
0305 KOSIS import-export-eda
str.split() : 시리즈에 있는 기능
x.split() 문자열에 있는 기능
판다스
씨본 (seaborn으로 처음 익히는 것 추천)
(맷플랏립, 씨본하고 판다스에 내장되어 있는 기능 위주로)
플랏리
plotly의 histogram (seaborn의 barplot과 유사한 기능)
= 차이점은, 수치형뿐 아니라 범주형도 가능
= aggregation(집계: count, 합계, 평균, 기술통계) 기능 덕분에
# histfunc == seaborn estimate 기능과 유사합니다
px.histogram(df_country,x="달러", y="국가권역", histfunc="sum")
# 디폴트가 count인데 y가 없으면 sum을 한다bar는 연산 기능 제공 x
근데 plotly도 오래 걸리니까 그냥 판다스에서 계산하고 사용하는거 추천
- 옵션 barmode = "group" 등등
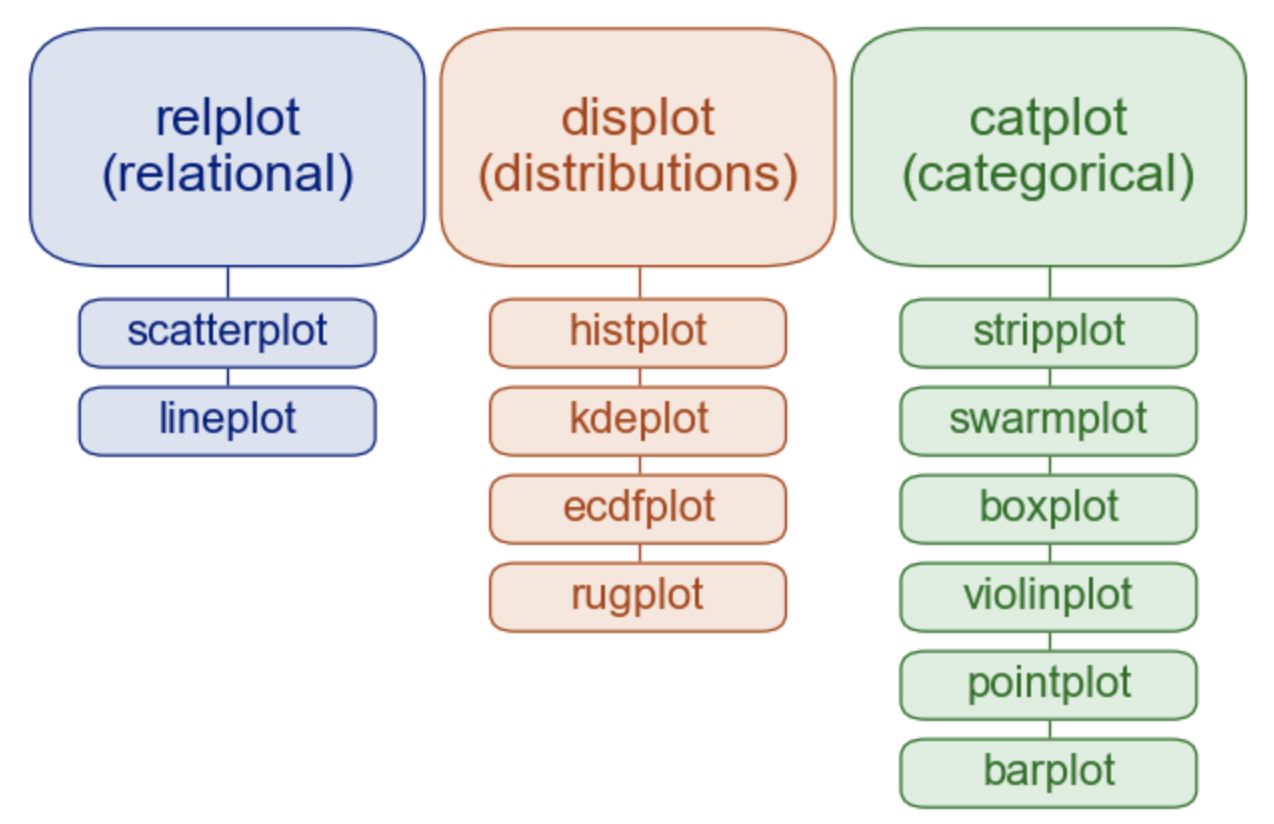
seaborn => 관계/분포/범주 표현 <- 중요
Q. 공공데이터 있는데 왜 유료 데이터 사용?
A. 의약품처방정보 데이터의 경우 시기성이 떨어지기 때문이다
0306 의약품처방정보 - 일부만 추출하기
- 밑에 더보기 클릭하면 컬럼 설명 볼 수 있다
전처리&EDA의 흐름
- 라이브러리 로드 및 데이터 불러오기
- 데이터 요약하기
- 데이터 전처리
- 데이터 요약: info, nunique, head, tail
- 결측치 처리/사용하지 않는 데이터 제거: isnull().sum(), dropna, drop
- 데이터 타입 변경: pd.to_datetime()
- 파생변수 만들기: 데이터 절약을 위해 줄여진 코드를 다시 쪼개서 변수로 만든다, 눈에 보기 편하게 직관적으로 바꾼다
- 시도명: 리스트컴프리헨션 (딕셔너리로도 가능), map, replace, split, int, str., str[]
- 연령대
- 성별
- 투여경로, 제형: pd.read_html, merge, strip
- 데이터 분석 및 시각화
- 기술통계
- 코드로 무슨 약인지 찾아서 보기
- 히스토그램, 상관분석
- 월별/일별/그룹별
isin()의 value로 이것저것 가능
values : iterable, Series, DataFrame or dict
The result will only be true at a location if all the
labels match. If values is a Series, that's the index. If
values is a dict, the keys must be the column names,
which must match. If values is a DataFrame,
then both the index and column labels must match.
샘플링하기 (넘파이, 판다스)
- 4기가에서 2-3기가만 가져와서 분석해보는 것
## 1. 넘파이로 하기
# 값을 고정할 때, 이렇게 고정하는 것을 권장
rng = np.random.default_rng(42)
