
대상의 특성을 수치로 표현하기
부분을 통해 전체를 추측하기
예측하기
영향력을 미치는 변수 찾기
관찰가능한 특성들을 바탕으로 관찰하기 어려운 특성을 지표화할 수 있음
주거지 추천 -> 주거지별 특징을 지수화
<통계를 이용한 일들>
• 대상의 특성을 수치로 표현하기
• 부분을 통해 전체를 추측하기
• 비교하기
• 예측하기
• 영향력을 미치는 변수 찾기
• 지수(index) 만들기
• 비슷한 것끼리 모으기
TIP! 평균을 냈을 때 말이 되나 => 연속형
말이 안 된다, 애매하다 => 범주형
ex. 경기도에 반쯤 산다
분위수 함수로 사분위수 구하기
df.price.quantile(.25) # 1사분위수
df.price.quantile(.5) # 2사분위수
df.price.quantile(.75) # 3사분위수
hr.overtime.quantile(.75)-hr.overtime.quantile(.25) # IQR
샘플링 = 표본 추출
- random samlping : 무작위 표집
일정한 확률에 따라 표본을 선택 - simple random sampling : 단순 무작위 표집
모든 사례를 동일 확률로 추출 - 계통 표집 목록의 매번 k번째 요소를 표본으로 선정 ex. 투표소에서 나오는 사람 7번째마다 설문
- 층화 표집 ex. 지역별, 연령별, 성별로 (계층별로) 무작위 추출
- 집락 표집 모집단을 집락으로 나눈 후 집락 중 일부를 무작위로 선택 ex. 같은 도시의 학교 중 일부를 무작위로 골라 그 학교의 학생들을 조사
추정
점추정
구간추정
- 신뢰구간
신뢰(신뢰로 이해하지 마라)수준이 높음 95 -> 더 넓은 오차범위 -> 정보가 적다
신뢰수준이 낮다 99 -> 더 좁은 오차범위 -> 정보가 많다
import pingouin as pg
pg.ttest(df.price, 0, confidence=0.95) # 평균의 95% 신뢰구간
95%의 경우 모집단이 신뢰수준에 들어간다
• 95% 신뢰구간 = 95%의 경우에 모수가 추정된 신뢰구간에 포함됨
bootstrapping 부트스트래핑 : 시뮬레이션 기법, 표본이 충분히 클 시
모집단이 아닌, 가지고 있는 데이터에서 데이터 뽑는 것 (표본에서 표본 다시 뽑기)
모집단도 비슷하게 생겼겠지~ 가정 하에
=> 결론: ex. 대충 그 범위가 +-40만원 정도 되더라
통계적 가설 검정 : 삐뚤어진 논리
<너무 이해 쏙쏙 예시!!!!!!!!>
혼내주고 싶은 사람 (후배) = 귀무가설 : 후배 좋은 사람
후배 맨날 어질러요
유심히 감시하면서.. 100점 만점에 5점도 못하면 혼내줘야지
드디어! 후배가 2점 받음
득달같이 나와서 니 이것도 못하냐!! 역시 너는 어지르는 사람 좋은 사람 아냐.
만약 그렇다고 80점 받아왔다? 그때 칭찬해주지는 않음... 에이 다음엔 못할거면서 오늘 날씨가 좋네~ (딴청, 의심, 못미덥)
싫어하는 사람 <- 기준에 못미치면(꼬투리가 잡혔다) 욕하기!!! 님 틀렸음
그렇다고 기준에 미친다고 좋아하니? 아님! 가설 검정은 삐뚤어진 논리 = 이 경우, 아무 결론도 내지 않음 유야무야
<아닌 것을 까는 게 목적>
기각 시 결론은 있다 : 얼마나 맞을지도 틀릴지도 모름, 그냥 기각
채택 시 결론은 없다
피어슨과 피셔
귀무가설 <-> 대립가설
주장 입증이 아니라
반대하는 가설을 세워놓고! 반박하는
귀무가설 기각 => 우리의 대립가설 채택
귀무가설: 설마 900만원은 아니겠지? (900만원이다)
유의수준 5%로 세우고
에이 그것도 못 넘겨!! 너는 아니다. 니는 가라.
