 개별에 걸리지 않고 전체 Collection에 대해서 걸린다.
3. 메모리를 철저하게 관리하라
레디스 서버가 피지컬 메모리 이상으로 사용하게 되면 장애가 발생한다.
피지컬 메모리 이상으로 사용하게 되면 스왑이 발생하는데, 스왑을 사용한 페이지가 존재하면 디스크를 사용하게 된다고 합니다.
디스크를 사용한 페이지가 존재하면 계속해서 디스크를 사용하게 됨으로 주의해야 합니다.
4. Redis 는 자기가 사용하는 정확한 메모리를 모른다. 모니터링은 필수
따라서 메모리 파편화가 발생하므로 모니터링을 통해서 메모리 관리를 해줘야 한다.
5. 작은 인스턴스 여러 개로 사용하라.
Redis를 사용하다보면 필연적으로 포크가 발생하는데, 이때 write 가 헤비한 Redis 는 메모리를 두 배까지 사용할 수 있게 되면서 퍼포먼스가 극단적으로 떨어질 수 있다고 한다.
6. 다양한 사이즈를 가지는 데이터보다 유사한 크기의 데이터를 사용하라.
메모리 파편화 때문인지 유사한 크기의 데이터를 사용하는게 관리에 유용하다고 한다.
7. Hash, Sorted Set, Set 은 메모리 사용이 많다. Ziplist 를 사용하자.
메모리 관리에서 유용해지나, 속도는 좀 더뎌지긴 한다. 돈이 많다면 사용해도 문제없다. Redis는 돈빨이다.
하지만 일정 개수까지는 속도를 보장한다. 일정 개수는.. 찾아보고 나중에 수정하겠습니다.
8. O(n) 관련 명령어에 주의하라.
싱글 스레드이므로, 시간이 오래 걸리는 명령어에 주의하라.
KEYS
FLUSHALL, FLUSHDB
Delete Collections
Get All Collections
프로덕션 환경에서 위와 같은 명령어는 자살 행위다. 따라서 명령어를 나눠서 수행할 수 있게 구성하라. 그래서 컬렉션을 나눠서 사용하는것을 권장하나 봅니다. 한번에 모든 데이터를 가져와야 되는 경우, 하나의 콜렉션이 너무 커버리면 O(n) 시간이 너무 커지므로, 패킷 대기 시간이 길어져 타임아웃 에러들이 줄줄줄 발생하게 되니깐 말이죠.
데이터를 호출할때는 하나당 몇천개 이내로만 호출하는 것이 좋습니다.
9. Redis Replication 을 사용할때 주의점들
9.1 now() 같은 명령어가 Primary에서 수행될때와 Secondary에서 수행될 때 값이 달라지는 경우가 생길 수 있다.
9.2 redis-cli --rdb 명령어는 메모리 스냅샷을 가지고 옴으로 서버가 죽을 수 있다.
9.3 Replication Lag 이 일정 이상 발생하는 경우 커넥션을 끊어버리고 다시 연결하는 과정에 많은 부하가 발생할 수 있다.
9.4 많은 대수의 Redis 서버가 Replica 를 두가 있다가 네트워크 이슈나, 여러 사람의 작업으로 동시에 Replication이 재시도 된다면 문제가 발생한다.
10. redis.conf 를 설정하라.
전체 장애의 99%가 특정 커맨드 사용으로 인해 발생한다고 합니다.
Maxclient 설정 50000
RDB/AOF 설정 off
특정 command disable
- keys
- save
11. Redis 데이터 분산
데이터의 특성에 따라 선택할 수 있는 방법이 달라집니다.
11.1 모듈러 방식
일반적으로 모듈러 분산을 사용하게 되는 경우 장비의 스케일 아웃 (장비 추가) 에 리밸런스가 발생하는데 이때 장애에 매우 취약합니다.
11.2 컨시스턴스 해싱
키 값을 해시해서 자신의 해시값보다 크지만 가장 가까운 서버로 데이터가 배치되는 방식입니다. 따라서 서버가 죽더라도 죽은 서버가 가지고 있는 값들만 변동이 있습니다.
12. 샤딩
데이터를 어떻게 나눌것인가, 데이터를 어떻게 찾을것인가는 동일한 문제입니다.
상황마다 샤딩 전략이 달라지는게 가장 쉬운 방식은 range 입니다.
12.1 range
범위에 따라서 분산하는데 이는 데이터 집중화 현상이 발생할 수 있습니다.
12.2 모듈러
서버를 확장할 때 서버 개수를 2의 배수로 확장하면, 데이터를 옮기 위치가 바로 결정되는 장점을 가지고 있습니다.