sample_no = rng.choice(raw['가입자 일련번호'].unique(), 10000)
sample_no
## 2. 판다스로 하기
sample_no = raw["가입자 일련번호"].sample(10000, random_state=42)
# 값 고정시키기 위해서 랜덤값 고정 random_state = 42
# isin으로 샘플링한 가입자 일련번호 데이터만 추출하기
df_temp = raw[raw["가입자 일련번호"].isin(sample_no)]
df_temp.shape
# 전수조사 대신 표본을 샘플링해서 <표본조사>를 해서 보겠다~
df_temp["가입자 일련번호"].nunique()
# 만개가 되지는 않을 수도
# 왜냐? 샘플링해도 중복값이 있을 수도!
# 샘플링한 데이터 저장
# data/ <- 아래에 넣으면 데이터 관리가 더 편함
df_temp.to_csv("**data/**HP_2020_sample.csv", index=False)Q. 코드값으로 되어있는 이유?
A. 데이터 용량을 줄이기 위함이다
datetime으로 변환 : pd.to_datetime()
# 월, 일, 요일
df['월'] = df['요양개시일자'].dt.month
df['일'] = df['요양개시일자'].dt.day
df['요일'] = df['요양개시일자'].dt.dayofweek
df['영문요일'] = df["요양개시일자"].dt.day_name()리스트 컴프리헨션
# 해당 데이터에서 사용하는 대한민국 시도코드 정보입니다.
city = """11 서울특별시
42 강원도
26 부산광역시
43 충청북도
27 대구광역시
44 충청남도
28 인천광역시
45 전라북도
29 광주광역시
46 전라남도
30 대전광역시
47 경상북도
31 울산광역시
48 경상남도
36 세종특별자치시
49 제주특별자치도
41 경기도"""
# 넘어가는 줄로 쪼개기
city_list = city.split("\n")
# 딕셔너리 만들기 방법 1) 조은님 반복문 코드
for cl in city_list:
key = int(cl.split()[0])
value = cl.split()[1]
city_name[key] = value
# 딕셔너리 만들기 방법 2) 리스트 컴프리헨션을 사용하는 방법
city_name = {int(cl.split()[0]) : cl.split()[2] for cl in city_list}
# 딕셔너리 매핑해서 변환하기
df['시도명'] = df["시도코드"].map(city_name)map : 한꺼번에 적용할 때 편리
- pandas.Series.map
- 입력 대응에 따라 Series의 값을 매핑
- 매핑? 일정한 규칙에 따라 반복 가능한 객체를 변환시키는 것
- 함수, dict 등을 인자로 받음
Q. map 안에는 함수가 없어도 되나요?
넵 꼭 함수 뿐만이 아니더라도 매칭되는 딕셔너리도 map을 통해서 변환할 수 있습니다 🙂
파이썬 map(함수, 반복가능한 객체) 형식으로, 반복가능한 객체의 각 원소에 함수를 적용한다는 의미입니다.
map(f, l)은 결국엔 [f(l[0]), f(l[1]), f([2]), ...] 형식이 됩니다!