통계적으로 유의 = 기각 => 900만원은 아니다
결론이 나온다 = 900만원은 아니다
귀무가설: 설마 800만원은 아니겠지?
p-value 한참 넘음
아 그렇구나.. 음 네 알겠습니다 흐지부지
기각 x => 오키오키 => 별 의미 없음
결론을 유보한다 = 900만원일 수도, 아닐 수도... (속마음: 아 못 혼내줬다)
가설 검정의 논리에는,
귀무가설 채택 = 와! 900만원! 대단하신 분이네요~ 이런 건 하지 않는다
채택하는 경우 없다. 결론 유보.
p 값
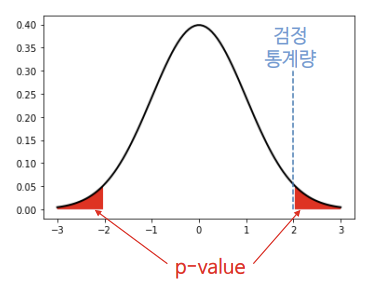
평균 = 900만원
853만원.... 나올 가능성이 있나? = p-value
2% 정도 나왔다
에이~ 아무리 그래도 5%는 나와야지, 기각!
p-값 < 유의수준(5%) => 귀무가설 기각
t-test
t라는 이름의 확률분포, 이 분포 이용해서 확률 이용
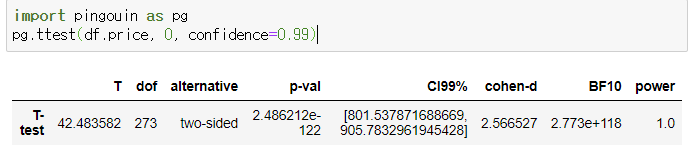
p-val: p-value
CI95% : 신뢰구간
cohen-d : 귀무가설과의 차이가 크다, 작다
가설 검정의 결과
제 1종 오류 : 참인 귀무가설 잘못해서 기각
제 2종 오류 : 거짓인 귀무가설 기각 못 함
930점, 870만점 나올 수 있는데.. 컨디션 안좋아서 853점 나올 수 있을까?
귀무가설 참일 때, 우리가 관찰한 결과가 나올 가능성 2% = 아주 낮다
기준은? 5%로 정해놓겠다 5%도 안 되면..
2% < 5% 이렇네!
에이 기각 해야겠다 853점 안나온다~
상관 분석 : 표 보는 법
두 변수의 연관성(상관계수)을 -1~+1 범위의 수치로 나타낸 것
관계가 있어, 없어? 무슨 관계야?
pg.corr(df.price, df.mileage)
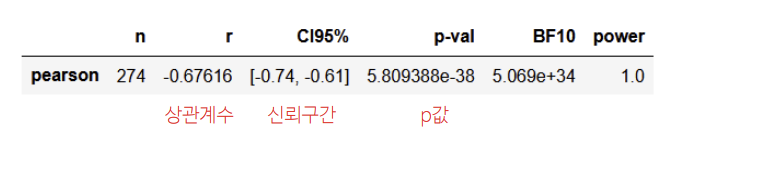
표본 상관계수 (r) : -0.67616 (-0.74, -0.61)
귀무가설 : 모상관계수 = 0.0 (p 값 <<<<<<< 0.05)
결론: 귀무가설 기각 (모상관계수 != 0)

표본상관계수 0.00795 (-0.11 ~ +0.13)
귀무가설 : 모상관계수 = 0 (p = 0.89)
귀무가설을 채택하는 법은 없음
결론: 결론 유보 (딱 0이라고 결론 못내림)
-0.1이 아니라는 법은 어딨냐?!