하지만 서버 확장시 2배로 키워야 된다는 돈의 압박이 있습니다.
12.3 인덱스
모든 서버를 인덱스 서버가 관리하는 것인데, 인덱스 서버가 다운되면 답도 없습니다. 이 부분에서도 분명히 인덱스 서버의 레플리카를 두는 방식을 취할수 있겠죠?.. 아마도 학습이 부족합니다.
13. Redis Cluster
자체적인 Primary Secondary Failover를 수행해줍니다.
슬록 단위의 데이터를 관리해줍니다.
메모리 사용량이 더 많은게 단점입니다.
마이그레이션 자체를 관리자가 결정해줘야 합니다.
라이브러리 구현이 필요합니다.
14. Redis Failover
장애 처리 방식은 대표적으로 3가지 방식을 이야기하셨습니다.
14.1 Coordinator 기반
14.2 VIP
14.3 DNS
15. 모니터링
모니터링 해야될 redis 정보는 rss, used memory, connection number, tps 입니다.
시스템에서는 cpu, disk, network rk 있습니다.
Redis 가 CPU 점유율을 100% 먹는 현상이 종종 발생한다고 합니다.
이 때 명령어 사용 패턴을 분석해서 장애 대응을 해야 합니다.
메모리 사용량이 3/4 이상 넘는다면 장비 증설을 고려해야 합니다.
Write 가 헤비하면 마이그레이션에 주의가 요망합니다.
16. Redis 를 영속성 저장소로 사용하면..
돈 많이 듭니다.
이 때는 메모리를 절대적으로 여유롭게 사용하는 것을 권장합니다.
정기적인 migration이 요구되며, RDB/AOF 가 필요하면 secondary에서 수행할 수 있도록 해야합니다.
4. redis 기본 명령어
Create
collection은 단순히 key, value 쌍으로 데이터를 저장하는 구조
- **SET : 단일 Key Set (기존에 값이 있으면 덮어씀)**
set "a" HappyKoo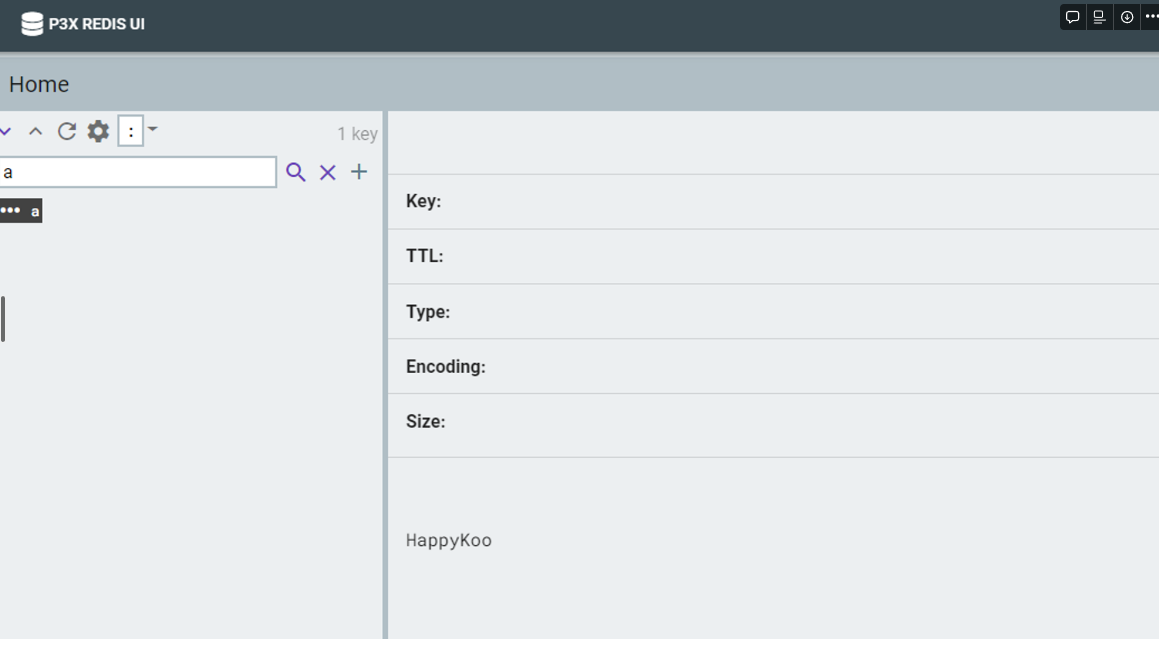
READ
- **GET : 단일 Key Get**
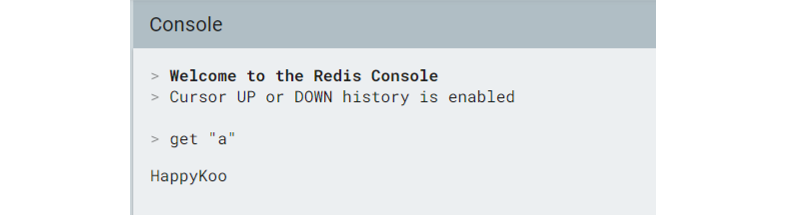
Delete
del "a"
- MGET : 멀티 Key Get (한 번에 여러 데이터 조회)
localhost:6379> mget (key1) (key2) ...