merge : 같은 변수 기준으로 데이터 합치기
df = df.merge(df_table, on="제형코드", how="left")
# how="left" : 오른쪽에 없는 것도 있더라도 다 머지를 해주겠다상관계수(변수들 간 상관관계 보기, 인과관계 x) 히트맵 그리기
-
corr() : 따로 method="pearson" 안해도 피어슨 상관계수 값
-
r 값은 X 와 Y 가 완전히 동일하면 +1, 전혀 다르면 0, 반대방향으로 완전히 동일 하면 –1 을 가진다
-
결정계수(coefficient of determination)는 r^2 로 계산하며 이것은 X 로부터 Y 를 예측할 수 있는 정도를 의미한다
-
<기준>
r이 -1.0과 -0.7 사이이면, 강한 음적 선형관계,
r이 -0.7과 -0.3 사이이면, 뚜렷한 음적 선형관계,
r이 -0.3과 -0.1 사이이면, 약한 음적 선형관계,
r이 -0.1과 +0.1 사이이면, 거의 무시될 수 있는 선형관계,
r이 +0.1과 +0.3 사이이면, 약한 양적 선형관계,
r이 +0.3과 +0.7 사이이면, 뚜렷한 양적 선형관계,
r이 +0.7과 +1.0 사이이면, 강한 양적 선형관계 -
<절댓값 기준>
0.0~0.2 : very weak correlation (or negligible)
0.2~0.4 : weak correlation
0.4~0.6 : moderate correlation
0.6~0.8 : strong correlation
0.8~1.0 : very strong correlation=> 상황마다 판단해주어야, 암진단의 경우 0.1도 유의하게 판단해야 할 것
plt.figure(figsize=(20,20))
sns.heatmap(df.corr(), annot=True,
fmt=".2f", # 포맷은 소수점 두번째 자리까지 표시
cmap='coolwarm', # 반대되는 색깔
vmin=-1, vmax=1); # 범위를 직접 설정해서 직관적인 색깔로 변경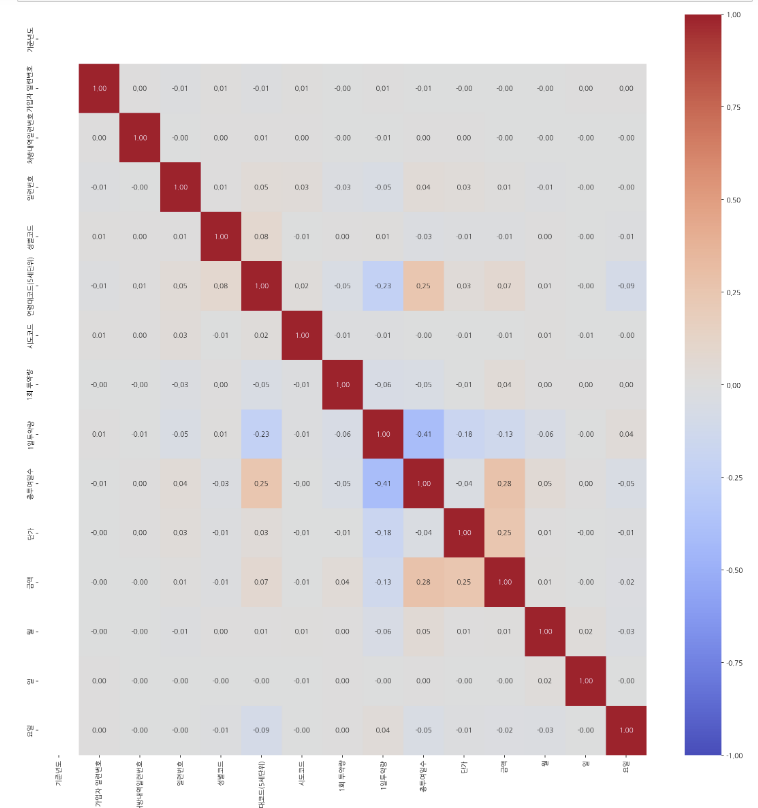
컬러맵 보기 plt.colormaps()
마스킹을 해서 반대쪽만 보이게 하기: 삼각행렬 실습
mask = np.triu(np.ones_like(corr))
# mask = np.tril(np.ones_like(corr))
plt.figure(figsize=(12,5))
sns.heatmap(corr, annot=True, fmt=".2f", cmap="coolwarm", vmin=-1, vmax=1, mask=mask)시각화
sns.countplot(data,x=) : 편리하다 - y축 안써도 알아서 나머지 축에 빈도수 나옴
x컬럼의 값별 행의 개수 구하는 barplot
- data=df.sort_values("요일") : 정렬 이렇게 해서 구현 가능
- order=age_dict.values() : 정리된 값이 있다면 order 옵션으로 구현도 가능
# 월별 처방 횟수를 시각화합니다.
plt.figure(figsize=(10,4))
sns.countplot(data=df, x="월")
# 판다스로 표현
df["월"].value_counts().plot.bar(figsize=(10,4), rot=0)
groupby, pivot_table로 데이터를 나눠 분석 가능
# df를 연령대로 나눈 다음, 합을 출력하겠습니다.
df.groupby(["연령대","성별"])["금액"].sum().unstack().plot.bar(figsize=(10,4), title="처방금액합계")
# 피봇테이블로 해보기
df.pivot_table(index=["연령대"], columns=["성별"], values=["금액"], aggfunc="sum").plot.bar(figsize=(10,4), title="연령대별 성별 금액 합계")
len(set(user_sample))
중복을 제외하고 유일값의 개수 셀 수 있다