공분산
• X의 편차와 Y의 편차를 곱한 것의 평균 (X=Y이면 분산과 같음)
• 우상향하는 추세인 경우 +로 커짐
• 우하향 하는 추세인 경우 –로 커짐
회귀분석
from statsmodels.formula.api import ols
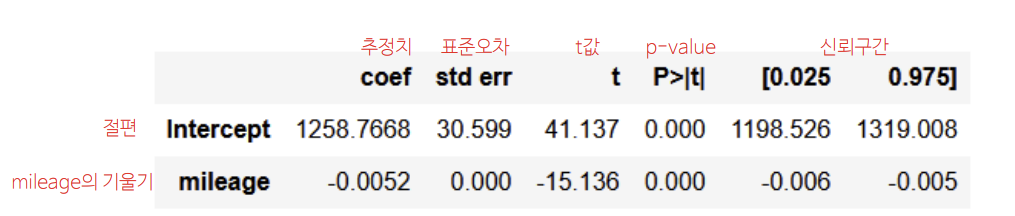
m = ols("price ~ mileage", data = df).fit()
m.summary()
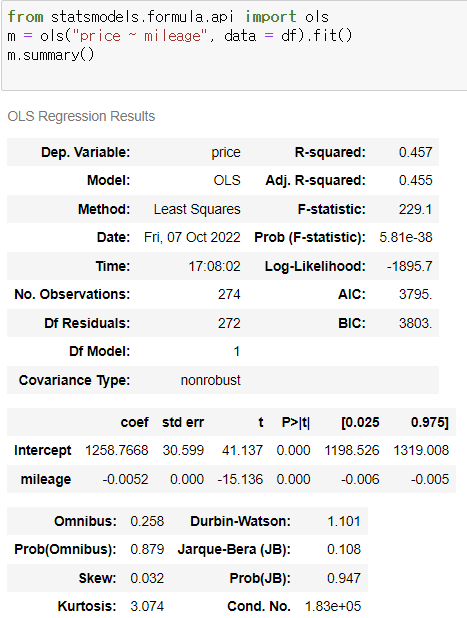
coef 추정치
milage milage의 기울기
p-value
절편은 가설검정 하지 않음
상관분석: 서로 관계가 있는가?
회귀분석: x와 y
ㄴ 공식을 찾는 게 회귀분석의 목적 = 본질
price(y) = -0.0052 * mileage(x) + 1258.7668
예측을 하려면 관련이 있기는 해야 함
예측이 잘 된다 = 뭔가 강한 관계가 있다는 것도 미루어 알 수 있음
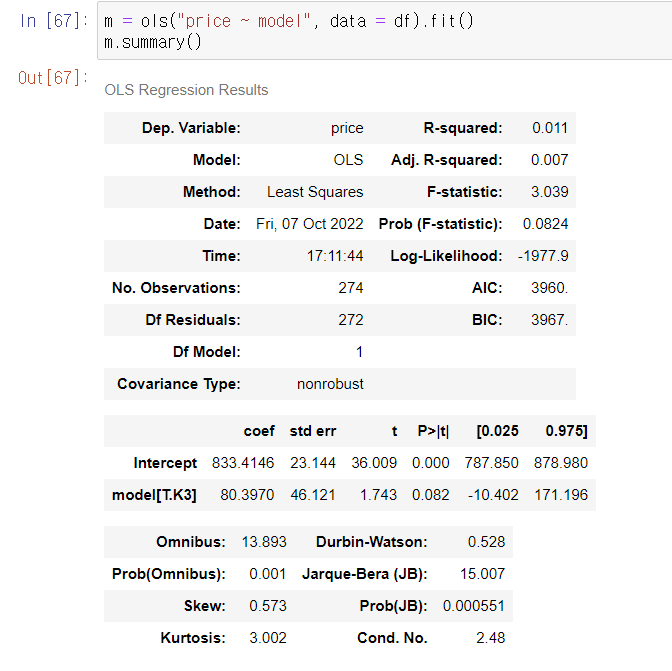
더미 코딩 : 범주형 변수
문제: 아벤테x3 할 수가 없음
따라서, 곱하거나 더할 수 있는 형태로 바꿔준다
= 변수 하나를 새로 만듦!
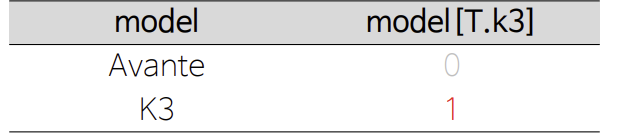
x = 0 # AVANTE
80.3970 * x +833.4146(아반테 평균 가격)
=> 833.4146
x = 1 # K3
80.3970 * x +833.4146(아반테 평균 가격)
=> 913.8116
알아서 되기 때문에 해석만 할 줄 알면 됨.
결론: 둘사이에 차이가 없다(기울기 0) 기각/기각 x
Q.데이터 많아야 하는가?
결론이 나면, 충분히 지지할 수 있다면 그게 충분한 것.
데이터가 많고 적은 절대적 값은 없다.