#예시
localhost:6379> mget "a" "b"
1) "Happy"
2) "Koo"
- Keys : 키 조회
localhost:6379> keys (pattern)
#예시 (키 전체 조회)
localhost:6379> keys *
1) "key1"
2) "a"
주의해야할 것이 redis server 운영 중에는 전체 키를 조회하는 keys * 명령을 절대로 수행해서는 안됩니다.
keys 명령은 모든 keys를 스캔해서 조회하기 때문에 key 수가 많을 경우 처리시간이 많이 소요되고, 그동안 다른 명령을 처리하지 못하기 때문입니다.
대신 scan 명령으로 일정 수의 키를 반복하여 수행해야합니다. (한번에 약 10개씩 조회)
localhost:6379> scan (cursor) (pattern) (count)
#예시
localhost:6379> scan 0
1) "0" #next cursor이며 모두 조회했을 경우 0
2) "key1"
3) "a"
- List
List Collection은 하나의 key에 여러 value들을 list로 저장하는 구조이며, 명령들은 다음과 같습니다.
LPUSH : list 왼쪽에 삽입
localhost:6379> lpush (key1) (value1 value2 ...)
#예시
localhost:6379> lpush "key1" "happy" "koo"
(integer) 2
LRANGE : 인덱스로 범위를 지정해서 리스트 조회
localhost:6379> lrange (key1) (startIndex) (endIndex)
#예시
localhost:6379> lrange "key1" 0 -1
1) "koo"
2) "happy"
startIndex를 0, endIndex를 -1으로 하면 리스트 전체를 조회합니다.
RPUSH : list 오른쪽에 삽입
localhost:6379> rpush (key1) (value1 value2 ...)
#예시
localhost:6379> rpush "key1" "good"
(integer) 3
localhost:6379> lrange "key1" 0 -1
1) "koo"
2) "happy"
3) "good"
LPOP : list 왼쪽에서 데이터를 가져오고 리스트에서는 삭제
localhost:6379> lpop (key1)
#예시
localhost:6379> lpop "key1"
"koo"
localhost:6379> lrange "key1" 0 -1
1) "happy"
2) "good"
RPOP : list 오른쪽에서 데이터를 가져오고 리스트에서는 삭제
localhost:6379> rpop (key1)
#예시
localhost:6379> rpop "key1"
"good"
localhost:6379> lrange "key1" 0 -1
1) "happy"
LLEN : list의 총 갯수를 조회
localhost:6379> llen (key1)
#예시
localhost:6379> llen "key1"
(integer) 1
LTRIM : 인덱스로 지정한 범위 밖의 데이터를 삭제
localhost:6379> ltrim (key1) (startIndex) (endIndex)
#예시
localhost:6379> rpush "key2" "a" "b" "c" "d"
(integer) 4
localhost:6379> lrange "key2" 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
localhost:6379> ltrim "key" 1 2
OK
localhost:6379> lrange "key2" 0 -1
1) "b"
2) "c"
ltrim을 사용할 때 Reverse index를 사용하고 싶으면 음수로 사용하면 되며, 없는 범위를 지정하면 모든 데이터가 삭제되니 주의해야합니다.
Set
Set Collection은 List Collection과 같이 하나의 key에 여러 value를 저장할 수 있으며,
다른 점은 데이터가 입력된 순서와 상관없이 저장되고 중복되지 않습니다.
Sets에서는 value를 member라고 부르며, 주로 데이터가 있는지 없는지 체크하는 용도로 사용됩니다.
SADD : Member를 추가 (value가 있으면 삽입되지 않음)
localhost:6379> sadd (key1) (value1 value2 value3 ...)
#예시
localhost:6379> sadd "key3" "a" "b" "a" "c"
(integer) 3
SMEMBERS : 집합의 모든 member 조회
localhost:6379> smembers (key1)
#예시
localhost:6379> smembers "key3"
1) "c"
2) "a"
3) "b"
SISMEMBER : 집합에 value가 있는지 확인
localhost:6379> sismember (key1) (value1)
#예시
localhost:6379> sismember "key3" "a"
(integer) 1
localhost:6379> sismember "key3" "d"
(integer) 0
SREM : 집합에서 member를 삭제
localhost:6379> srem (key1) (value1)
#예시
localhost:6379> srem "key3" "a"
(integer) 1
SPOP : 집합에서 무작위로 member를 가져옴(해당 member는 삭제됨)
localhost:6379> spop (key1) (count)
#예시
localhost:6379> spop "key3" 1
1) "c"
localhost:6379> smembers "key3"
1) "b"
SRANDMEMBER : 집합에서 무작위로 member를 조회(해당 member 삭제 안됨)
localhost:6379> srandmember (key1) (count)
#예시
localhost:6379> srandmember "key3" 1
1) "b"
localhost:6379> smembers "key3"
1) "b"
- Sorted Set(ZSet)
Sorted Set collection은 key 하나에 여러 개의 score와 value로 구성되고, value는 score로 sort되며 중복되지 않습니다.
만약 score가 같으면 value로 sort되며, 주로 랭킹을 보여주는 시스템을 구축할 때 사용됩니다.
ZADD : 집합에 score와 member 추가
localhost:6379> zadd (key1) (score1 memeber1 score2 member2 ...)
#예시
localhost:6379> zadd "key4" 0 "Happy" 2 "Koo" 1 "Good"
(integer) 3
- ZRANGE : index로 범위를 지정해서 조회
localhost:6379> zrange (key) (startIndex) (endIndex) (withscores)
#예시
localhost:6379> zrange "key4" 0 -1
1) "Happy"
2) "Good"
3) "Koo"
- ZRANGEBYSCORE : score로 범위를 지정해서 조회
localhost:6379> zrangebyscore (key) (min) (max) (withscores) (limit offset count)
#예시
localhost:6379> zrangebyscore "key4" 1 2
1) "Good"
2) "Koo"
- ZREVRANGEBYSCORE : score로 범위를 지정해서 큰 것부터 조회
localhost:6379> zrevrangebyscore (key) (max) (min) (withscores) (limit offset count)
#예시
localhost:6379> zrevrangebyscore "key4" 2 1
1) "Koo"
2) "Good"
- ZSCORE : member를 지정해서 score를 조회
localhost:6379> zscore (key) (member)
#예시
localhost:6379> zscore "key4" Good
"1"
- ZREM : 집합에서 member 삭제
localhost:6379> zrem (key) (member)
#예시
localhost:6379> zrem "key4" Good
(integer) 1
- ZREMRANGEBYSCORE : score로 범위를 지정해서 member를 삭제
localhost:6379> zremrangebyscore (key) (min) (max)
#예시
localhost:6379> zremrangebyscore "key4" "0" "2"
(integer) 2
- Hash
Hash collection은 key 하나에 여러 개의 field와 value로 구성됩니다. 명령은 다음과 같습니다.
HSET/ HMSET : field와 value 저장
localhost:6379> hset (key) (field value)
localhost:6379> hmset (key) (field1 value1 field2 value2 ...)
#예시
localhost:6379> hset "key5" "a" "Happy"
(integer) 1
localhost:6379> hmset "key5" "b" "Koo" "c" "Good"
OK
HGET/ HMGET : field로 value 조회
localhost:6379> hget (field)
localhost:6379> hmget (field1 field2 ...)
#예시
localhost:6379> hget "key5" "a"
"Happy"
localhost:6379> hmget "key5" "b" "c"
1) "Koo"
2) "Good"
HGETALL : key에 속한 모든 field와 value 조회
localhost:6379> hgetall (key)
#예시
localhost:6379> hgetall "key5"
1) "a"
2) "Happy"
3) "b"
4) "Koo"
5) "c"
6) "Good"
HKEYS/HVALS : key에 속한 모든 field/value 조회
localhost:6379> hkeys (key)
localhost:6379> hvals (key)
#예시
localhost:6379> hkeys "key5"
1) "a"
2) "b"
3) "c"
localhost:6379> hvals "key5"
1) "Happy"
2) "Koo"
3) "Good"
HDEL : field로 value를 삭제
localhost:6379> hdel (key) (field1 field2 ...)
#예시
localhost:6379> hdel "key5" "a"
(integer) 1