다중 회귀 분석
year 한 개만 보면 106만원이 연식 하나 때문에 변화된 것인지 알기가 어렵다
겹쳐 있던 부분이 떨어져나감
기울이 줄어든다
m = ols("price ~ year + mileage + model", data = df).fit()
m.summary()model(차종), mileage(주행거리), year(연식)
차종 또한 연식과 관련이 있고 주행거리 또한 연식과 관련있어서
겹치는 부분을 떼어내준다
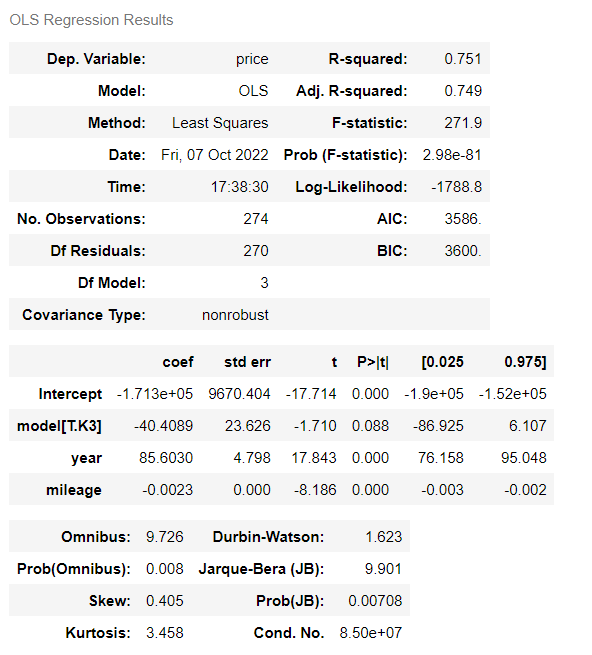
modelK3 = 1
year = 2015
mileage = 50000
price = -1.713e+05 + modelK3 -40.4089 + year 85.6030 + mileage * -0.0023
공식에 대입하면 차량 가격을 산출할 수 있게 된다
# 다른 예시
# rating을 marriage와 overtime 예측하는 회귀분석을 해보세요
hr = pd.read_excel('hr.xlsx')
hr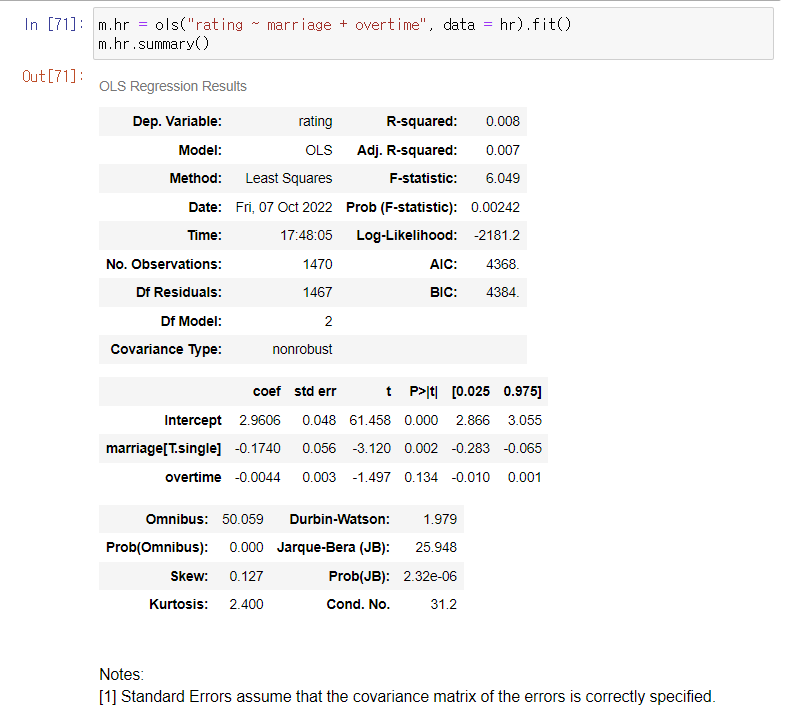
overtime의 기울기 p값 커서, 결론 내릴 수 없다
싱글의 기울기 p값 작아서, 음의 기울기(-) 맞다
따라서, 싱글보다 married가 더 높겠다
